읽은 날짜 : 2020.09.07
2023.01.05 기준 citation : 148,678
He, K., Zhang, X., Ren, S., & Sun, J. (2016). Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 770-778).
지금은 누구나 딥러닝을 다뤄본 사람이면 그 구조나 기능, 철학 등은 몰라도 torchvision.models.resnet 을 통해 사용해봤을 모델인 ResNet을 처음 소개한 논문임.
Introduction
본 논문의 초반부에 다음과 같은 질문을 함.
Is learning better networks as easy as stacking more layers?
쉽게 말하면 CNN layer를 깊게 쌓으면 쌓을수록 좋은 성능을 가지는 모델을 얻을 수 있는 것이 맞는지 묻는 것임.
Deep한 모델들은 vanishing/exploding gradient 문제를 겪어서 그 optimize가 쉽지 않은데, normalization layer나 normalized initialization으로 어느정도 해결했었다고 함.
예를 들어 BN(batch normalization)나 Glorot initialization(네트워크의 variance가 커지는 것을 방지할 수 있게 weight를 initialize) 같은 방법을 사용하는 것.
그런데, 그거보다 더 깊어지면 vanishing gradient 문제가 발생하면서 degradation 문제가 발생한다는 것을 발견했음.
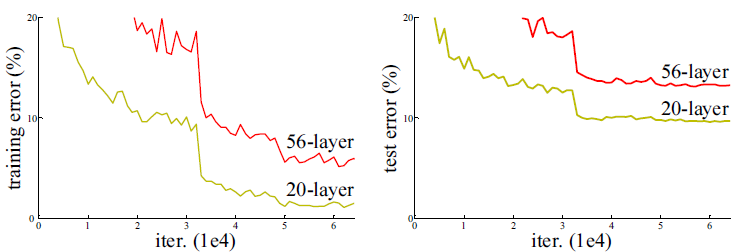
위 그림을 보면 알 수 있듯이 저자가 발견한 degradation이 overfitting에 의해 발생하는 것이 절대 아니다.
처음 읽었을 당시에 아래처럼 정리하면서 좀 신기했었다.
- overfitting : 모델의 capacity가 증가하면서 test accuracy가 낮아짐
- degradation : 모델의 capacity가 너무 증가하면서 train accuracy(test도 마찬가지)가 낮아짐
본 논문에서는 이러한 문제가 optimize 자체에 대한 문제라고 보고 identity mapping 을 사용하는 구조적 변화를 통해 해결하고자 하고 deep residual learning을 제안함.
Related Work
생략
Deep Residual Learning
1. Residual Learning
이 연구의 전부라고도 할 수 있는데 철학이 중요함.
아까 위의 사진에서 56-layer가 20-layer 보다 성능이 안좋은데, 20을 뺀 나머지 36-layer가 그냥 로만 mapping 시키기만 해도 같은 성능이 나와야하지 않는가??
그러면 여러개의 nonlinear layer를 결합해서 identity mapping의 기능을 할 수 있는 weight을 찾는 것이 어려울 수 있으니 애초에 그게 쉬워질 수 있는 output을 설정해주자라는 관점.
그래서 어떠한 desired mapping 이 존재할 때, 직접 찾는 것이 아니라 residual인 을 output 으로 찾게 한다. 그러면 원래 찾고 싶었던 mapping이 가 되고, 이러한 mapping 을 찾기 위해 다음 그림과 같은 네트워크를 구성하게 됨.
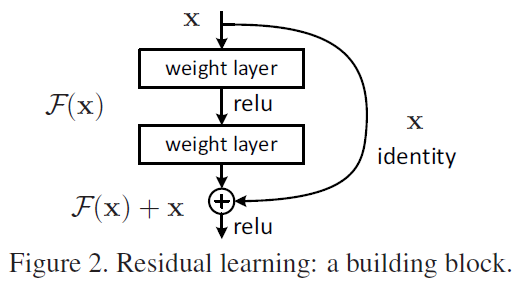
2. Identity Mapping by Shortcuts
3. Network Architectures
나머지 내용보다는 솔직히 위에서 설명한 Residual learning의 논리가 더 중요하다고 생각해서 생략.
또한 아키텍쳐를 직접 코드로 구현해보거나 구현되어 있는 것을 보고 이해하는 것도 중요하다고 생각하는데 공식 코드 를 참고.
ResNet 코드를 보면 크게 다음 세가지로 나눠짐 : BasicBlock(), BottleNeck(), ResNet() .
여기서 BasicBlock()은 ResNet-34까지 사용되는 3x3 convolution이 두 개 있는 구조임.
class BasicBlock(nn.Module):
def __init__(self, ...):
...
def forward(self, x: Tensor) -> Tensor:
identity = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
if self.downsample is not None:
identity = self.downsample(x)
out += identity
out = self.relu(out)
return out`BottleNeck()`은 ResNet 이 더 깊어질 때 사용되는 구조로 1x1, 3x3, 1x1 convolution 으로 구성되어있는 구조로, 연산량의 부담을 줄여줌.
class BottleNeck(nn.Module):
def __init__(self, ...):
...
def forward(self, x: Tensor) -> Tensor:
identity = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.relu(out)
out = self.conv3(out)
out = self.bn3(out)
if self.downsample is not None:
identity = self.downsample(x)
out += identity
out = self.relu(out)
return out각 Block 내부에는 기본적으로 skip connection과 down sampling을 수행하는 부분이 존재함.
def _make_layer(self, ...):
downsample = None
stride = 1
if stride != 1 or self.inplanes != planes * block.expansion:
downsample = nn.Sequential(
conv1x1(self.inplanes, planes * block.expansion, stride),
norm_layer(planes * block.expansion),
)down sample은 기본으로 None 값이지만 input과 output의 차원이 바뀔 때 stride=2로 설정하여 차원을 축소시킴. 이는 VGG에서 max_pool을 이용하여 차원을 줄인 것과 다름.
if self.downsample is not None:
identity = self.downsample(x)또한 skip connection은 두가지가 있는데 identity shortcut 은 차원이 같을 때(downsample is None) 를 수행하는 것이고 차원이 다를 때(downsample is not None)는 projection shortcut을 수행하는데 로 이 때 는 위에서 down sampling을 해주는 1x1 convolution과 batch normalization을 해주는 값.
Experiements
ImageNet Classification
- 다양한 실험 및 구조적인 부분에서의 ablation study
CIFAR-10 and Analysis
Object Detection on PASCAL and MS COCO
등등 다양한 실험을 통해 제안된 아키텍처를 통해 CNN의 depth를 높여도 강건하게 여러 vision task에서 좋은 성능을 보인다는 것을 입증함.
