
지난번 velog 첫 포스트 Paper review - YOLOv1에 이어 바로 YOLO v2에 대한 리뷰를 진행하겠습니다.
Introduction

Fig 1. Limitations of YOLO v1.
먼저 지난 포스트의 말미에 YOLOv1의 단점들에 대해서 언급을 했는데, 1년이 지난 CVPR '17에서 필자가 이를 해결하고자 시도한 YOLO v2를 발표했습니다. 특히 필자는 recall을 increase하고, localization error를 decrease 하는 방법을 강구했습니다. 가장 널리 알려진 방법은 network의 크기를 키우는 것(scaling-up)이지만, 필자는 이 방식이 아니라, 되려 network는 simplify하고 학습이 더 쉬워지도록 하고자 했습니다.
👌 recall이 뭐였지 하시는 분을 위한, 숨니님의 블로그
Better

Fig 2. Efforts to Solve Problems of YOLO v1
따라서 다음의 Fig 2와 같은 여러가지 방식을 사용했는데 간단히 넘어갈 수 있는 것은 간략하게 넘어가며 하나씩 살펴보도록 하겠습니다.
Batch Normalization
먼저 등장하는 것이 바로 Batch Normalization입니다. Batch Normalization에 대하여 잘 모르시는 분은 꾸준희님의 Batch Normalization 정리를 참고하시면 좋을 것 같습니다. 굉장히 쉽게 설명이 잘 되어 있습니다. 필자는 이 방식을 사용하여 mAP를 2% 넘게 향상할 수 있었다고 합니다.
👌 mAP가 뭐였지 하시는 분을 위한 Developer님의 블로그
High Resolution Classifier
YOLO v1과 같은 경우는 224x224의 image로 pre-training을 했습니다. 하지만, 아시다시피 입력 image는 448x448이었죠. 따라서 YOLO는 high-resolution에 적응하는(adjust) 추가적인 작업이 필요했습니다. 따라서 이를 해결하고자, 시작부터 448x448의 image를 가지고 학습을 수행했고, 이 결과 4%의 mAP 상승을 이뤄냈습니다.
Convolutional With Anchor Box
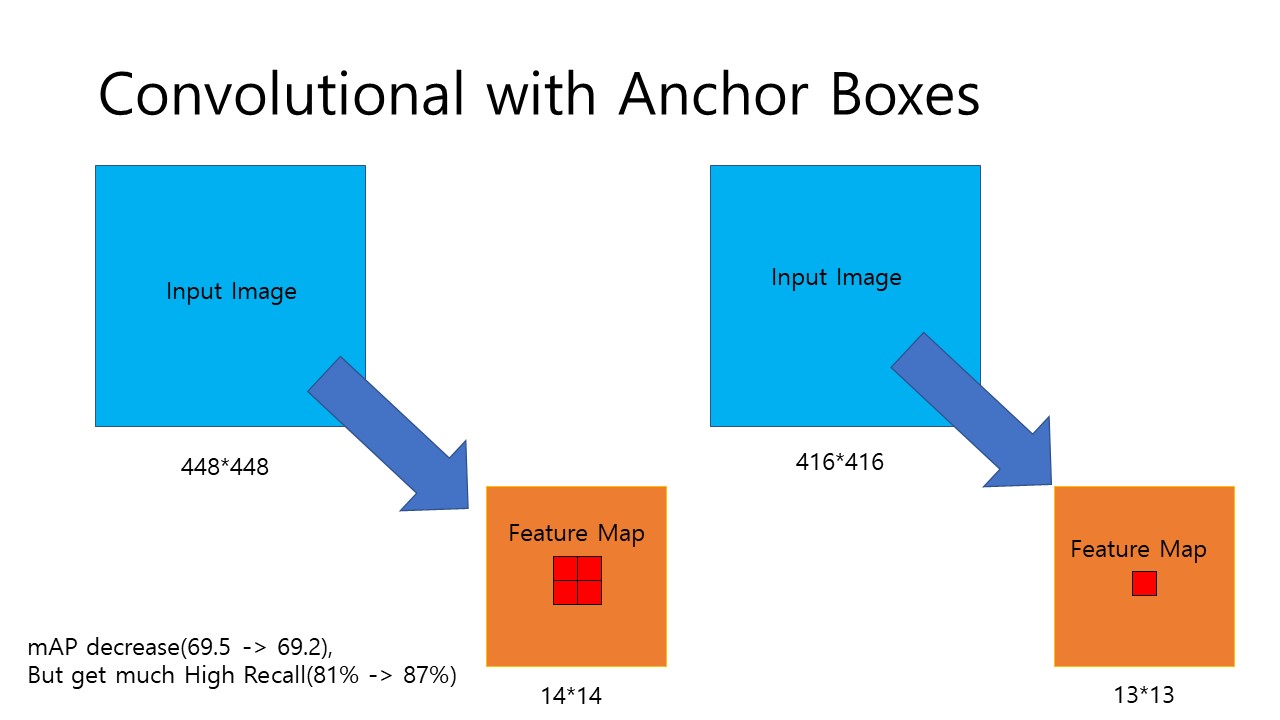
Fig 3. Convolutional With Anchor Box
앞서 YOLO v1을 생각해보면 bbox의 5가지 prediction 중에 x,y,w,h의 값은 0~1 사이의 값을 가졌습니다. 또한 YOLO는 x,y값을 적당히 랜덤하게 예측해서 학습을 시작했었죠. 이는 초기에 model이 unstable하다는 문제점을 가지고 있었고, 복잡했습니다. 따라서 필자는 Fast-R-CNN (YOLO가 끝나는 대로 R-CNN도 순차적으로 업로드 하겠습니다.)에서 사용한 방식인 Anchor-box를 통한 offset 예측을 시도했습니다. 이 방식을 거치면 network가 훨씬 간단하고 계산에도 무리가 없기 때문입니다. 이를 위해 필자는 2가지의 작업을 해주었습니다.
- Eliminate one pooling layer to make output
- Using 416x416 input image
1번 작업의 경우 출력을 고해상도로 만들어주는 작업이고 우리가 살펴볼 부분은 바로 2번째 작업입니다. 앞서 High Resolution Classifier 단계에서 448x448이던 input image를 416x416으로 network를 줄여 수정하는 이유는 Fig 3을 통해 알 수 있습니다.
YOLO는 1/32의 downsample ratio를 가지는데, 448x448의 경우 이 과정을 거치면 14x14의 Feature Map을 가지게 됩니다. 중간에 4개의 grid cell이 뭉쳐있는 것을 확인할 수 있습니다. 하지만, 416x416의 경우 feature map의 size가 13x13으로 중간에 하나의 grid cell이 남는것을 확인할 수 있습니다. 보통 이미지를 처리할때 중간에 object가 있을 확률이 높으므로 이렇게 홀수 크기의 feature map을 얻는 것이 유리합니다.
또한, YOLOv1의 경우 98개의 bbox를 보유하지만, v2의 경우에는 anchor box를 사용하기 때문에 보다 많은 bbox를 보유하게 됩니다.(필자는 more than a thousand라고 말했습니다.)
이렇게 anchor box를 사용한 접근은 mAP를 낮추지만, Recall을 상당히 올려주어 이 network가 발전할 가능성이 충분함을 보여주었습니다. 여기서 Recall이 어떤 의미가 있냐, 위의 블로그에 다녀오시면 이해가 편하실텐데요. 높은 Recall은 이 모델이 실제 객체의 위치를 예측한 비가 높아졌다는 것을 의미합니다.
Dimension Clusters
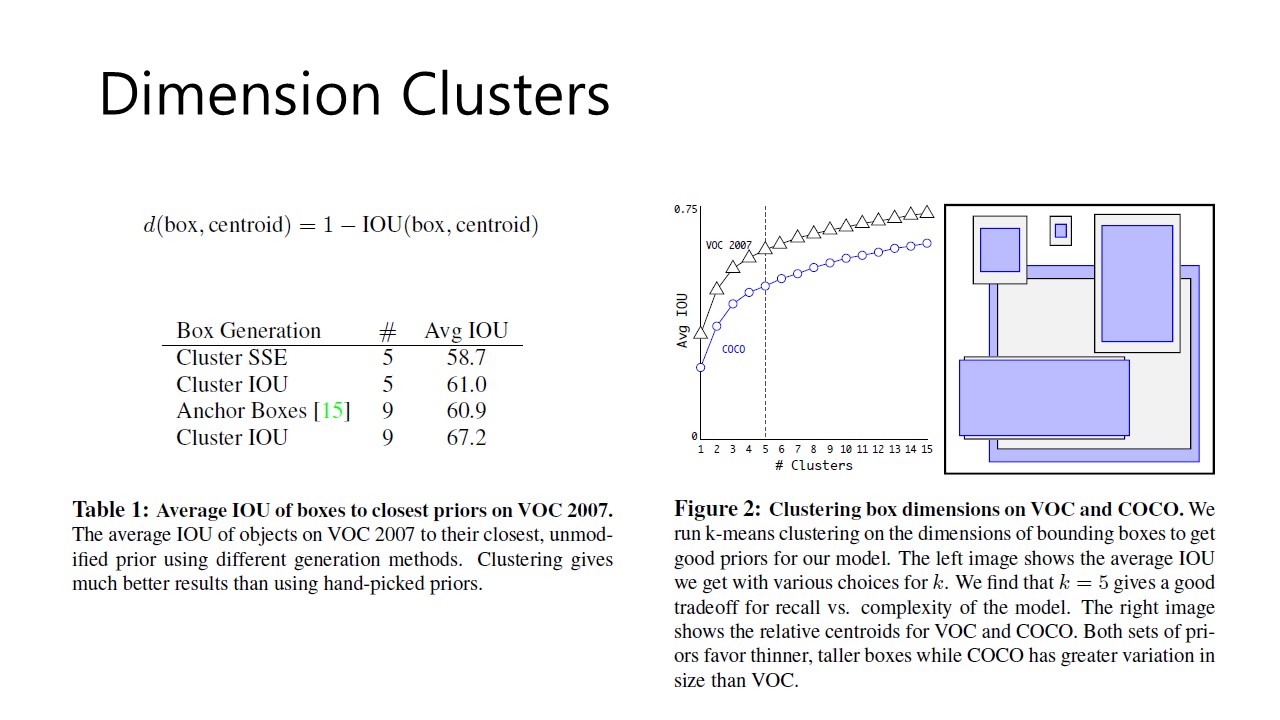
Fig 4. Dimension Clusters
다음으로 살펴볼 내용은 Dimension Clustering입니다. Anchor box를 사용하게 되면서 2가지 issue와 마주하게 되는데, 아래와 같습니다.
- Box dimensions are hand-picked
- Model instability
그 중 첫번째 Box dimensions의 hand-picked 되던 값을 이제 우리 model이 better prior를 pick하게 하는 것이 첫번째 해결방안이고 이를 위해 필자가 사용한 idea가 dimension clustering입니다. 필자는 k-meanss clustering 방식을 사용했는데요. k-means clustering에 대해 조금 더 자세히 정리해둔 Dr. Michal J. Garbade님의 글을 참고하시면 이해에 도움이 될 것입니다. Fig 4 내의 Figure 2를 참고하시면 필자는 k = 5의 값을 선택하여 clustering을 진행했다고 합니다.
또한, 필자가 적용한 k-means clustering은 일반적으로 알고 있는 k-means clustering과는 차이가 있는데, 바로 Euclidean distance를 사용하지 않았다는 점입니다. 만일 Euclidean distance를 사용하게 된다면, 큰 박스가 작은 박스에 비해 더 많은 error를 일으키게 되는데, YOLO algorithm에서 저희가 원하는 것은 필자가 아래와 같이 서술한
priors that lead to good IOU scores
와 같이 box size에 독립적인(independent) IOU score에 초점을 맞추기 때문입니다.
👌 Euclidean distance의 정의 - wikipedia
따라서 본 clustering에서는 위의 Fig 4의 식을 distance metric으로 사용했습니다. 식을 살펴보면, box와 centroid의 IOU가 클수록 거리가 가깝다는 것을 알 수 있습니다. 따라서 이런 clustering의 효과를 보여주는 것이 Table 1입니다. Cluster IOU #5일때 Avg IOU가 61.0의 값을 가지고, Anchor Boxes가 #9일때 Avg IOU가 60.9인것을 볼 수 있습니다. 즉 better prior는 오직 5개의 anchor box만으로도 좋은 효율을 나타낸다는 것 입니다.
Direct Location Prediction
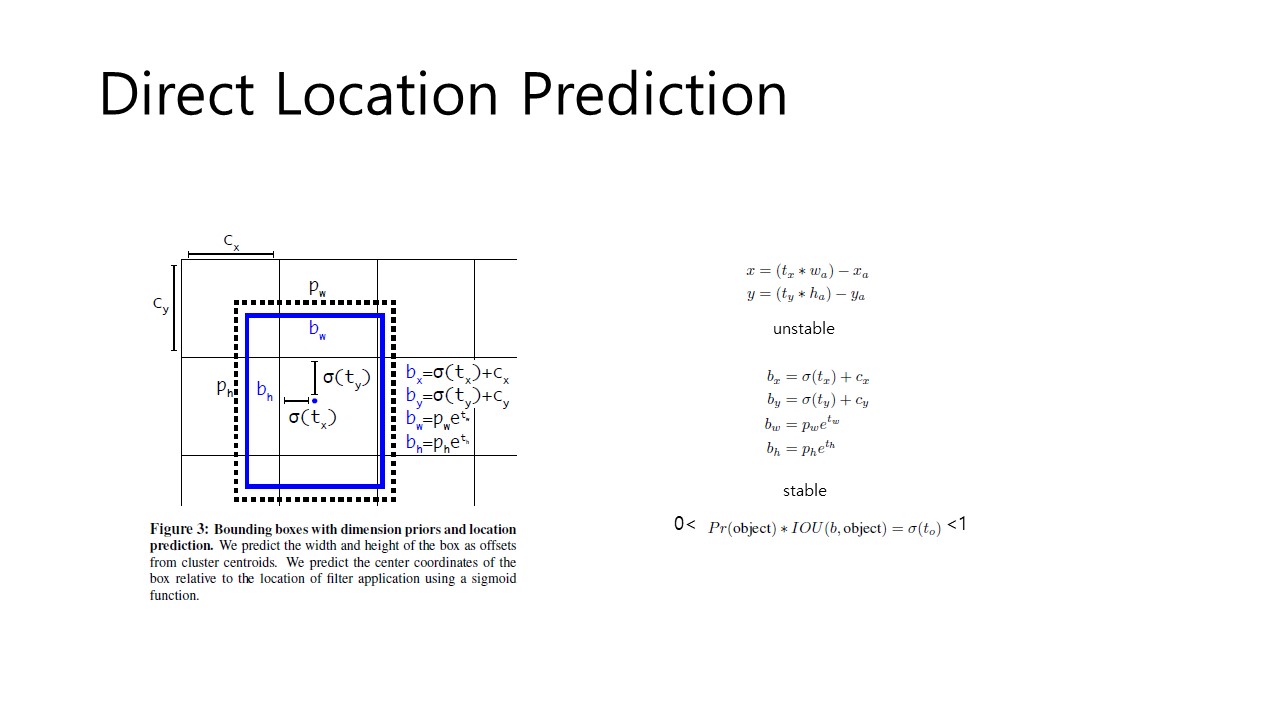
Fig 5. Direct Location Prediction
이제 앞서 말한 두번째 issue인 model instability를 해결하는 방법을 서술하겠습니다. Anchor box를 사용하는 것이 초기 iteration에서 특히 model instability를 일으킨다고 합니다. 대부분의 문제는 (x,y)를 예측하는데서 오는데요. Region Proposal network에서는 (위의 Fig 5의 우측 상단의 식을 봐주시면 됩니다.) 값을 예측하여 사용하고 이를 바탕으로 (x, y)를 계산합니다. 따라서 인 경우에는 box를 anchor box의 width만큼 우측으로 이동시키는 것입니다.
하지만, 이런 formula는 값이 제한된 범위가 없어, 초기에 최적화된 값을 찾는데 어려움이 있습니다. 따라서 sensible한 offset을 예측하는데도 시간이 오래 소요됩니다. 따라서 이를 해결하기 위해, YOLO는 location coordinates를 grid cell의 location에 상관있게(relative) 예측하게 됩니다. 이렇게하면 bbox의 값이 0~1의 사이의 값을 가지게 됩니다.(YOLOv1에서 4개의 prediction을 하는 방식과 동일합니다.) Logistic activation을 사용해서 0~1의 사이의 범위를 가지게 합니다.(이를 나타낸 식이 Fig 5의 우측 중간부 식입니다.) 즉 로 의 값의 범위를 한정하는 것입니다. 따라서 모델은 안정적인 학습이 가능합니다.
각 network는 5개의 bbox를 각 grid cell마다 예측하고, 따라서 총 5x(20+5)=125 filter가 사용됩니다. 이 방식을 사용해서 5%의 recall 향상을 얻을 수 있습니다.
Fine-Grained Features
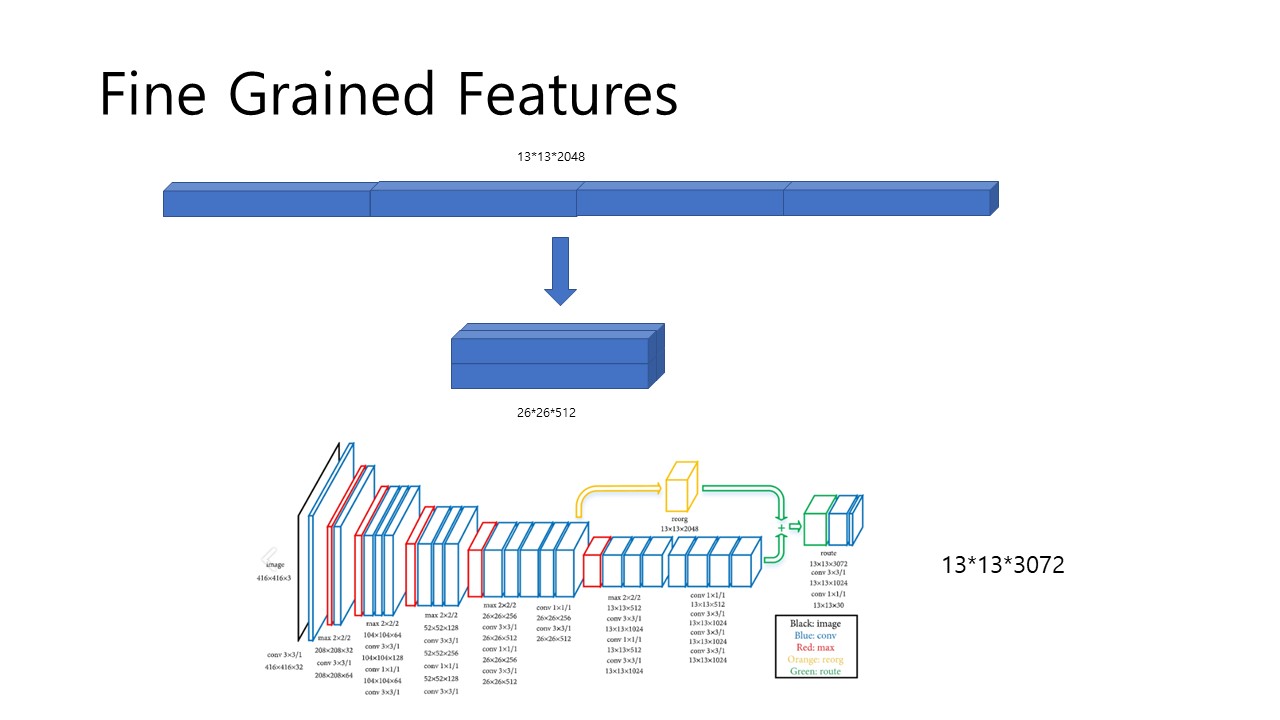
Fig 6. Fine Grained Features
앞서 YOLOv2는 13x13 size의 feature map을 얻는다고 했습니다. Feature Map의 size가 작은경우 큰 object의 detection은 용이하지만, 작은 object는 어렵다는 단점이 있습니다. 이를 해결하기 위해 Faster R-CNN과 SSD에서 사용한 방식과는 다른 접근으로 YOLOv2를 설계했는데,
adding a pass through layer that brings features from an earlier layer at 26x26 resolution.
으로, 위의 Fig 6에서 볼 수 있듯, 13x13x1024 size의 feature map을 얻기 이전에 26x26x512의 feature map을 미리 추출합니다. 그리고 이를 13x13x2048의 feature map으로 연결하고 이를 연결해 결과적으로 13x13x3072의 feature map을 얻고, 이를 1x1 및 3x3 convolution layer를 거쳐 13x13x125의 feature map으로 완성합니다. 여기서 125인 이유는 바로 위에 서술해두었습니다.(5x(5+20)) 이 방식을 사용하는 이유는 26x26x512의 feature map은 higher resolution feature를 지니고 있고 이를 low resolution feature에 쌓아 작은 개체에 대해서도 예측이 용이하게 설계한 것입니다. 이 방식을 통해 1%의 performance increase를 얻었습니다.
👌 Fig 6에 첨부된 YOLOv2 Structure Diagram 및 추가 설명
Multi-Scale Training
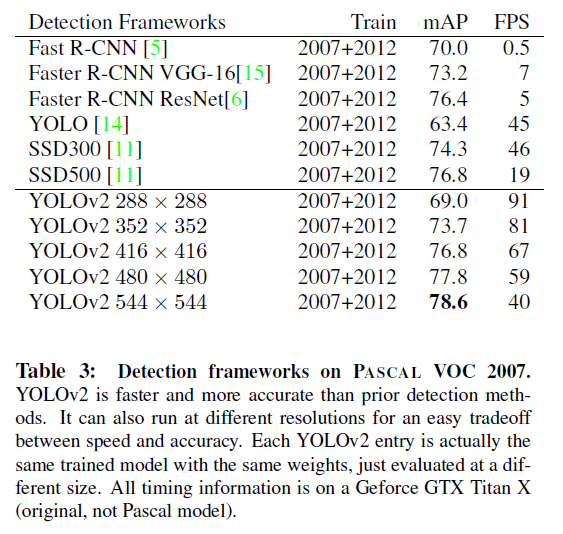
마지막으로 필자는 YOLOv2의 추가적인 학습을 통해 model의 완성도를 높였습니다. YOLO의 downsample ratio가 1/32이므로 320x320부터 608x608까지의 이미지를 학습시켰고 따라서 다양한 size를 입력받을 수 있습니다. 위의 Table 3를 참고하면 낮은 resolution에서는 높은 FPS와 상대적으로 낮은 mAP를, 높은 resolution에서는 낮은 FPS와 높은 mAP를 보입니다. (Easy Trade-off between speed and accuracy) 그리고 YOLOv2의 성능이 가장 뛰어납니다.
Faster
필자는 accurate하고 fast한 두 needs를 YOLO가 모두 충족하기를 원합니다. 그 당시에는 자율주행과 같은 robotics는 low-latency prediction에 의존하고 있었습니다. 당시에 주로 사용하던 VGG-16은 정확하지만, 너무 복잡하다는 단점이 있었습니다. 224x224 size image를 1회 처리하는데 30.69 billion floating point operation이 필요했기 때문입니다. YOLO v1이 사용한 GoogLe Net Architecture 또한 8.52 billion operation를 사용해 VGG-16보다는 비교적 빨랐지만, accuracy 측면에서는 취약한 모습을 나타냈습니다.
Darknet-19
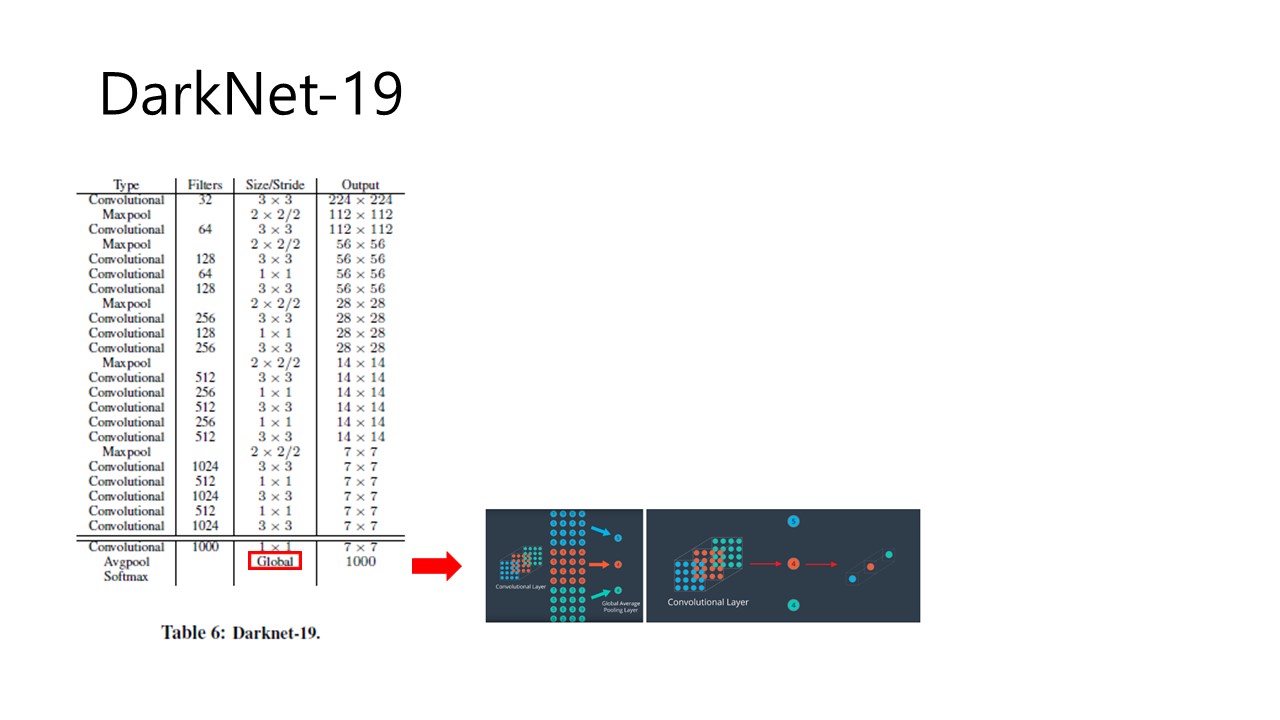
Fig 7. Darknet-19
따라서 필자는 YOLOv2를 위한 새로운 backbone architecture를 고안했습니다. Darknet-19는 VGG-16과 비슷하게 3x3 filter를 주로 사용하면서 Network in Network(NIN)과 유사하게 global average pooling layer를 사용했습니다. Global average pooling layer를 사용하는 이유는 YOLOv1에서 사용한 FC(Fully-connected)는 parameter가 크게 증가하여 속도가 굉장히 느려지는 단점이 있어 이를 해결하기 위함입니다. 위의 Fig 7의 우측이 Global pooling layer에 대한 이미지 자료입니다.
👌 Global Average Pooling에 대해 정리한 Jinsol Kim님의 Github.io
따라서 Darknet-19는 19개의 convolutional layer와 5개의 maxpooling layer로 구성되어 있습니다. 그리고 Darknet-19는 5.58 billion operations이 필요해 operation 수를 굉장히 줄였지만, top-5 accuracy에서 91.2%, top-1 accuracy에서 72.9% accuracy로 좋은 성능을 보였습니다.
Stronger
Hierarchical Classification
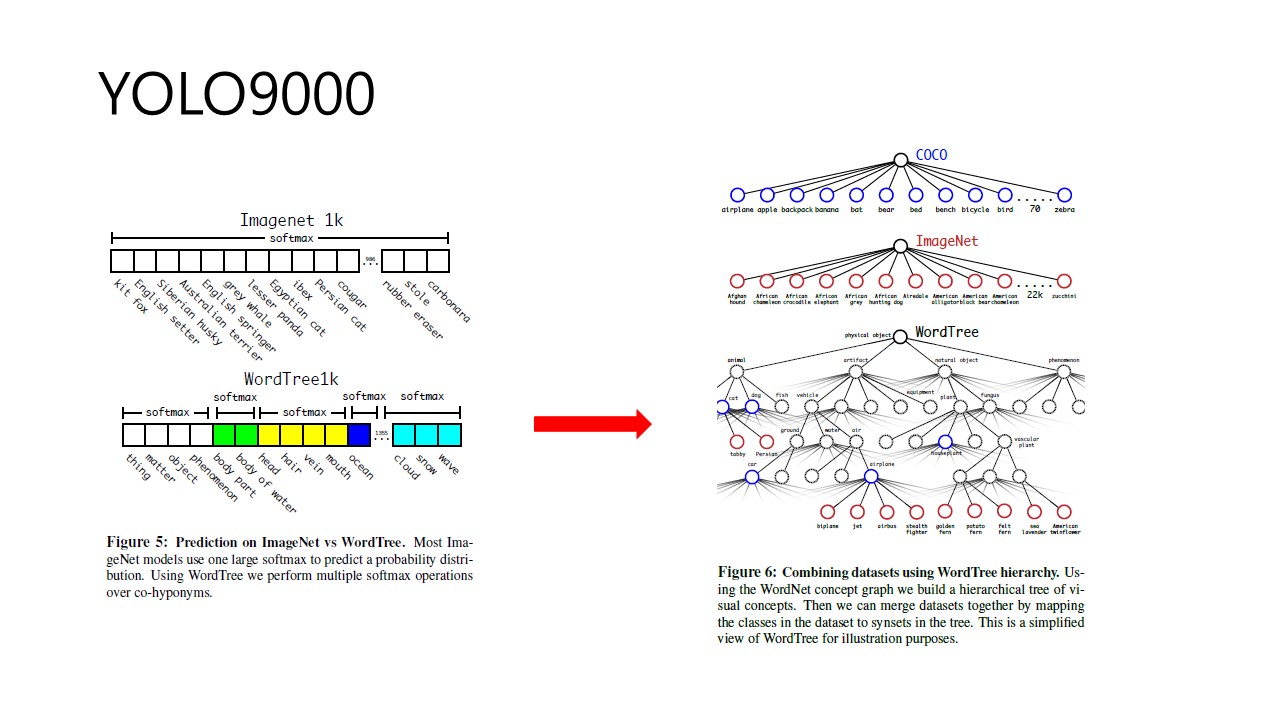
Fig 8. YOLO9000 - WordTree
필자는 YOLOv2에 classification data와 detection data를 동시에 학습시켜 보다 많은 class를 가지는 YOLO9000을 소개합니다. 여기서 joint training을 사용해 새로운 mechanism을 소개합니다. 여기서 필자가 부딪힌 난관은 detection dataset은 general label을 지니고, classification label은 deeper, wider한 range를 가진다는 것입니다. 예를 들어, detection label은 모든 개를 dog로 labeling하지만, classification label은 더 세세하게 Yokshire Terrior, Bedlingtion terrior와 같이 세부적으로 labeling을 하여 이 둘을 같이 학습시킬 경우 dog와 terrior를 다른 class로 인식하게 됩니다. 따라서 이를 해결하기 위해 제안한 방식이 Tree구조 입니다. Parents Node와 Child Node가 있기 때문에, 계층적으로 분류해 내려가면 된다는 것이 주된 idea입니다.(Hierarchical classification)

Fig 9. Norfolk Terrior를 찾아가는 과정
따라서 각 세부 객체를 범주를 점차 낮춰가면서 조건부확률의 좁을 통해서 연산할 수 있습니다. 이렇게 ImageNet을 통해 WordTree를 구성할 경우 1369개의 Node가 존재한다고 합니다. 이 방식을 사용하여 얻은 장점을 필자는 다음과 같이 말했습니다.
Our accuracy only drops marginally.
Performace degrades gracefully on new or unknown objects categories.
따라서 Fig 8의 우측 Tree 구조와 같이 COCO와 ImageNet을 합친 WordTree 구조를 만들었는데 여기서 ImageNet : COCO = 4:1로 joint model을 구축했습니다. 따라서 이렇게 구성한 WordTree는 총 9418의 classes를 가진다고 합니다.
Loss Function of YOLOv2

Fig 10. Loss Function of YOLOv2
본 논문에서는 Loss function에 대해 상세히 기술되어 있지는 않으나, 구글링을 통해서 다른 분들이 정리해둔 것을 통해 알 수 있었습니다. 전반적인 내용은 YOLOv1의 Loss function과 비슷하게 SSE를 사용한 것이 보입니다.
하지만, 조금의 차이도 있는데요. YOLOv1의 Loss Function과 비교하시면 더 좋을 것 같습니다. Part 1에 no_responsible_obj에 관한 Loss를 계산해주면서 새로운 weight parameter가 추가된 것을 볼 수 있습니다. 두번째 항이 추가된 이유는 바로 불필요한 연산을 줄이기 위해 학습시키는 것입니다. 보다 자세한 내용은 Reference를 참고해주시면 이해에 도움이 될 것 같습니다.
👌 Reference 1. Loss Function of YOLOv2
Result
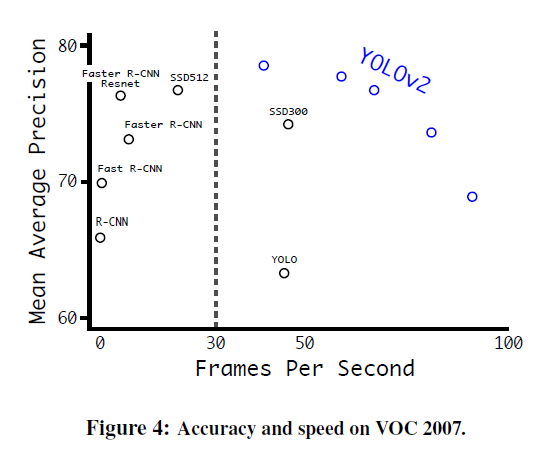
따라서 위의 trade-off 관계를 보여주는 결과와 같이 본인이 필요한 상황에 맞춰 적절한 size의 image를 선택해 YOLOv2를 사용하면 보다 빠르고 정확한 detection이 가능합니다.
Comments
본 YOLOv2에 대해 학습하면서, 기존의 issue들을 해결하는데, 이미 이전에 발표된 내용 (Batch Normalization 등)에 적절한 변형을 해서 해결하는 것이 놀라웠습니다. 또한, Darknet-19와 WordTree 개념도 본인의 문제를 해결하기 위해 기존에 발표된 것을 조화시켜 구현한 Architecture입니다. 사실 이 논문이 발표된지 몇 년이 지난 지금 수많은 source code들이 공개되어 있어서, 더 이상 코드를 구현하고 단순히 실행하는 것은 더이상 문제가 아닙니다. 하지만, 연구자들은 단순한 개발이 목적이 아니라, 조금 더 각 상황에 맞는 architecture에 대한 고민과 탐구가 필요합니다.
(지금 제가 밑에서 수학하고 있는 교수님의 조언입니다..ㅎ)
스타트업에서 단순히 소스코드로 기술을 구현하는 것이 아니라 근원적인 내용에 대해 탐구하는 것이 중요하다는 것을 느끼면서 Paper Review를 하고 있는 중 입니다.
References
✔ YOLOv2 Paper
✔ YOLOv2 Paper Review by herbwood
✔ YOLOv2 Paper Review by deep-learing-study
참고한 Reference들에 미처 다루지 못한 내용들이 있으니 각 part 별로 자세히 읽어보시면 좋을 것 같습니다.
p.s. YOLOv3에 대한 Post도 여기에 하려했는데, 생각보다 YOLOv2의 내용이 방대하여 좀 짧은 post가 될 것 같지만 다음 post에 서술하도록 하겠습니다.
긴 글 읽어주셔서 감사합니다.😊😊

