자신의 사진과 비슷한 연예인을 찾아주는 알고리즘을 만듭니다!
작동 원리 및 순서
먼저할 것
- 연예인 사진들을 각 pc에 저장합니다.
- 본인 사진도 포함합니다.
코드 순서
- 자신이 넣어둔 이미지가 잘 불러와지는지 list를 확인하고 이미지도 확인합니다.
- face_recognition 패키지를 이용해서 사진의 얼굴만 캡쳐를 하여 cropped_face로 저장하는 함수를 생성합니다.
- face_recognition.face_encodings함수를 이용하여 이미지를 벡터값으로 변환합니다.
- 벡터값으로 변환된 이미지를 딕셔너리에 {이름 : 벡터값}형식으로 반복문을 통해 모든 이미지를 저장 합니다.
- 벡터값을 가진 이미지간의 차이를 넘파이 특성을 이용하여 계산합니다.
- 본인 이미지를 연예인이미지 마다 차를 낸 결과로 정렬을 하면 가장 비슷한 이미지가 맨 위로 올라오는 함수를 생성합니다.
- 그 결과를 바탕으로 5순위를 얻고 싶다면 5로 설정하여 비슷한 연예인이 누구인지 추출합니다.
이미지를 벡터로 표현한다는 느낌은 이래 사진과 같습니다.
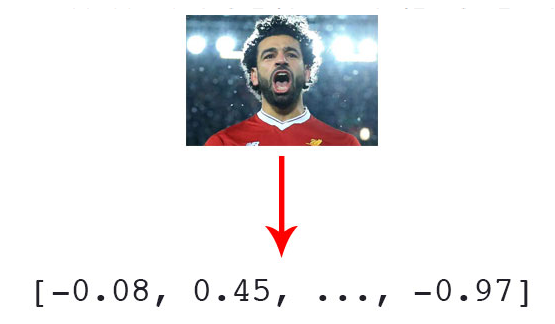
이미지에서 얼굴을 가지고오는 방식은 어떨까요?
아래 사진처럼 이미 다른 똑똑하신 분들이 만들어둔 알고리즘을 이용하여 얼굴부분만 추출합니다
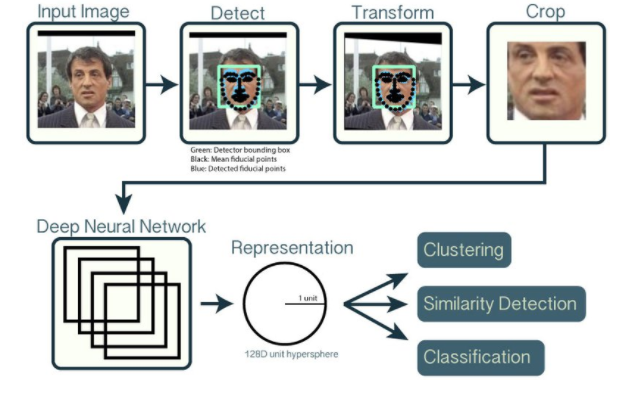
벡터값을 구하면 그 차이는 어떤식으로 구할까요?
- 유클리드 거리를 이용해서 이미지의 벡터값들 간의 차이를 구합니다!
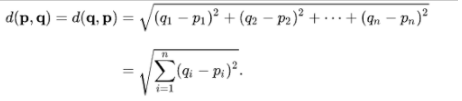
import os
import matplotlib.pyplot as plt
import matplotlib.image as img
import face_recognition
import os
import matplotlib.pyplot as plt
import numpy as np샘플이미지들이 어떤 이미지인지 확인합니다.
dir_path = os.getenv('HOME')+'/aiffel/imagecompare'
file_list = os.listdir(dir_path)
print ("file_list: {}".format(file_list))
#Set figsize here
fig, axes = plt.subplots(nrows=2, ncols=3, figsize=(24,10))
# flatten axes for easy iterating
for i, ax in enumerate(axes.flatten()):
image = img.imread(dir_path+'/'+file_list[i])
ax.imshow(image)
plt.show()
fig.tight_layout()얼굴을 잘라주는 함수를 생성합니다.
def get_cropped_face(image_file):
image = face_recognition.load_image_file(image_file)
face_locations = face_recognition.face_locations(image)
a, b, c, d = face_locations[0]
cropped_face = image[a:c,d:b,:]
return cropped_face잘 만들어졌는지 확인해봅니다
mage_path = os.getenv('HOME')+'/aiffel/imagecompare/강민경.jpg'
cropped_face = get_cropped_face(image_path)
plt.imshow(cropped_face)file list에 어떤것들이 있는지 확인해봅니다.
dir_path = os.getenv('HOME')+'/aiffel/imagecompare'
file_list = os.listdir(dir_path)
print ("file_list: {}".format(file_list))이미지에 embedding을 encodings을 통해 벡터값으로 변환시킵니다.
def get_face_embedding(face):
return face_recognition.face_encodings(face)위에서 불러왔던 강민경님 사진으로 벡터값으로 잘 변환했는지 확인합니다
get_face_embedding(cropped_face)LIST에 있는 사진들을 embedding을 통해 벡터값을 구하고 DICT에 저장하는 함수를 만든 뒤 실행을 하겠습니다.
- 함수 실행 후 딕셔너리에 저장이 잘 된지 확인하기 위해 강민경님을 검색해보겠습니다.
이때 image_dict라는 딕셔너리로도 따로 저장합니다. 그 이유는 벡터값으로 변경된 값외에 원래 0~255값을 가지는 값을 보존하고 있어야 나중에 순위에 맞게 이미지를 생성할 때 유용하게 사용할 수 있습니다
def get_face_embedding_dict(dir_path):
file_list = os.listdir(dir_path)
embedding_dict = {}
image_dict={}
for file in file_list:
img_path = os.path.join(dir_path, file)
face = get_cropped_face(img_path)
embedding = get_face_embedding(face)
if len(embedding) > 0:
# 얼굴영역 face가 제대로 detect되지 않으면 len(embedding)==0인 경우가 발생하므로
# os.path.splitext(file)[0]에는 이미지파일명에서 확장자를 제거한 이름이 담깁니다.
embedding_dict[os.path.splitext(file)[0]] = embedding[0]
image_dict[os.path.splitext(file)[0]]=face
return embedding_dict, image_dict
dir_path = os.getenv('HOME')+'/aiffel/imagecompare'
embedding_dict, image_dict = get_face_embedding_dict(dir_path)
embedding_dict['강민경']image_dict['개리']지금까지 과정으로 함수를 통해 얼굴기반으로 딕셔너리에 이름 : 벡터로 저장되는 것을 알 수 있습니다.
각 사진을 비교하는 함수를 만듭니다.
def get_distance(name1, name2):
return np.linalg.norm(embedding_dict[name1]-embedding_dict[name2], ord=2)
print(get_distance('본인이름1', '본인이름2'))
fig = plt.figure(figsize=(15,5))
fig.add_subplot(2,2,1)
plt.imshow(image_dict['본인이름1'])
fig.add_subplot(2,2,2)
plt.imshow(image_dict['본인이름2'])제 얼굴 사진을 두개 넣었는데 두 사진의 비슷한 정도는 0.4079정도 인가 봅니다.ㅎㅎ 살이 쪄서 그런가,, ㅎㅎ
어쨋든 두 사진을 비교하는데 하나의 대표사진은 고정하고 다른 사진들과 하나하나 비교하면서 값을 호출하도록 합니다.
def get_sort_key_func(name1):
def get_distance_from_name1(name2):
return get_distance(name1, name2)
return get_distance_from_name1
sort_key_func = get_sort_key_func('본인이름1')앞에서 만든 코드를 이용하여 순위를 보겠습니다!
- 제 사진을 두개 넣었기 때문에 0, 1 은 제외했습니다.
- 각 순위별 사진이 나오게 합니다.
def get_nearest_face(name, top=5):
sort_key_func = get_sort_key_func(name)
sorted_faces = sorted(embedding_dict.items(), key=lambda x:sort_key_func(x[0]))
fig = plt.figure(figsize=(15,5))
for i in range(top+2):
if i == 0 :
continue
if i == 1 :
continue
if sorted_faces[i]:
print('순위 {} : 이름({}), 거리({})'.format(i-1, sorted_faces[i][0], sort_key_func(sorted_faces[i][0])))
fig.add_subplot(2,top,i-1)
plt.imshow(image_dict[sorted_faces[i][0]])
print('-------------------------')
print('1순위 -->5순위 순서입니다.')facecc=get_nearest_face('본인이름1')순위 1 : 이름(김광현), 거리(0.4760238801780991)
순위 2 : 이름(김희철), 거리(0.4901850300657218)
순위 3 : 이름(공효진), 거리(0.4945329390680399)
순위 4 : 이름(김래원), 거리(0.4949917680316656)
순위 5 : 이름(디오), 거리(0.4966492743317155)
1순위 -->5순위 순서입니다.

제 이미지 두개를 비교했을때 0.41정도였는데 다른 연예인 사진들과 비교했을 때 값이 0.47~0.49정도인 것으로 보아 꽤나 비슷하게 인식을 하는 것 같습니다. 더 많은 이미지를 넣고 진행하면 다른 사람도 나올 것 같습니다... 진행하지 않은 이유는 아래에 있습니다..ㅠㅠ
번외
위 연예인 닮은 꼴 찾기는 이미지를 하나하나 다운로드 해야하는 번거로움이 있어서 크롤링을 통해 원하는 폴더에 검색 이미지를 자동으로 저장하는 코드를 만들었으나.. 제 pc가 아닌 다른 클라우드에서 연예인 닮은 꼴 코드를 진행하다보니 크롬 드라이버를 실행할 수 없어서 못한게 아쉽네요.ㅜㅜ 제 pc에서 왜 안했는지 궁금하시겠지만 dlib이랑 face_recognition 패키지 모두 다운 받고 이미지를 벡터로 변환하는 과정에서 사이즈가 큰건지 자꾸 튕김 현상이 일어나서 못했습니다...ㅠㅠㅠ
