Introduction
첫 시리즈로 Object Detection의 가장 대표적인 YOLO(You Only Look Once)의 v1부터 v3까지의 Paper review를 진행합니다. 본 포스트는 그 중 v1에 관한 내용입니다. YOLO로 시작한 이유는 현재 Internship 중인 스타트업(ABrain) 및 랩실에서 이번에 진행하는 과제에 YOLOv5를 사용하여, 미리 개념을 알아두어야 하기 때문에 첫 번째 리뷰로 선정했습니다.
첨부하는 이미지 파일은 Seminar 용으로 제가 제작한 PPT 파일이고, 내부에 첨부된 파일 등은 Reference(✔)를 참고해주세요!
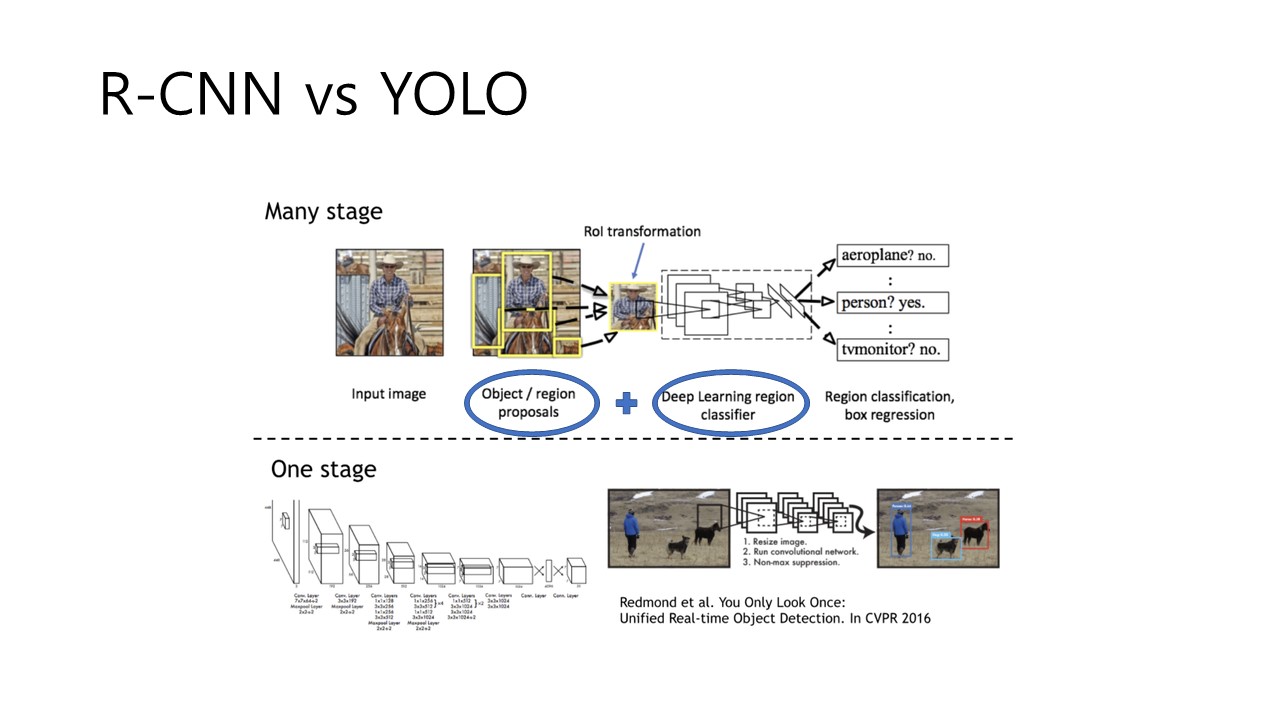
기존에 Object Detection의 분야에서 선두로 달리고 있는 방법은 R-CNN이었습니다. R-CNN은 UC Berkeley의 Ross Girshick에 의해 처음 소개된 object detection 방법으로 대표적인 2-stage detection 방법입니다.
이런 2-Stage 방법은 우선 Localization -> Classification의 과정으로 분류되며, 위의 그림에서 보이는 것과 같이, Region Proposals, Region Classifier 의 단계들을 확인할 수 있습니다. 이런 방식은 장점은 비교적 아주 정확한 결과를 도출한다는 점인데요. 다만 bottleneck (병목현상)이 일어날 가능성이 있어서 느리다는 단점이 있습니다.
✔ Localization lecture by Andew Ng
YOLO는 정확하지만 느린 R-CNN을 빠르게 하면서 보다 간편하게 하고자 하는 idea에서 시작되었습니다. 즉, '왜 우리는 두 단계 혹은 여러 단계로 나눠서 인식을 하는걸까..? 한번에 해보자!' 라는 생각인 것입니다. 따라서 이러한 object detection 방식을 이제 1-stage detection이라 부르며, Object detection의 양대 산맥으로 자리하고 있습니다. 위의 Fig 1의 아래 그림이 바로 YOLO에 관한 내용인데 필자는 YOLO를 이렇게 소개하고 있습니다.
YOLO is refreshingly simple!
이런 YOLO의 장점으로는
- YOLO is EXTREMELY FAST
- YOLO reasons globally about the image when making prediction.
- YOLO learns generalizable representations of objects
의 세가지가 있습니다.
Methods and key-concepts of YOLO
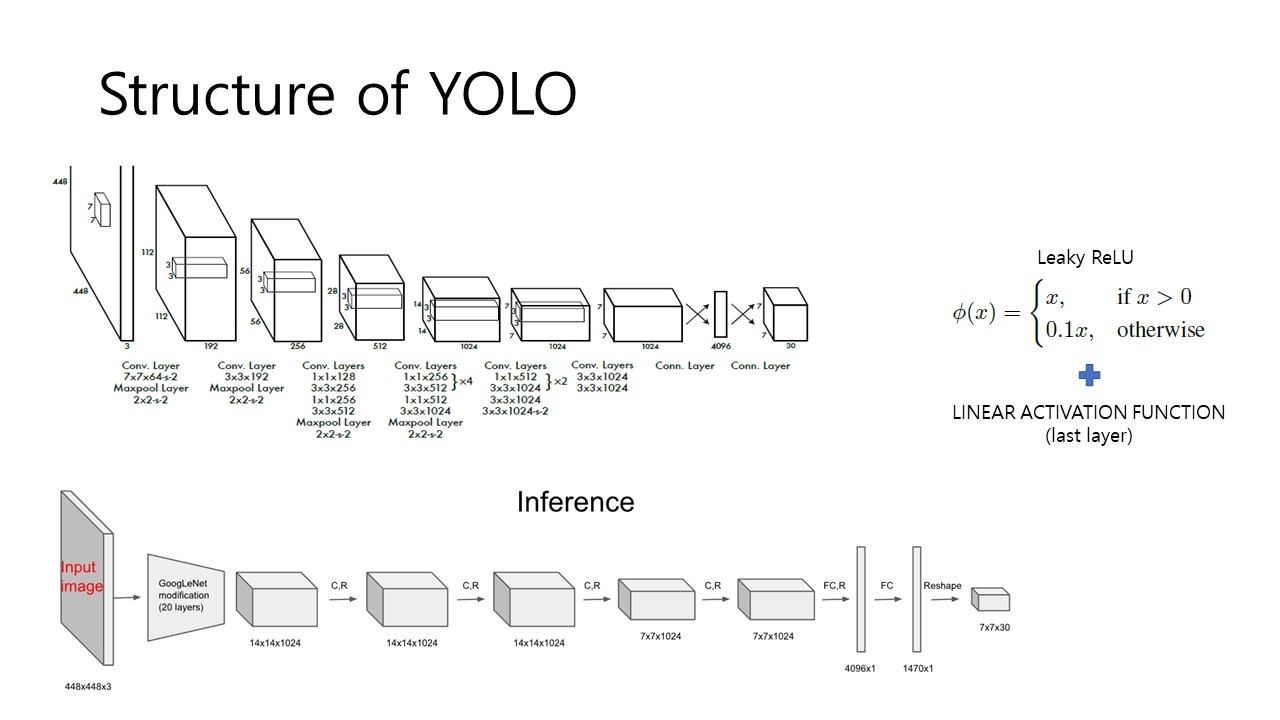
다음으로 이제 YOLO Algorithms의 Architecture에 대해 알아보겠습니다. YOLO는 총 24개의 Convolutional layer와 2개의 fully-connected layer으로 이루어져있으며 필자는 이 구조를 GoogLeNet 에서 영감을 얻었다고 했습니다. 다만 GoogLeNet에서 사용한 Inception module 대신 1x1 convolution layer와 3x3 convolution layer를 사용했다고 합니다. 여기서 사용하는 1x1 layer의 역할에 대해서는 GoogLe Net paper review에서 다루도록 하고, 지금은 단순히 가장 중요한 역할인 demension reduction을 통한 computational bottleneck 해결으로 생각하고 넘어가겠습니다.
위의 Fig 2의 하단 그림을 참고하면, 20개의 layer는 GoogLe Net modification이고 그 이후의 4개의 layer를 통해서 object detection을 학습시킵니다. 그 이후 2개의 fully-connected layer를 통해 7x7x30 Tensor를 얻게 됩니다. 각 Layer의 학습단계에서 Leaky ReLU 함수를 사용하고, 마지막 layer에서만 linear activation function을 사용했습니다.
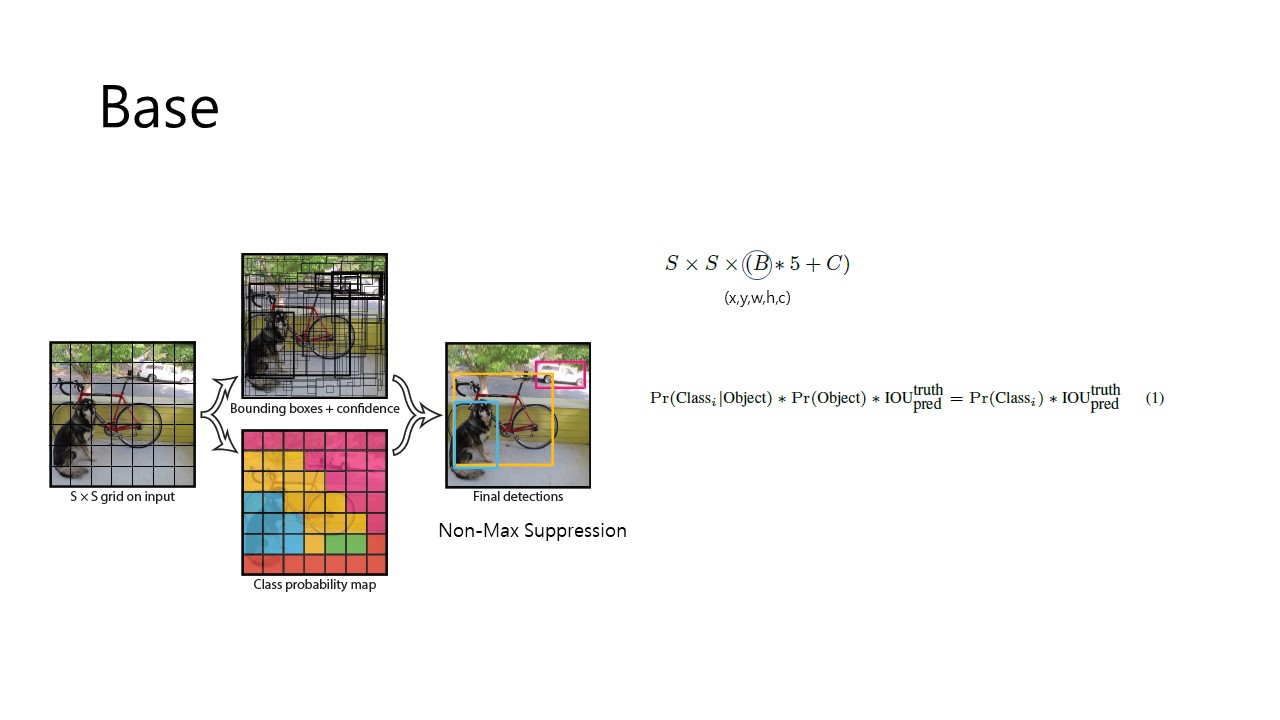
이제 이런 structure을 가지는 YOLO가 어떻게 동작하는지 살펴보면, YOLO는 input image를 SxS grid cell로 분할합니다. 이 과정에서 만약, object의 center가 grid cell에 위치한다면, 그 grid cell은 object detection에 주요한 grid cell이 되는 것입니다. 또한 각 grid cell은 B개의 bbox(boundary box)와 Confidence Score를 예측합니다. 그리고 총 20개의 class에 대해 학습을 거쳤습니다. 따라서 본 Fig 3의 식에서 S=7, B=2, C=20의 값을 얻게 되고, x5의 의미는 bbox의 5가지 prediction (x,y,w,h,c)입니다. x, y는 bbox의 중심 좌표 w, h는 bbox의 크기를 나타내며. 이를 대입하여 결국 7x7x30 Tensor의 output을 얻게 되는 것입니다.
각 요소에 대해 자세히 살펴보면 Confidence Score는 Pr(Objects)xIOU로 나타내지는데 이 의미는, model이 객체를 잘 포함하고 있는지, 그리고 얼마나 예측을 잘 했는지 나타내주는 것입니다. 따라서 grid cell 내에 객체가 존재할 경우 Pr(obj) = 1이므로 Confidence Score = IOU이고, 객체가 존재하지 않을 경우, Confidence Score는 0이 됩니다.
다음으로 7x7x30 Tensor의 동작에 대해 개략적으로 보도록 하겠습니다. 이 자료를 통해서 저는 Tensor의 원리에 대해 수월하게 이해할 수 있었고, 좀 있다 Review하는 v2와 v3에서도 무리없이 이해할 수 있었습니다.
Tensor
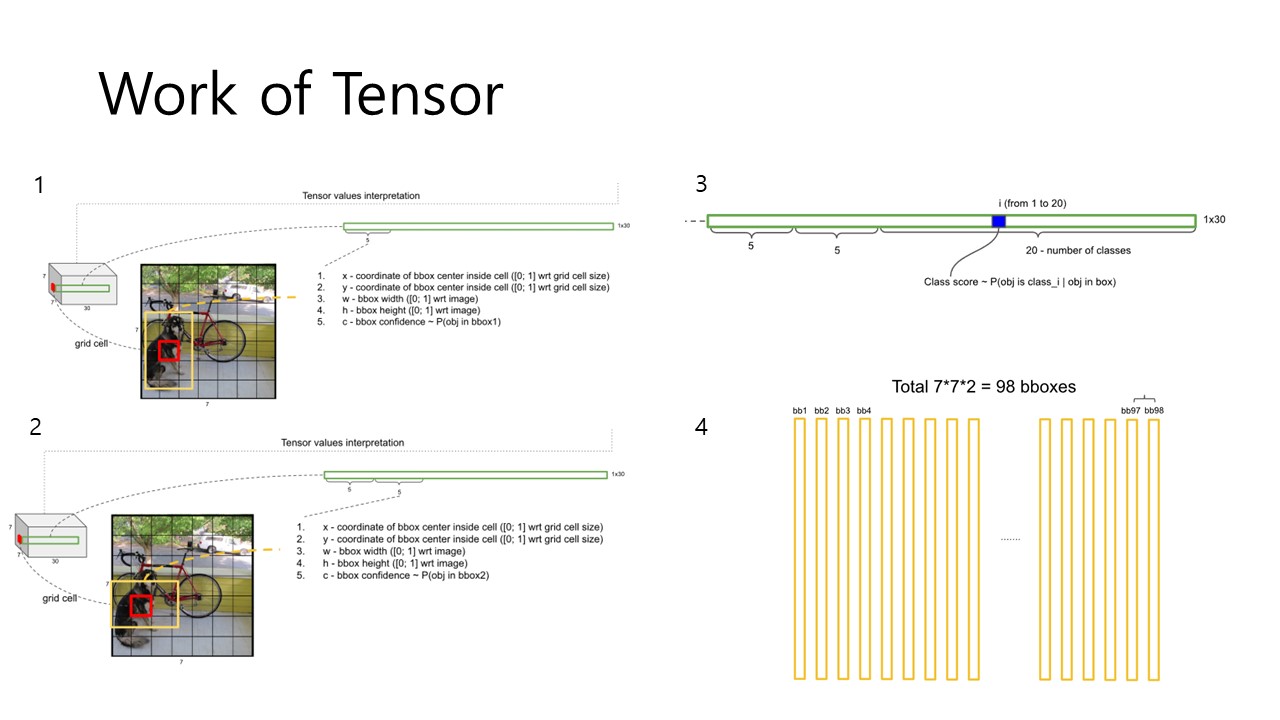
Fig 4를 통해서 왜 98개의 bbox가 생겨나는지, 그리고 Tensor의 역할이 어떻게 수행되는지 이해할 수 있었습니다. 각 grid cell 당 2개의 bbox가 할당되고(B=2) 하나의 bbox에는 5개의 prediction이 존재합니다.(x,y,w,h,c) 그리고 20개의 class가 존재하니 5+5+20 = 30 차원의 tensor를 가지고 모든 과정을 수행하는 것이며, grid cell은 7x7 = 49개 이므로 총 98개의 bbox에 대해 연산을 하는 것입니다. 보다 자세한 과정은 아래의 slide에 잘 정리되어 있습니다. 또한 YOLO가 수많은 bbox 중에서 특정 bbox만을 선택하는 기법이 Non-max Suppression(비-최대 억제)인데 그 내용도 상세히 설명되어 있으니 참고하시길 바랍니다.
Loss Function

거의 다 와 갑니다. 이제 Loss Function에 대해 알아보겠습니다. YOLOv1의 Loss function은 크게 3개의 part로 구분됩니다.
- bbox의 size, location Loss (x,y,w,h)
- Confidence Score Loss
- Classification Loss
먼저, 전체적으로 손실함수가 SSE(Sum of Squares Error)를 사용하고 있음을 확인할 수 있습니다. 훗날 이런 통계와 관련된 부분을 공부한 후 시리즈로 업로드 할 계획도 세우고 있습니다. 늘 계획만 세우지만요,,,, 손실함수에서 필자가 주목해야한다고 한 부분은 바로 람다값입니다. 이는 SSE의 optimize하기는 쉽지만, perfectly align하지 못하다는 단점을 보완하기 위한 방법입니다. 자세히 살펴보면,
- localization error가 classification error와 비슷한 가중치를 가지게 되는 점
- 모든 cell이 object를 가지진않아, confidence score가 0으로 수렴하여 overpowering gradient를 유발
따라서 결국 결국 model을 불안정하게 만드는 단점을 가지고 있습니다. 이를 해결하기 위해, object를 포함하고 있지 않은 bbox의 가중치를 0.5로 설정하여 penalty를 낮춰주고, localization error에 5의 가중치를 주어 penalty를 증가시키는 parameter를 추가한 것입니다. 또 기존의 SSE 방식에는 문제점이 더 있는데, 바로 bbox의 크기에 상관없이 weight errors한다는 점입니다. 따라서 필자는 이 문제점을 해결하기 위해 Loss function의 첫 번째 part에 size와 height 연산에 sqaure root를 취해주었습니다.
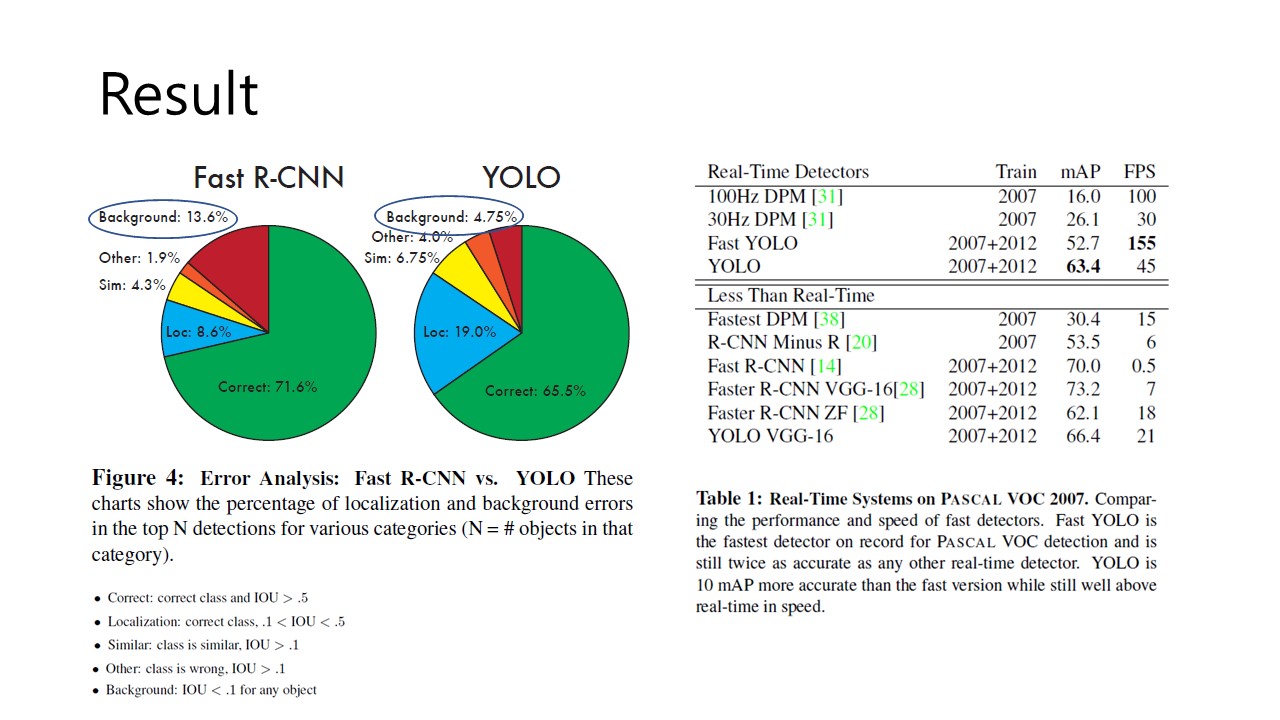
이렇게 완성한 YOLO의 test 결과 R-CNN에 비해 확연하게 줄어든 Background error를 볼 수 있습니다. 또한 Table 1에서 확인할 수 있듯 real-time detection에서도 높은 mAP를 나타냄을 확인할 수 있습니다. 하지만 localize error에서는 해결해야할 점이 있음을 나타내기도 합니다.
이러한 점이 바로 YOLO의 limitation이기도 합니다. YOLOv1의 한계는
- Each grid cell only predicts one class -> 새들의 군집 등을 분석하기 힘듭니다.
- bbox가 data에 따라 학습되어 새로운 형태의 bbox에 대해 대응이 어렵습니다.
- 작은 bbox의 loss가 더 큰 영향을 미쳐, localization error가 높아집니다.
이러한 점을 해결해나가는 과정이 YOLOv2와 YOLOv3로 이는 다음 포스트에 업로드 하겠습니다.
긴 글 읽어주셔서 감사합니다😊😊
Reference
YOLOv1 논문리뷰 by herbwood
YOLOv1 논문리뷰 by 딥러닝공부방
YOLOv1 논문리뷰 by 비전홍
CVPR 2016 YOLOv1 Youtube 영상

