앞서 살펴본 머신러닝의 핵심은 바로 대상 간 구별하는 feature 였다.
이번에는 머신러닝의 학습 방법에 따른 분류인 다음의 3가지
supervised learning, unsupervised learning, reinforcement learning에 대해 알아보자.
1. Supervised Learning(지도 학습)
크게 어려울 것 없이 처음 input을 줄 때 정답을 같이 제공해 학습시키는 방법이다. 사람이 문제에 대한 답을 알고 있고, 인공지능이 그것을 알아낼 수 있도록 훈련시키고자 할 때 사용한다.
이는 다음 특징을 갖는다
- 단순하고 일반적이다
- 사람이 답을 알고 있고 인공지능이 알아내도록 훈련시킬 때 사용
- Label이 확실히 분류된 데이터를 사용한다
이러한 supervised learning도 두 가지로 나뉘는데
1-1. classification(분류)
classification technique은 입력 데이터를 특정 Label로 식별하기 위해 알고리즘에 "이산 값"을 예측하도록 요청한다.
다음의 예제를 보면 이해가 쉬울 것이다.
ex1) Naive Bayesian Classifier 과정
어떤 영화에 대한 댓글이 긍정/부정의 반응인지 분류하고 싶을 때,
긍정/부정에 대한 feature을 뽑는다. 예를 들어 최고, 재미, 짜증, 괜히 등과 같은 여러 feature를 뽑고 이를 기반으로 해 댓글들을 조사해 학습 데이터를 수집해 feature vector를 구성한다.
학습한 feature vector에서 각각 긍정, 부정이 전체 feature 중 차지하는 비율을 고려해 둘 중 큰 쪽으로 해당 feature에 대해 예측한다.
이처럼 문제에 대해 긍정인지 or 부정인지 명확하게 나뉘어지는 Label에 대해서 classification이라 한다.
ex2) Decision Tree
: 조건에 부합하도록 트리 형태로 계속 세분화해서 나누는 과정. internal nodes(feature를 나누는 질문)와 leaf node(리프 노드는 Label)로 구성된다.

ex3) k-nearest Neighbors
: 입력 데이터에 가장 가까운 k개의 데이터 레이블 중 더 많은 쪽으로 결정
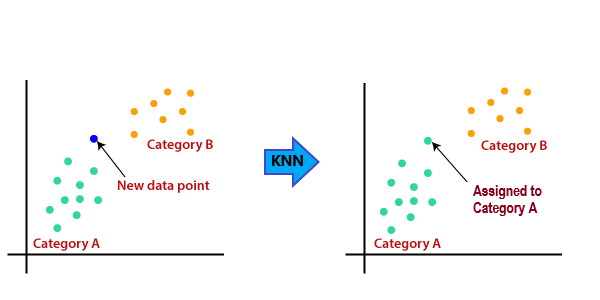
만약 k=3이라면 결정할 점에 대해 가장 가까운 k(=3)개의 점 중 더 많은 쪽의 Label로 결정하는 방식이다.
이 방식은 학습 단계가 불필요하지만 k값에 따른 적용을 해야하기 때문에 예측 시간이 느리며 가장 최적의 k값을 결정하기 어렵다는 특징이 갖는다.
ex4) Linear Model
: 선형 모델로, 오류를 최소화하는 선형 모델을 찾는 방식
ex5) SVM(Support Vector Machine)
: maximum margin line을 결정하는 모델
1-2. Regression(회귀)
앞의 classification이 이산 값에 대해 예측하는 모델이었다면 regression은 continuous한 출력에 대해 예측하는 모델이다.
계속해서 변동하는 주가 예측 등이 이에 해당한다.
2. Unsupervised Learning(비지도 학습)
supervised learning가 달리 input과 함께 정답 Label이 주어지지 않고 학습시키는 방법이다. 인공지능이 주어진 input에서 패턴과 상관관계를 찾아내야 하는 머신러닝 알고리즘이다.
다음 특징을 가진다.
- 레이블이 지정되지 않은 데이터를 처리한다
- 사용자가 보다 복잡한 처리 작업을 수행할 수 있도록 한다
- 더 예측이 어렵다
ex1) k-means Clustering
: 데이터를 k개의 군집으로 묶는 알고리즘
이 때 k는 묶을 군집의 수를 의미하고 과정은 다음과 같다.
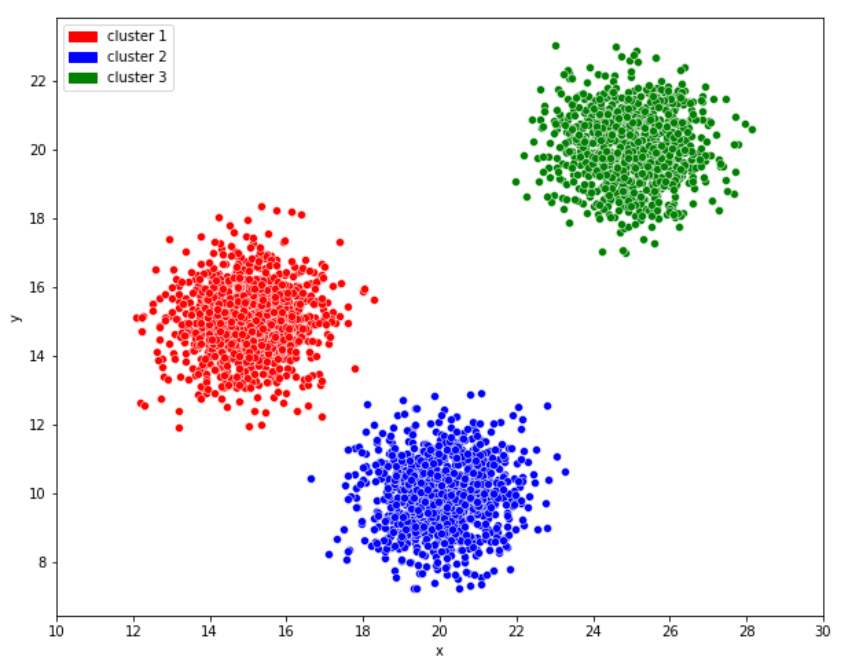
k=3이라고 하자. 위의 점들 형태로 점이 분포해 있을 때 임의의 중심점 3점을 설정하고 각 데이터들을 가장 가까운 중심점의 군집으로 할당한다.
이 시행을 한 번씩 반복하고 같은 색 군집의 범위 가운데에 또다시 중심점을 재배치하고 위 과정을 반복한다. 이는 군집의 소속이 바뀌는 점이 없을 때까지 진행한다.
앞선 classification의 k-nearest 방법과 비슷한 것 같지만 완전히 다르다.
classification은 미리 Label이 주어진 정보에 대해서 학습해 분류를 수행하지만 k-means clustering은 주어진 Label이 없는 상태에서 비슷한 속성을 가진 데이터들끼리 묶어준다는 차이점이 있기 때문이다.
ex2) Hierarchical Clustering
: 임의로 분포된 데이터들에 대해 가장 가까운 데이터끼리 순서대로 grouping하여 군집화(-> 작은 단위로부터 군집화를 시작해 모든 데이터를 묶을 때까지 반복하는 bottom-up 방식)
or (-> 전체 데이터를 하나의 군집으로 묶고 시작하는 top-down 방식)
3.Reinforcement Learning(강화학습)
: 여러 시행착오를 통해 학습하는 방법. 이런 과정을 통해 실수와 보상을 통해 목표를 찾아가는 알고리즘이다.
- 환경에 대한 사전지식이 없는 상태로 학습 진행
- 컴퓨터가 선택한 행동에 대한 환경에 반응에 따라 보상이 주어짐
- 보상을 최대한 많이 얻는 쪽으로 행동을 유도하도록 학습 진행
이번에는 머신러닝의 학습 방법에 따른 분류에 대해 알아보았다. 다음에는 clssification 중 linear model에 대해 알아보자.
