Gradient Descent
Batch Learning
- weights는 모든 training data에 관해서 최적화가 진행됩니다.
- 전체 training dataset을 사용해서 weight를 한번 업데이트 합니다.
- 진행 순서(이 순서를 계속 반복함)
- 현재 w를 예측
- loss 측정
- gradient 계산
- w update
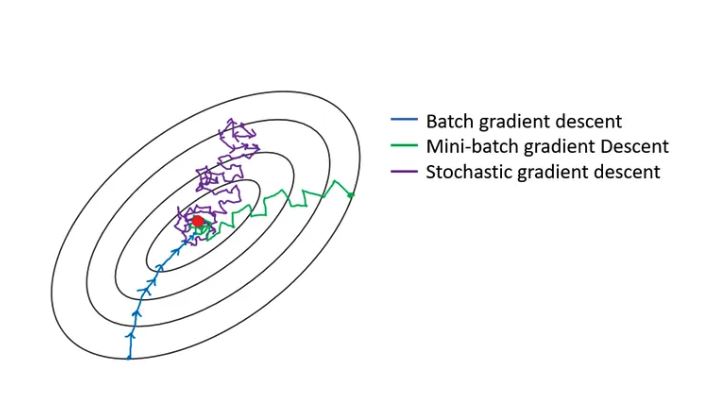
Batch Gradient Descent
- 모든 데이터셋을 한번에 학습한다고 생각하면 됩니다.
- 많은 양의 학습을 한번에 진행하기 때문에 큰 메모리가 필요합니다.
- 최적화가 다소 안정적입니다.
Online Gradient Descent
- data point를 개별적으로 처리하면서 weight를 계속 업데이트 합니다.
- 즉, 데이터 포인트를 받은 후, 즉시 모델을 업데이트 합니다.
- Batch Gradient Descent보다 더 빠르게 모델을 조정할 수 있습니다.
- 전체 dataset을 메모리에 저장할 필요가 없기 때문에, 메모리 사용량이 적습니다.
- Mini-batch도 Online Gradient Descent의 방법 중 하나입니다.
- Stochastic gradient descent는 모델의 weight를 업데이트할 때마다 단 하나의 데이터 포인트를 사용합니다.
- Mini-batch는 각 weight를 업데이트 할 때, 미니배치를 사용합니다. 이 미니 배치는 여러 데이터 포인트로 구성됩니다.
용어 정리
- Batch size : 한 배치에 보여지는 총 training data의 갯수.
- Epoch : 1 Epoch은 전체 데이터셋이 한번 다 돌았을 때를 의미한다.
- Iteration : 1 Epoch을 돌기 위해 필요한 batch의 갯수를 의미한다.
- 예를 들자면, D = 4000, batch size = 500, 8 iterations
이미지 출처
https://medium.com/@harsharora0703/gradient-descent-and-stochastic-gradient-descent-53bbd1b9b0ff

Viel Erfolg!