Python DB-API는 여러 DB에 접근할 수 있는 표준 API 입니다. 표준 API는 크게 3가지의 작업을 합니다.
- DB를 연결한다.
- SQL문을 실행한다.
- DB 연결을 닫는다.
내용
- 파이썬의 DB 다루기
- SQLite
- Python & DB
- Python DB API
- DDL 문으로 테이블 생성하기
- SQL
- SQL의 기본
- DISTINCT와 GROUP BY
- 데이터 TYPE
- 다양한 조건으로 조회하기
- JOIN 수행하기
Python DB API
DB 연결을 위한 전화선인 sqlite3 모듈을 import
- 표준 라이브러리인 sqlite3로 DB를 쉽게 이용할 수 있습니다.
import sqlite3이제 파이썬과 DB를 연결해 보겠습니다. conn에 DB 이름을 정하여 입력합니다. 저는 mydb로 지었는데요. [이름].[확장자명] 형태로 하면됩니다.
import os
db_path = os.getenv('HOME')+'/mydb.db'
conn = sqlite3.connect(db_path) # mydb.db에 연결합니다.
print(conn)conn 객체에는 SQL 연결과 관련된 셋팅이 포함되어 있습니다. 이번에는 Connect() 함수의 연결을 사용하는 새로운 Cursor 객체를 만듭니다.
- Cursor는 SQL 질의(Query)를 수행하고 결과를 얻는데 사용하는 객체입니다.
- SQL INSERT문 : 테이블에 데이터를 삽입(추가)하는 질의입니다.
- SQL SELECT문 : 테이블에 데이터를 조건에 따라 조회하는 질의입니다.
c = conn.cursor()
print(c)
# stocks이라는 이름의 테이블을 하나 생성합니다. 혹시 이미 생성되었다면 생략합니다.
c.execute("CREATE TABLE IF NOT EXISTS stocks (date text, trans text, symbol text, qty real, price real)")
# stocks 테이블에 데이터를 하나 인서트합니다.
c.execute("INSERT INTO stocks VALUES ('20200701', 'TEST', 'AIFFEL', 1, 10000)")
# 방금 인서트한 데이터를 조회해 봅니다.
c.execute("SELECT * FROM stocks")
# 조회된 내역을 커서를 통해 가져와 출력해 봅니다.
print(c.fetchone())('20200701', 'TEST', 'AIFFEL', 1.0, 10000.0)
commit
삽입, 갱신, 삭제 등의 SQL 질의가 끝났다면 conn.commit()를 호출해야 DB가 실제로 업데이트 됩니다 . commit()을 하기 전에는 DB에 데이터가 업데이트된 것 같아 보여도 임시로만 바뀐 것이니 주의해야 합니다.
- connection을 통해 인서트 된 데이터는 conn.commit()를 호출하기 전까지는 그 connection 안에서만 유효합니다.
conn.commit()commit()을 통해 데이터베이스에 데이터 변경이 실제적으로 반영되었습니다.
commit()을 완료했다면 DB와 대화하는 것을 마무리 지어야 합니다.
c.close() # 먼저 커서를 닫은 후
conn.close() # DB 연결을 닫아 줍니다.DDL문으로 테이블 생성하기
다양한 테이블을 조회해 보기 앞서, 실제 예제 테이블들을 한번 생성해 보도록 하겠습니다. 테이블명과 컬럼명을 한글로도 지정할 수 있습니다.
import sqlite3
import os
db_path = os.getenv('HOME')+'/mydb.db'
conn = sqlite3.connect(db_path)
c = conn.cursor()
#- ! 재실행 시 테이블이 존재할 수 있으므로 아래처럼 해당 테이블들을 모두 지워줍니다.
c.execute("DROP TABLE IF EXISTS 도서대출내역")
c.execute("DROP TABLE IF EXISTS 도서대출내역2")
c.execute("DROP TABLE IF EXISTS 대출내역")
c.execute("DROP TABLE IF EXISTS 도서명")
#----- 1st table : 도서대출내역 -----#
c.execute("CREATE TABLE IF NOT EXISTS 도서대출내역 (ID varchar, 이름 varchar, 도서ID varchar, 대출일 varchar, 반납일 varchar)")
#- 생성(create)문 : 테이블명, 변수명, 변수타입을 지정
data = [('101','문강태','aaa','2020-06-01','2020-06-05'),
('101','문강태','ccc','2020-06-20','2020-06-25'),
('102','고문영','bbb','2020-06-01',None),
('102','고문영','ddd','2020-06-08',None),
('103','문상태','ccc','2020-06-01','2020-06-05'),
('104','강기둥',None,None,None)]
#- 입력할 데이터를 그대로 입력 (변수명 순서 기준대로)
c.executemany('INSERT INTO 도서대출내역 VALUES (?,?,?,?,?)', data)
#- 입력할 데이터를 실제 테이블에 insert하기
#-----------------------------------------------#
#----- 2nd table : 도서대출내역2 -----#
c.execute("CREATE TABLE IF NOT EXISTS 도서대출내역2 (ID varchar, 이름 varchar, 대출년월 varchar, 대출일수 varchar)")
data = [('101','문강태','2020-06','20일'),
('102','고문영','2020-06','10일'),
('103','문상태','2020-06','8일'),
('104','강기둥','2020-06','3일')]
c.executemany('INSERT INTO 도서대출내역2 VALUES (?,?,?,?)', data)
#--------------------------------------------------#
#----- 3rd table : 대출내역 -----#
c.execute("CREATE TABLE IF NOT EXISTS 대출내역 (ID varchar, 이름 varchar, 도서ID varchar)")
data = [('101','문강태','aaa'),
('102','고문영','bbb'),
('102','고문영','fff'),
('103','문상태','ccc'),
('104','강기둥',None)]
c.executemany('INSERT INTO 대출내역 VALUES (?,?,?)', data)
#-----------------------------------------#
#----- 4th table : 도서명 -----#
c.execute("CREATE TABLE IF NOT EXISTS 도서명 (도서ID varchar, 도서명 varchar)")
data = [('aaa','악몽을 먹고 자란 소년'),
('bbb','좀비아이'),
('ccc','공룡백과사전'),
('ddd','빨간구두'),
('eee','잠자는 숲속의 미녀')]
c.executemany('INSERT INTO 도서명 VALUES (?,?)', data)
#--------------------------------------#
conn.commit()
conn.close()
conn = sqlite3.connect(db_path)
c = conn.cursor()
for row in c.execute('SELECT * FROM 도서명'):
print(row)('aaa', '악몽을 먹고 자란 소년')
('bbb', '좀비아이')
('ccc', '공룡백과사전')
('ddd', '빨간구두')
('eee', '잠자는 숲속의 미녀')
SQL의 기본
데이터베이스(DB)에서 데이터를 조회하고자 할 때 필요한 컴퓨터 언어입니다. 테이블을 삽입하거나 삭제, 갱신, 조회하는 등 본인이 원하는 형태로 데이터를 만들어 가져올 수 있습니다.
쿼리의 기본 구조
- SELECT ~ : 조회할 컬럼명을 선택
- FROM ~ : 조회할 테이블명을 지정 (위치와 테이블명을 입력)
- WHERE ~ : 질의할 때 필요한 조건을 설정
- GROUP BY ~ : 특정 컬럼을 기준으로 그룹을 지어 출력
- ORDER BY ~ : SELECT 다음에 오는 컬럼 중 정렬이 필요한 부분을 정렬 (기본 설정 : 오름차순)
- LIMIT 숫자 : Display하고자 하는 행의 수를 설정
#- 참고 : 실제 조회를 해보시려면 아래처럼 쓰시면 됩니다.
#- c.execute() 괄호 안에 SQL문을 넣으시면 됩니다.
import os
db_path = os.getenv('HOME')+'/mydb.db'
conn = sqlite3.connect(db_path) # mydb.db에 연결합니다.
c = conn.cursor()
for row in c.execute('SELECT * FROM 도서대출내역'):
print(row)
#- ! 출력 시 'NULL' 대신 'None'으로 출력될 수 있으나 동일하게 이해하시면 됩니다.('101', '문강태', 'aaa', '2020-06-01', '2020-06-05')
('101', '문강태', 'ccc', '2020-06-20', '2020-06-25')
('102', '고문영', 'bbb', '2020-06-01', None)
('102', '고문영', 'ddd', '2020-06-08', None)
('103', '문상태', 'ccc', '2020-06-01', '2020-06-05')
('104', '강기둥', None, None, None)
/ 전체 조회 /
SELECT * FROM 도서대출내역;
- SELECT와 FROM 사이에는 특정 컬럼을 넣어 출력하곤 하는데요. 위의 쿼리처럼 별(*)을 입력하게 되면 '테이블 전체를 다 가져와라'라는 명령어가 됩니다.
for row in c.execute('SELECT * FROM 도서대출내역'):
print(row)('101', '문강태', 'aaa', '2020-06-01', '2020-06-05')
('101', '문강태', 'ccc', '2020-06-20', '2020-06-25')
('102', '고문영', 'bbb', '2020-06-01', None)
('102', '고문영', 'ddd', '2020-06-08', None)
('103', '문상태', 'ccc', '2020-06-01', '2020-06-05')
('104', '강기둥', None, None, None)
/ 특정 컬럼을 지정 /
SELECT ID FROM 도서대출내역;
for row in c.execute('SELECT ID FROM 도서대출내역'):
print(row)('101',)
('101',)
('102',)
('102',)
('103',)
('104',)
/ 조건을 입력하기 /
SELECT * FROM 도서대출내역 WHERE 이름 = "문강태";
for row in c.execute('SELECT * FROM 도서대출내역 WHERE 이름 = "문강태";'):
print(row)('101', '문강태', 'aaa', '2020-06-01', '2020-06-05')
('101', '문강태', 'ccc', '2020-06-20', '2020-06-25')
/ GROUP BY로 중복을 제거해 보기 /
SELECT 이름 FROM 도서대출내역 GROUP BY 이름;
for row in c.execute('SELECT 이름 FROM 도서대출내역 GROUP BY 이름;'):
print(row)('강기둥',)
('고문영',)
('문강태',)
('문상태',)
/ DISTINCT로 중복을 제거해보기 /
SELECT DISTINCT 이름 FROM 도서대출내역;
for row in c.execute('SELECT DISTINCT 이름 FROM 도서대출내역;'):
print(row)('문강태',)
('고문영',)
('문상태',)
('강기둥',)
/ ORDER BY로 정렬해보기 /
SELECT * FROM 도서대출내역 ORDER BY ID ;
for row in c.execute('SELECT * FROM 도서대출내역 ORDER BY ID ;'):
print(row)('101', '문강태', 'aaa', '2020-06-01', '2020-06-05')
('101', '문강태', 'ccc', '2020-06-20', '2020-06-25')
('102', '고문영', 'bbb', '2020-06-01', None)
('102', '고문영', 'ddd', '2020-06-08', None)
('103', '문상태', 'ccc', '2020-06-01', '2020-06-05')
('104', '강기둥', None, None, None)
반대는 내림차순으로 DESC라고 씁니다.
for row in c.execute('SELECT * FROM 도서대출내역 ORDER BY ID DESC ;'):
print(row)('104', '강기둥', None, None, None)
('103', '문상태', 'ccc', '2020-06-01', '2020-06-05')
('102', '고문영', 'bbb', '2020-06-01', None)
('102', '고문영', 'ddd', '2020-06-08', None)
('101', '문강태', 'aaa', '2020-06-01', '2020-06-05')
('101', '문강태', 'ccc', '2020-06-20', '2020-06-25')
/ 몇개의 row만 조회하기 /
SELECT * FROM 도서대출내역 LIMIT 5 ;
for row in c.execute('SELECT * FROM 도서대출내역 LIMIT 5 ;'):
print(row)('101', '문강태', 'aaa', '2020-06-01', '2020-06-05')
('101', '문강태', 'ccc', '2020-06-20', '2020-06-25')
('102', '고문영', 'bbb', '2020-06-01', None)
('102', '고문영', 'ddd', '2020-06-08', None)
('103', '문상태', 'ccc', '2020-06-01', '2020-06-05')
Data Type
for row in c.execute('SELECT * FROM 도서대출내역2;'):
print(row)('101', '문강태', '2020-06', '20일')
('102', '고문영', '2020-06', '10일')
('103', '문상태', '2020-06', '8일')
('104', '강기둥', '2020-06', '3일')
평균 대출일수를 구하기 위해서는 대출일수가 int로 변경할 필요가 있습니다.
import os
db_path = os.getenv('HOME')+'/mydb.db'
conn = sqlite3.connect(db_path) # mydb.db에 연결합니다.
c = conn.cursor()
for row in c.execute('pragma table_info(도서대출내역)'):
print(row)(0, 'ID', 'varchar', 0, None, 0)
(1, '이름', 'varchar', 0, None, 0)
(2, '도서ID', 'varchar', 0, None, 0)
(3, '대출일', 'varchar', 0, None, 0)
(4, '반납일', 'varchar', 0, None, 0)
데이터 타입을 보니 모두 VARCHAR로 되어 있네요. 그럼 '문자형'입니다.
SUBSTRING 함수를 이용해서 일을 뻅니다.
for row in c.execute('SELECT *, SUBSTR(대출일수, 1, (length(대출일수)-1)) AS 대출일수_수정 FROM 도서대출내역2;'):
print(row)('101', '문강태', '2020-06', '20일', '20')
('102', '고문영', '2020-06', '10일', '10')
('103', '문상태', '2020-06', '8일', '8')
('104', '강기둥', '2020-06', '3일', '3')
CAST 함수를 이용하여, 잘라낸 부분에 더하여 숫자로 변환해 보겠습니다.
for row in c.execute('SELECT *, CAST(SUBSTR(대출일수, 1, (length(대출일수)-1)) AS INT) AS 대출일수_수정 FROM 도서대출내역2 ;'):
print(row)('101', '문강태', '2020-06', '20일', 20)
('102', '고문영', '2020-06', '10일', 10)
('103', '문상태', '2020-06', '8일', 8)
('104', '강기둥', '2020-06', '3일', 3)
대출일수_수정' 컬럼의 평균을 구해보겠습니다.
for row in c.execute('SELECT ID, 이름, 대출년월, AVG(CAST(SUBSTR(대출일수, 1, (length(대출일수)-1)) AS INT)) AS 대출일수_평균 FROM 도서대출내역2 GROUP BY 1,2;'):
print(row)('101', '문강태', '2020-06', 20.0)
('102', '고문영', '2020-06', 10.0)
('103', '문상태', '2020-06', 8.0)
('104', '강기둥', '2020-06', 3.0)
다양한 조건으로 조회하기
WHERE 조건에 다양한 조건 입력하기
기본 형태
SELECT * FROM 도서대출내역2 WHERE ~
조건을 더한 형태
SELECT * FROM 도서대출내역2 WHERE 조건1 AND 조건2 AND 조건3 AND (조건 4 OR 조건5);
예제를 통해, WHERE 조건절 안에서 쓸 수 있는 몇 가지를 살펴보겠습니다.
-
특정 문자를 포함하는 row를 가져오고 싶을 때
-
특정 기간 혹은 특정 날짜의 전 또는 이후의 row를 가져오고 싶을 때
-
특정 숫자 이상 또는 이하의 row를 가져오고 싶을 때
1. 특정 문자를 포함하는 row를 가져오고 싶을 때
for row in c.execute('SELECT * FROM 도서대출내역2 WHERE 이름 LIKE "문%" ;'):
print(row)('101', '문강태', '2020-06', '20일')
('103', '문상태', '2020-06', '8일')
- "문%"은 '문'으로 시작하는 모든 문자열을 다 가져오라는 명령이 됩니다.
- '%문%'으로 조회를 한다면 이름의 시작, 중간, 끝의 어딘가에 '문'이 존재한다면 모두 가져오라는 명령이 됩니다.
- '%문'으로 조회한다면 어떨까요? '문'으로 끝나는 모든 문자열을 다 가져오라는 명령이 됩니다.
2. 특정 기간 혹은 특정 날짜의 이전 또는 이후의 row를 가져오고 싶을 때
for row in c.execute('SELECT * FROM 도서대출내역 WHERE 대출일 >= "2020-06-01" AND 대출일 <= "2020-06-07" ;'):
print(row)('101', '문강태', 'aaa', '2020-06-01', '2020-06-05')
('102', '고문영', 'bbb', '2020-06-01', None)
('103', '문상태', 'ccc', '2020-06-01', '2020-06-05')
BETWEEN이라는 함수를 활용할 수도 있습니다.
for row in c.execute('SELECT * FROM 도서대출내역 WHERE 대출일 BETWEEN "2020-06-01" AND "2020-06-07" ;'):
print(row)('101', '문강태', 'aaa', '2020-06-01', '2020-06-05')
('102', '고문영', 'bbb', '2020-06-01', None)
('103', '문상태', 'ccc', '2020-06-01', '2020-06-05')
특정 숫자 이상 또는 이하의 row를 조회하고 싶을 때
for row in c.execute('SELECT *, CAST(SUBSTR(대출일수, 1, (length(대출일수)-1)) AS INT) AS 대출일수_수정 FROM 도서대출내역2 WHERE 대출일수_수정 > 5 '):
print(row)('101', '문강태', '2020-06', '20일', 20)
('102', '고문영', '2020-06', '10일', 10)
('103', '문상태', '2020-06', '8일', 8)
NULL 조건을 다루는 방법
- 테이블을 조회하다 보면 NULL만 가져오고 싶거나 NULL을 제외하고 가져오고 싶은 경우가 있을 텐데요. 그럴 때도 WHERE 조건절을 활용하면 됩니다.
for row in c.execute('SELECT * FROM 도서대출내역 WHERE 반납일 IS NOT NULL;'):
print(row)('101', '문강태', 'aaa', '2020-06-01', '2020-06-05')
('101', '문강태', 'ccc', '2020-06-20', '2020-06-25')
('103', '문상태', 'ccc', '2020-06-01', '2020-06-05')
반납일이 NULL이라는 것은 미반납 상태 또는 반납일에 대한 정보가 없다는 뜻일 테니, NULL이 아닌 상태는 반납을 한 사람들을 의미하겠네요.
for row in c.execute('SELECT * FROM 도서대출내역 WHERE 반납일 IS NULL;'):
print(row)('102', '고문영', 'bbb', '2020-06-01', None)
('102', '고문영', 'ddd', '2020-06-08', None)
('104', '강기둥', None, None, None)
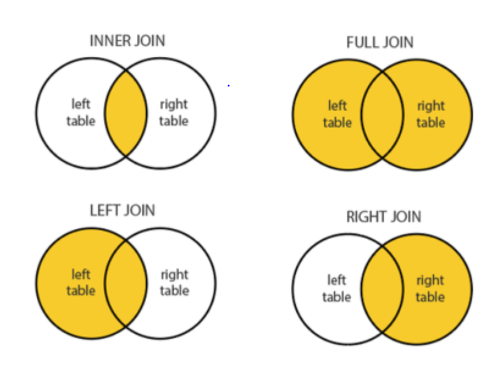
JOIN 수행하기
import os
db_path = os.getenv('HOME')+'/mydb.db'
conn = sqlite3.connect(db_path) # mydb.db에 연결합니다.
c = conn.cursor()- INNER JOIN : A 테이블과 B 테이블의 교집합을 조회
- LEFT JOIN : (기준은 A 테이블) A 테이블을 기준으로 해서 B 테이블은 공통되는 부분만 조회
- RIGHT JOIN : (기준은 B 테이블) B 테이블을 기준으로 해서 A 테이블은 공통되는 부분만 조회
- FULL JOIN : A 테이블과 B 테이블 모두에서 빠트리는 부분 없이 모두 조회
print('대출내역 테이블')
for row in c.execute('SELECT * FROM 대출내역;'):
print(row)
print('')
print('도서명 테이블')
for row in c.execute('SELECT * FROM 도서명;'):
print(row)대출내역 테이블
('101', '문강태', 'aaa')
('102', '고문영', 'bbb')
('102', '고문영', 'fff')
('103', '문상태', 'ccc')
('104', '강기둥', None)
도서명 테이블
('aaa', '악몽을 먹고 자란 소년')
('bbb', '좀비아이')
('ccc', '공룡백과사전')
('ddd', '빨간구두')
('eee', '잠자는 숲속의 미녀')
JOIN의 기본 구문
SELECT 컬럼1, 컬럼2, 컬럼3... FROM A테이블 AS A {INNER/LEFT/RIGHT/FULL OUTER} JOIN B테이블 AS B ON A.결합컬럼 = B.결합컬럼 WHERE ~
1) INNER JOIN
- INNER JOIN은 두 테이블의 교집합을 뱉어주는 명령어였습니다.
query = '''
SELECT A.*, B.도서명
FROM 대출내역 AS A
INNER JOIN 도서명 AS B
ON A.도서ID = B.도서ID;
'''
for row in c.execute(query):
print(row)('101', '문강태', 'aaa', '악몽을 먹고 자란 소년')
('102', '고문영', 'bbb', '좀비아이')
('103', '문상태', 'ccc', '공룡백과사전')
2) LEFT JOIN
query = '''
SELECT A.*, B.도서명
FROM 대출내역 AS A
LEFT JOIN 도서명 AS B
ON A.도서ID = B.도서ID;
'''
for row in c.execute(query):
print(row)('101', '문강태', 'aaa', '악몽을 먹고 자란 소년')
('102', '고문영', 'bbb', '좀비아이')
('102', '고문영', 'fff', None)
('103', '문상태', 'ccc', '공룡백과사전')
('104', '강기둥', None, None)
3) 중첩 질의(Nested Query)
query = '''
SELECT C.이름, COUNT(*) 대출건수
FROM (
SELECT A.*, B.도서명
FROM 대출내역 AS A
LEFT JOIN 도서명 AS B
ON A.도서ID = B.도서ID ) C
GROUP BY C.이름;
'''
for row in c.execute(query):
print(row)('강기둥', 1)
('고문영', 2)
('문강태', 1)
('문상태', 1)
4) 쿼리의 조건절(1) IFNULL
- NULL 대신 다른 값으로 바꾸어 출력하고 싶으면 어떻게 하면 좋을까요? 이 때 사용되는 것이 IFNULL(값1, 값2) 입니다. 이 함수는 값1 항목이 NULL인지 체크해서 NULL이면 값2를 대신, 이외의 경우에는 값1을 그대로 리턴하는 것입니다
query = '''
SELECT A.*, IFNULL(B.도서명, '도서명미상') AS 도서명
FROM 대출내역 AS A
LEFT JOIN 도서명 AS B
ON A.도서ID = B.도서ID;
'''
for row in c.execute(query):
print(row)('101', '문강태', 'aaa', '악몽을 먹고 자란 소년')
('102', '고문영', 'bbb', '좀비아이')
('102', '고문영', 'fff', '도서명미상')
('103', '문상태', 'ccc', '공룡백과사전')
('104', '강기둥', None, '도서명미상')
5) 쿼리의 조건절(2) CASE
- CASE문은 마치 프로그래밍에서의 IF문처럼 조건에 따라 다양한 출력이 가능하도록 해주는 매우 강력하고 유용한 함수입니다. 위에서는 대출일수가 5일 초과냐 아니냐에 따라 출력이 달라지도록 하는 IF문과 같은 기능을 보여주고 있습니다.
query = '''
SELECT 이름,
CASE WHEN 대출일수_수정 > 5
THEN '기간초과'
ELSE '기간내'
END AS 대출기간
FROM (
SELECT *, CAST(SUBSTR(대출일수, 1, (length(대출일수)-1)) AS INT) AS 대출일수_수정
FROM 도서대출내역2
);
'''
for row in c.execute(query):
print(row)('문강태', '기간초과')
('고문영', '기간초과')
('문상태', '기간초과')
('강기둥', '기간내')
