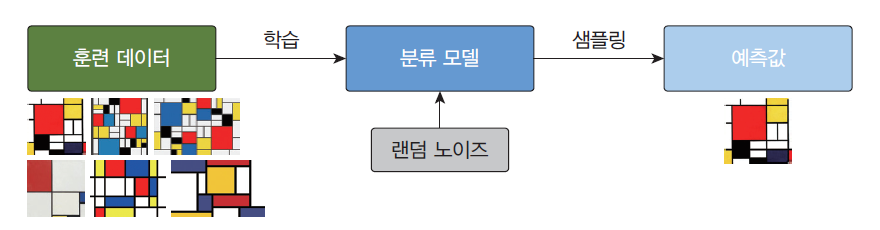
생성 모델이란?🤔
생성 모델(generative model)은 훈련 데이터의 규칙성 또는 패턴을 자동으로 발견하고 학습하여, 훈련 데이터의 확률 분포와 유사하지만, 새로운 샘플을 생성하는 신경망이다.
생성 모델은 훈련 데이터들의 잠재 공간 표현을 학습할 수 있으며, 학습 종료 후에, 잠재 공간에서 랜덤으로 하나의 좌표가 입력되면 거기에 대응되는 출력을 만들어 낼 수 있다.
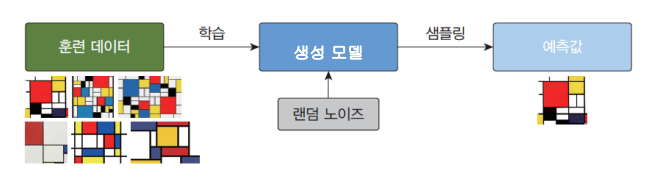
또한 생성 모델은 결정적이기보다는 확률적이어야 한다.
사실 당연하다. 생성을 할 때 고정된 계산으로 생성한다면 항상 똑같은 출력을 하게 될 것이다.
따라서 위 그림처럼 랜덤 노이즈가 필수적이다.
대표적인 생성모델 종류에는 기본적 AUTO ENCODER와 GAN이 있다.
기본적 AUTO ENCODER
기본적 auto encoder는 입력과 동일한 출력을 만드는 것을 목적으로 하는 신경망이다. 특징 학습, 차원 축소, 표현 학습 등에 많이 사용된다.
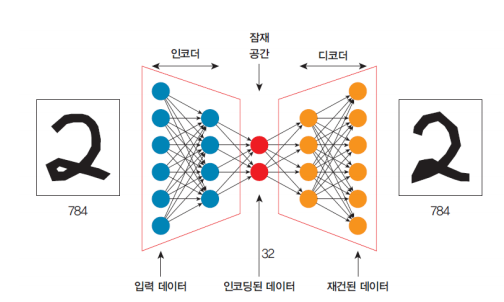
인코더(encoder): 입력을 잠재 표현으로 인코딩한다.
디코더(decoder): 잠재 표현을 풀어서 입력을 복원한다.(복원값은 인코더와 다름)
이외에도 많은 종류의 auto encoder가 있다.
Sparse Autoencoder
활성화 함수에 sparsity 제약을 추가하여, 적은 수의 뉴런만을 활성화시키는 특징을 갖는다. 이를 통해 더욱 중요한 특징을 학습하도록 유도한다.
sparsity 제약이란?
모델이 학습하는 특징(feature)의 수를 제한하는 것
Deep Autoencoder
여러 개의 은닉층을 가진 신경망을 사용하여, 더 복잡한 특징을 학습할 수 있다.
Variational Autoencoder, VAE
인코더가 데이터의 확률적인 잠재 표현을 학습하고, 디코더가 이 잠재 표현에서 샘플링하여 데이터를 생성한다.
Contractive Autoencoder, CAE
입력 데이터 주변의 작은 변화에 대해 더욱 민감하지 않도록 학습하는 오토인코더이다. 이는 모델이 더 안정적인 특징을 학습하도록 돕는다.
Denoising Autoencoder
입력 데이터에 의도적으로 노이즈를 추가한 후, 이를 제거하면서 원본 데이터를 복원하도록 학습한다. 이 과정을 통해 모델은 데이터의 중요한 특징을 더 잘 파악할 수 있다.
Convolutional Autoencoder
이미지와 같은 격자 형태의 데이터에 대해 효과적인 컨볼루셔널 신경망을 사용한다. 이는 이미지의 공간적 계층 구조를 이용하여 특징을 학습한다.
Recurrent Autoencoder
시계열 데이터나 텍스트와 같은 순차적 데이터를 처리하기 위해 순환 신경망(RNN)을 사용한다.
Sequence-to-Sequence Autoencoder
입력 시퀀스를 압축한 후, 이를 다시 시퀀스로 복원한다.
주로 자연어 처리(NLP) 분야에서 사용된다.
Adversarial Autoencoder
GAN의 개념을 오토인코더에 적용하여, 인코더가 생성한 잠재 표현이 특정한 분포를 따르도록 한다.
GAN(Generative adversarial network)
이 모델에서는 생성자 신경망과 판별자 신경망이 서로 적대적으로 경쟁하면서,
훈련을 통하여 자신의 작업을 점점 정교하게 수행한다.
GAN의 구조
생성자(generator): 가짜 데이터를 생성하는 것을 학습한다. 생성된 데이터는 판별자를 위한 학습 예제가 된다.
판별자(discriminator): 생성자의 가짜 데이터를 진짜 데이터와 구분하는 방법을 학습한다. 판별자는 생성자가 유사하지 않은 데이터를 생성하면 불이익을 준다.
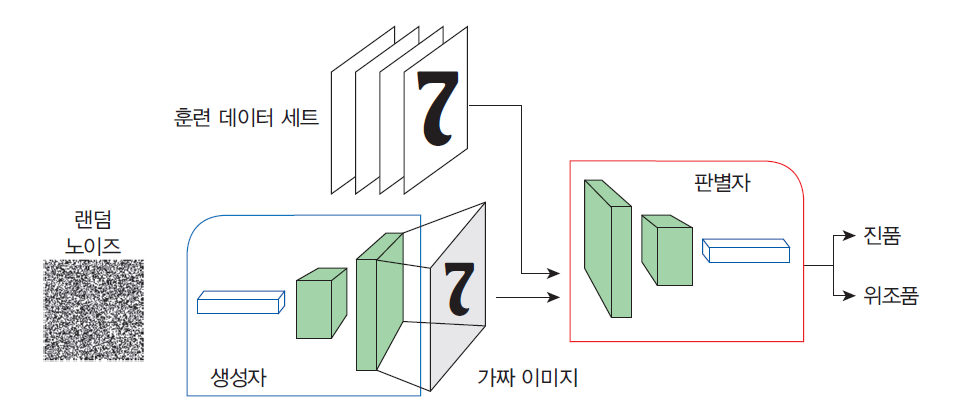
GAN 훈련 과정
-
판별자 훈련과 생성자 훈련이 번갈아 가며 수행된다.
-
GAN 훈련이 시작될 때 생성자는 아직 무엇을 만들어야 하는지 전혀 알지 못한다. 따라서 입력으로 임의의 노이즈가 공급되며, 생성자는 출력으로 임의의 노이즈 이미지를 생성한다.
-
이러한 저품질 가짜 이미지는 진짜 이미지와 극명하게 대조되므로, 판별자는 처음에 진짜와 가짜를 판별하는 데 전혀 문제가 없다. 그러나 생성자가 훈련되면서 진짜 이미지의 일부 구조를 복제하는 방법을 점차적으로 학습한다.
-
생성자가 더 진짜같은 가짜 이미지를 만들수록 판별자 역시 판별 성능이 향상된다.
