읽은 날짜 : 2020.10.05
2023.01.06 기준 citation : 4548
Carion, N., Massa, F., Synnaeve, G., Usunier, N., Kirillov, A., & Zagoruyko, S. (2020, August). End-to-end object detection with transformers. In European conference on computer vision (pp. 213-229). Springer, Cham.
연구실에서 발표한 세번째 논문이었는데 논문 자체도 너무 길고,transformer가 뭔지도 몰랐었을 때라서 transformer 논문부터 읽으면서 공부했었음. 또 end-to-end가 무슨 뜻인지도, 어떤 장점이 있는지 몰랐는데 해당 논문을 준비하면서 많은 것을 배웠음.
Introduction
Machine translation, speech recognition 등 여러 복잡한 task에서 end-to-end 철학이 잘 통했고 뛰어난 성능을 보임. 하지만 object detection에서는 기존의 strong baseline 들과 경쟁할만큼 좋은 성능의 모델들이 나오지 못함.
본 연구인 DETR은
1. Object detection 문제를 a direct set prediction 문제로 보았고
2. transformer 구조를 채택하여 set prediction 을 용이하게 하였고
3. 기존의 object detection과 다르게 anchor, non-maximal suppression (Faster R-CNN) 과 같은 prior 정보를 사용하지 않는다는 특징이 있음.
전체적인 구조는 다음과 같음

본 논문이 괜찮은 점은 기존 방법론들은 object detection을 딱 region proposal classification (overlapping 이나 중복 box 제거) bounding box regression을 하는 문제로 정의하고 수행했었는데 발상의 전환으로 optimal bipartite matching 문제로 바꾸었음.
물론 YOLO series 는 region proposal 없이 한번에 classification, bounding box regression 함
Related work
2.1 Set Prediction
대부분의 detector 들은 여러개의 box들에서 중복되거나 겹치는 box들을 제거하고 하나로 만들어 주는 postprocessing 과정이 필요함.
NMS, Anchor Generation 같은 것들
본 연구에서는 고정된 크기의 predicted boxes와 ground truth 사이에서 bipartite matching loss를 사용하여 direct set prediction을 수행함. 이 때 Hungarian 알고리즘을 사용함.
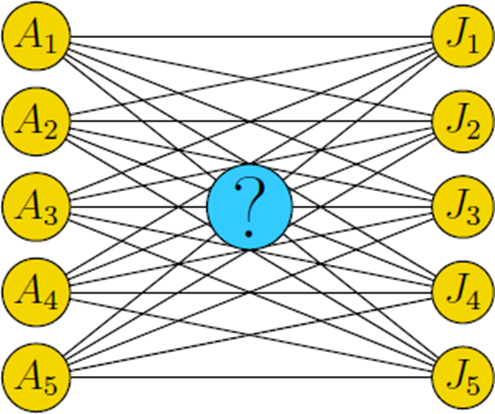
Bipartite matching loss는 위 그림과 같이 prediction set 에서 순서가 뒤바뀌어도 값이 일정하게 나올 수 있도록 헝가리안 알고리즘(할당 문제에서 많이 이용)을 사용해서 optimal matching을 구해서 계산하게 됨.
2.2 Transformers and Parallel Decoding
2.3 Object detection
생략
요즘에 트랜스포머는 설명이 잘 되어있는 곳이 굉장히 많음!
The DETR model
본 논문에서도 언급했다시피 두가지 요소가 제일 중요한데, 그것만 이해하면 됨.
3.1 Object detection set prediction loss
논문에 쓰인 수식은 특별할 것이 없어서 논리를 위주로 설명하고 그 전에 notation 간단 정리.
- 우선, DETR은 이미지 하나에 대해 개의 prediction을 내놓는다.
- 이 prediction와 ground truth 사이의 loss를 계산하는데 각 종속변수는 의 형태이다.
- 는 class label, 에 해당하는 부분이 어떤 객체인지를 나타내는 것임 (객체가 아닌 경우도 예측함)
- 는 가운데 점 좌표랑 box 크기를 나타내는 형태.
- 예를 들어 어떤 이미지에 객체가 2개인데 이면, ground truth를 설정해줄 때 3 (5 - 2)개는 로(객체가 없음) padding 시켜줌.
- 이미지 하나마다 개의 prediction이 나와서 set을 이루는데, 이 set과 ground truth set에서 loss를 계산하기 위해 우선 pair-wise optimal matching을 찾음.
개의 prediction의 순서를 섞은 모든 경우의 수 에 대해서 젤 좋은 거 를 찾는 것임.
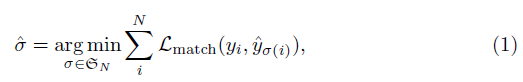
- 이 때 matching loss 가 가장 작아지는 matching을 구하고, 다음 식을 통해 loss 계산.
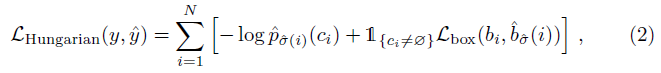
Optimal matching을 구할 때는 실제로 객체가 존재하는 애들끼리만 matching loss 를 계산해서 순서가 맞도록 해줌.
다시말해서 일단 prediction set에서 객체가 존재하지 않는데 객체가 존재한다고 하는 것에는 신경을 쓰지 않는 것. 이 부분이 region proposal 같은 느낌임.
Optimal matching을 한 후에 을 계산할 때에는 객체가 존재하지 않는 경우에 대해서도 loss 계산을 해줘서, 이미지에 객체가 없는 부분에 대해서는 객체가 없도록 예측하도록 학습시킴.
3.2 DETR architecture
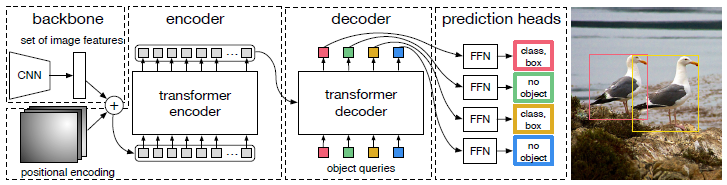
우선 CNN에서 feature map 를 추출하고 transformer encoder에 넣을 때는 로 해줌.
다음 Decoder가 중요한데, 그냥 All you need is attention 에서 처럼 autoregressive 하게 output 뱉는 것이 아니라 개의 object query 라는 것을 input으로 넣어서 병렬적으로 한번에 나오게 했다고 함.
Experiments
생략
Ablation study나, encoder의 self-attention 효과를 보여주는 실험 등을 보면 재밌는 것이 많음.

특히 위 그림처럼 당시에 self-attention을 활용했더니, occlusion이 존재하는 이미지도 global 한 정보를 잘 얻는다는 것이 신기했음.
Critics
Critic은 항상 당시 세미나 준비 당시에 적었던 것들과 이제 다시보고 느낀 것들을 종합해서 적을 것임.
- Object detection 문제를 optimal bipartite matching 문제로 바라본 발상
- Transformer 모델의 CV에서의 효과 입증
- 개선의 여지
-
긴 학습시간
-
모델을 end-to-end 가 되게 하는 것이 항상 좋은 것인지
- 물론 이때부터 트렌드였고, 모델이 모든 것을 알아서 조절할 수 있도록 학습하는 것이 매력적이다.
- 하지만, 실용적인 측면에서 볼 때,
- 어디서 문제가 발생했는지 파악하기 어렵다는 것(쉽게 말해서 컨트롤이 어렵다)
- 데이터가 정말 많이 필요하다는 것, 다시 말하면 데이터 적으면 과적합 쉽게 난다는 것
- modularity 측면에서도 구성요소를 떼었다 붙혔다, 바꾸거나 하는 것이 매우 어려울 것
-
성능이 엄청 뛰어나지 않음
