LSTM의 시퀀스 데이터에 강력한 알고리즘을 이용하여 문장에 대해 학습하고 처음 키워드를 던지는 것만으로도 문장을 만들어내는 과정을 진행합니다!
데이터는 lyricist 데이터를 사용하고 AIFFEL &모두연구소 에서 데이터 공유 및 코드 공유를 해주었습니다.
데이터를 불러오겠습니다.
import re
import glob
import numpy as np
import tensorflow as tf
import os
txt_file_path = os.getenv('HOME')+'/aiffel/lyricist/data/lyrics/*'
txt_list = glob.glob(txt_file_path)
raw_corpus = []
# 여러개의 txt 파일을 모두 읽어서 raw_corpus 에 담습니다.
for txt_file in txt_list:
with open(txt_file, "r") as f:
raw = f.read().splitlines()
raw_corpus.extend(raw)
print("데이터 크기:", len(raw_corpus))
print("Examples:\n", raw_corpus[:3])데이터 크기: 187088
Examples:
['[Verse 1]', 'They come from everywhere', 'A longing to be free']
문장 데이터는 항상 데이터를 분석하기 좋게 제공되지 않습니다. 그렇기 때문에 문장에 필요없는 부분은 정제나 전처리를 해줘야 합니다. 아래 코드는 문장이 없으면 건너뛰고 ':'기호가 있으면 건너뛰는 코드입니다. 확인용 코드이며 아직 전처리한 코드는 아닙니다.
for idx, sentence in enumerate(raw_corpus):
# 길이가 0이면 패스
if len(sentence) == 0: continue
# 문장의 끝이 :이면 패스
if sentence[-1] == ":": continue
#10개 문장만 먼저 보겠습니다.
if idx >9: break
print(sentence)[Verse 1]
They come from everywhere
A longing to be free
They come to join us here
From sea to shining sea And they all have a dream
As people always will
To be safe and warm
In that shining city on the hill Some wanna slam the door
Instead of opening the gate
Aw, let's turn this thing around
문장을 불러오면 단계별로 수행을 합니다.
- 소문자로 모두 변경하고 양쪽 공백은 지웁니다.
- 특수문자 양쪽에는 공백을 추가합니다.
- 공백이 많을 수 있는 부분에는 하나의 공백으로 통일합니다.
- ""안에 들어가있는 기호들 외에 공백으로 바꿉니다.
- 다시 양쪽 공백을 지웁니다.
- 문장 시작과 끝에 <start>와 <end>를 추가합니다.
- 이정도면 문장의 전처리를 어느정도 수행했다고 생각합니다!
def preprocess_sentence(sentence):
#일단 모두 소문자로 변환하고 양쪽 공백을 지웁니다.
sentence = sentence.lower().strip()
# 아래 특수문자 기호 양쪽에 공백을 추가합니다.
sentence = re.sub(r"([?.!,¿])", r" \1 ", sentence)
# 공백이 많을 수 있는 부분에는 하나의 공백으로 통일합니다.
sentence = re.sub(r'[" "]+', " ", sentence)
# ""안에 들어가있는 기호들 외에 공백으로 바꿉니다.
sentence = re.sub(r"[^a-zA-Z?.!,¿]+", " ", sentence)
#다시 양쪽 공백을 지웁니다.
sentence = sentence.strip()
# 문장 시작과 끝에 start와 end 를 추가합니다.
sentence = '<start> ' + sentence + ' <end>'
return sentence
# 아래 같이 결측치 투성이인 문장이 어떻게 변하는지 확인합니다.
print(preprocess_sentence("This @_is ;;;sample sentence."))this is sample sentence .
corpus라는 폴더를 생성하여 문장이 없거나 ':'를 가진 문장은 넘기고 저장을 진행 합니다. 아까 위에서 잠깐 확인했던 코드를 진행하는 것이고 저장할 때 preprocess_sentence에 만들어준 문장 전처리 과정을 지나며 저장을 진행 합니다.
corpus = []
for sentence in raw_corpus:
if len(sentence) == 0: continue
if sentence[-1] == ":": continue
corpus.append(preprocess_sentence(sentence))
corpus[:10][' verse ',
' they come from everywhere ',
' a longing to be free ',
' they come to join us here ',
' from sea to shining sea and they all have a dream ',
' as people always will ',
' to be safe and warm ',
' in that shining city on the hill some wanna slam the door ',
' instead of opening the gate ',
' aw , let s turn this thing around ']
결과를 보니 문장들을 전처리한 이후 따로 더 필요한 전처리는 없어보입니다.
단어별로 토근화 할 필요가 있습니다. 컴퓨터는 문장을 문장으로보지않고 숫자로 봐야하기 때문에 토큰화 라는것을 해야하는데 토큰화 라고 하면 단어 하나에 숫자를 매칭시켜주는 개념입니다.
- 예를 들면 I = 0 , love = 1, you = 2
def tokenize(corpus):
# 텐서플로의 토크마이저를 이용해서 7000개 단어 개수를 숫자로 바꿔줍니다.
tokenizer = tf.keras.preprocessing.text.Tokenizer(
# 전체 단어의 개수
num_words=7000,
#이 함수에서 제공하는 문장 전처리 (하지만 우린 이미 진행해서 사용안함)
filters=' ',
#7000단어에 속하지 않으면 unk로 바꿔숩니다.
oov_token="<unk>"
)
#위에서 만든 문장을 토크마이저에 넣어 데이터를 구축합니다.
tokenizer.fit_on_texts(corpus)
tensor = tokenizer.texts_to_sequences(corpus)
#문장의 길이를 맞추고 숫자로 반환하기 위해 작업을 합니다.
# 문장의 길이는 가장 긴 문장을 기준으로 pandding합니다.
#여기서 maxien을 설정해 주었는데 이상치에 대응하기 할 수 있다고 합니다.
total_data_text = list(tensor)
num_tokens = [len(tokens) for tokens in total_data_text]
max_tokens = np.mean(num_tokens) + 2 * np.std(num_tokens)
maxlen = int(max_tokens)
tensor = tf.keras.preprocessing.sequence.pad_sequences(tensor,
padding='post',
maxlen=maxlen)
print(tensor,tokenizer)
return tensor, tokenizer
tensor, tokenizer = tokenize(corpus)[[ 2 520 3 ... 0 0 0][ 2 45 66 ... 0 0 0]
[ 2 9 3390 ... 0 0 0]
...
[ 2 561 21 ... 0 0 0][ 2 120 34 ... 0 0 0]
[ 2 5 22 ... 0 0 0]] <keras_preprocessing.text.Tokenizer object at 0x7fcb586d04d0>
위에서 토크마이저는 I = 0 , love = 1, you = 2 와같이 변한다고 했습니다. 진짜 그렇게 변했는지 확인해 보겠습니다.
for idx in tokenizer.index_word:
print(idx, ":", tokenizer.index_word[idx])
if idx > 9: break1 :
2 :
3 :
4 : ,
5 : i
6 : the
7 : you
8 : and
9 : a
10 : to
LSTM에서 many to many의 답을 얻을 것이기 때문에 train은 첫 문장부터 끝에 하나뺀 문장들로 구성을 하고 target은 첫 단어 뺀 문장들로 구성을 합니다,
#마지막 토큰을 잘라냅니다. 위에서 end라고 설정했지만 문장 길이 상 pad인 것이 많을 것입니다.
src_input = tensor[:, :-1]
#앞에 start부분을 자릅니다.
tgt_input = tensor[:, 1:]
print(src_input[0])
print(tgt_input[0])[ 2 520 3 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0][520 3 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0]
사이킷 런 패키지를 이용해서 위에서 train과 target을 train과 validation 셋으로 분리를 해줍니다. 8:2로 분리를 하겠습니다.
from sklearn.model_selection import train_test_split
enc_train, enc_val, dec_train, dec_val = train_test_split(src_input,
tgt_input,
test_size=0.2,
shuffle=True,
random_state=34)train의 맨 뒷 단어를 뺀 문장을 분석해서 앞 단어가 없는 target을 찾는것이 목적이기 때문에 shape는 동일한 모습을 하고있습니다.
print('Source Train: ', enc_train.shape)
print('Target Train: ', dec_train.shape)Source Train: (140599, 19)
Target Train: (140599, 19)
모델을 형성해보겠습니다.
keras를 이용할 것이며 embedding과 lstm, dence를 통해 분석을 진행합니다. lstm은 시퀀스 데이터 분석에 적합한 알고리즘이기 때문에 적절한 분석결과를 보여줄 것이라고 생각합니다. 그리고 lstm의 모델 특성상 분석시간이 많이 걸립니다... 빠르게 처리하고 싶은 사람은 lstm의 한줄을 지워서 2단을 1단으로 해서 분석해도 좋은 결과를 보일 것 입니다.
from tensorflow.keras.layers import Embedding, LSTM, Dense한 문장 당 19단어를 가지고 있기 때문에 embedding을 19로 설정을 하였고 여기서는 hidden_size를 2048로 설정했지만 실제로는 512부터 해가지고 여러 시도가 이뤄졌었습니다... 시간이 너무 오래걸리기도 하고 만족스런 답을 얻기 까지 많은 시간이 걸렸습니다.
epochs도 10만 설정해도 충분히 loss값이 2.2 이하로 떨어지기 때문에 작게 설정했고 초기에 earlystopping의 함수를 이용했는데 의미가 없다는 것을 알고 지웠습니다.
class TextGenerator(tf.keras.Model):
def __init__(self, vocab_size, embedding_size, hidden_size):
super(TextGenerator, self).__init__()
self.embedding = Embedding(vocab_size, embedding_size)
self.rnn_1 = LSTM(hidden_size, return_sequences=True)
self.rnn_2 = LSTM(hidden_size, return_sequences=True)
self.linear = Dense(vocab_size)
def call(self, x):
out = self.embedding(x)
out = self.rnn_1(out)
out = self.rnn_2(out)
out = self.linear(out)
return out
#문장을 토큰으로 했을 때 19이므로 19로 구성했습니다.
embedding_size = 19
hidden_size = 2048
#여기서 tokenizer.num_words + 1를 했는데 그 이유는 문장에 없는 pad 가 넣어졌기 때문입니다.
#문장길이를 모두 통일 하기 위해 가장 긴문장 말고는 모든 토큰이 0으로 들어간 부분 때문입니다.
model = TextGenerator(tokenizer.num_words + 1, embedding_size , hidden_size)
history = []
epochs = 10
optimizer = tf.keras.optimizers.Adam()
loss = tf.keras.losses.SparseCategoricalCrossentropy(
from_logits=True,
reduction='none'
)
model.compile(loss=loss, optimizer=optimizer)모델 구축하고 모델의 summary를 확인하기 위해 하나의 데이터만 model에 넣어 summary를 확인합니다.
BUFFER_SIZE = len(src_input)
BATCH_SIZE = 256
steps_per_epoch = len(src_input) // BATCH_SIZE
VOCAB_SIZE = tokenizer.num_words + 1
dataset = tf.data.Dataset.from_tensor_slices((src_input, tgt_input))
dataset = dataset.shuffle(BUFFER_SIZE)
dataset = dataset.batch(BATCH_SIZE, drop_remainder=True)for src_sample, tgt_sample in dataset.take(1): break
# 한 배치만 불러온 데이터를 모델에 넣어봅니다
model(src_sample)모델에 넣어 보고 summary를 확인해 보겠습니다.
model.summary()
summary를 보면 알겠지만 params의 수는 어마어마 합니다. lstm의 특성상 모델이 무겁기도 하고 이렇게 많은 데이터를 분석하는데 시간이 오래 걸리는 건 당연한 것 같습니다.
모델을 적용해보겠습니다.
epochs는 여러번 모델을 학습한 경험으로 10이면 충분했고 batch_size는 64여도 충분히 좋은 결과였지만 더 좋은 loss값을 얻기 위해 높게 잡았습니다. 또한 아까 8:2로 나눈 train과 validation을 넣은 모습입니다.
history = model.fit(enc_train,
dec_train,
epochs=epochs,
batch_size=256,
validation_data=(enc_val, dec_val),
verbose=1)Epoch 10/10
550/550 [==============================] - 551s 1s/step - loss: 1.4230 - val_loss: 1.9066
loss 값은 충분히 1.9까지 내려간 모습을 보여줍니다. epoch가 10으로 설정해도 충분히 loss가 내려갑니다. 사실 모델의 구축도 그렇고 batch_size도 그렇고 이렇게 과적합을 시키고 같은 데이터 끼리 train validation을 나눠서 분석을 진행 했기 때문에 전혀 다른 문장을 얻고자 할 때는 강력한 모델이 될거라고 생각하기는 어렵네요.. 여쨋든 문장을 분석할 수 있는 알고리즘이 있다는 것만으로도 참 신기합니다.
모델 결과를 바탕으로 키워드를 입력할 때 어떤 답을 반환하는지 확인해보겠습니다
def generate_text(model, tokenizer, init_sentence="<start>", max_len=20):
# 테스트를 위해서 입력받은 init_sentence도 일단 텐서로 변환합니다.
test_input = tokenizer.texts_to_sequences([init_sentence])
test_tensor = tf.convert_to_tensor(test_input, dtype=tf.int64)
end_token = tokenizer.word_index["<end>"]
# 텍스트를 실제로 생성할때는 루프를 돌면서 단어 하나씩 생성해야 합니다.
while True:
predict = model(test_tensor) # 입력받은 문장의 텐서를 입력합니다.
predict_word = tf.argmax(tf.nn.softmax(predict, axis=-1), axis=-1)[:, -1] # 우리 모델이 예측한 마지막 단어가 바로 새롭게 생성한 단어가 됩니다.
# 우리 모델이 새롭게 예측한 단어를 입력 문장의 뒤에 붙여 줍니다.
test_tensor = tf.concat([test_tensor, tf.expand_dims(predict_word, axis=0)], axis=-1)
# 우리 모델이 <END>를 예측하지 않았거나, max_len에 도달하지 않았다면 while 루프를 또 돌면서 다음 단어를 예측해야 합니다.
if predict_word.numpy()[0] == end_token: break
if test_tensor.shape[1] >= max_len: break
generated = ""
# 생성된 tensor 안에 있는 word index를 tokenizer.index_word 사전을 통해 실제 단어로 하나씩 변환합니다.
for word_index in test_tensor[0].numpy():
generated += tokenizer.index_word[word_index] + " "
return generated # 이것이 최종적으로 모델이 생성한 자연어 문장입니다.generate_text(model, tokenizer, init_sentence="<start> i love", max_len=20)' i love you , i m not gonna crack '
i love 라는 키워드를 제공했더니 'i love you , i m not gonna crack'라는 답변을 받았습니다. 자동으로 형성해준 모델치고는 정확한 문법과 답을 주었습니다. - 확실히 잠깐 학습한 것으로 저보다 러블리 해졌고 영어도 잘해졌습니다..
lstm을 진행하면서 lstm을 3층으로도 쌓고 dence를 2단으로 쌓아 더 강력하게하고 정규화 기법인 drop out이나 batchnormalization 등을 사용하여 단순하게 lstm을 돌렸을 때와 비교를 해보고 싶었지만 코드를 만들어본 결과 하나하나의 epochs가 시간이 너무 오래걸리기도 하고 많은 파라미터를 처리해야 하기 때문에 메모리가 부족할 것 같아서 진행을 못한 점이 아쉽습니다. 어쨋든 간단한 lstm으로 간단한 데이터를 인풋으로 했을 때 적절한 답변을 얻는 모습을 볼 수 있었습니다. 학습시간만 조금 짧았더라면 많은 시도를 했었을 것 같은데 아쉽네요!
그리고 다른 사람의 분석을 보니 재미있는 시각화를 해서 코드를 가지고 왔습니다. 바로 loss값을 그래프로 확인하는 것 입니다.
- [https://github.com/PEBpung/Aiffel/blob/master/Project/Exploration/E11.%20%EC%9E%91%EC%82%AC%EA%B0%80%20%EC%9D%B8%EA%B3%B5%EC%A7%80%EB%8A%A5%20%EB%A7%8C%EB%93%A4%EA%B8%B0.ipynb]
import matplotlib.pyplot as plt
def plot_curve(epochs, hist, list_of_metrics):
fig, ax = plt.subplots(1,2,figsize = (12, 8))
for i in range(len(ax)):
ax[i].set_xlabel('Epochs')
ax[i].set_ylabel('Value')
for n in range(len(list_of_metrics)):
if i == 0:
y = hist[list_of_metrics[n]]
if n == 0:
ax[i].plot(epochs, y, label="train")
else:
ax[i].plot(epochs, y, label="val")
ax[i].set_title('Loss')
ax[i].legend(loc='upper right')
if n == 1:
break
else:
if n >= 2:
y = hist[list_of_metrics[n]]
if n == 2:
ax[i].plot(epochs, y, label="train")
else:
ax[i].plot(epochs, y, label="val")
ax[i].set_title('Accuracy')
ax[i].legend(loc='lower right')
plt.show()plot_curve(history.epoch, history.history, ['loss', 'val_loss'])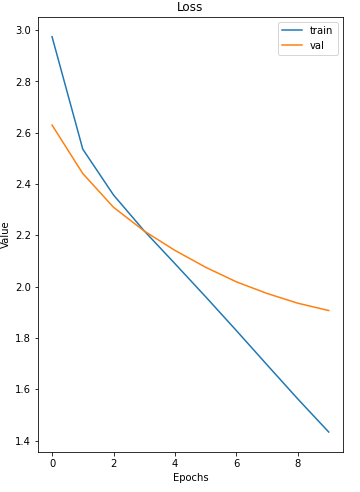
그래프를 보니 train은 학습하면 할 수록 과적합이 되서 그런지 점점 loss가 줄어드는 모습을 보입니다. 그리고 validation에서의 loss는 train의 학습으로는 한계가 있는지 점점 loss가 줄어드는 폭이 좁아지는 것을 볼 수 있었습니다.
더 좋은 결과를 얻기 위해 어떤 과정이 남아 있을까?
- lstm의 하이퍼 파라미터를 수정 또는 층을 늘린다.
- epochs에 earlystopping을 추가하여 가장 강력할 때 멈춘다.
- 각 lstm 층마다 과적합 방지 기법을 사용한다. ( drop out, batchnormalization)
- cross validation을 사용한다.
- optimizer를 Adam말고 시퀀스 데이터에 더 적합하다고 알려진 rmsprop를 사용한다.
많은 과정이 남아있지만 여기서 마무리 하겠습니다...
- 노드를 만들어 주신 AIFFEL & 모두연구소 문성원 @dev-sngwn 님 감사합니다
궁금하니까 optimizer의 adam을 rmsprop로 바꿔서 해보고 마무리 하겠습니다.
- rmsprop를 사용해보고 싶은 이유는 시퀀스 데이터에 강력하다고 합니다. 같은 조건일때 가장 자주 사용되는 옵티마이저인 adam이랑 어떤 차이를 보이는지 확인하고 싶어졌습니다.
- adam은 여러 옵티마이저들의 장점을 모은 것이라고 하는데 자세히는 모르겠습니다..ㅎ
- 여기서 rmsprop란
- 지수평균을 사용함으로써, 무작정 g값이 커져서 기울기가 소실되지 않고, 변화량 억제의 비율은 유지시킵니다.
#문장을 토큰으로 했을 때 19이므로 19로 구성했습니다.
embedding_size = 19
hidden_size = 2048
#여기서 tokenizer.num_words + 1를 했는데 그 이유는 문장에 없는 pad 가 넣어졌기 때문입니다.
#문장길이를 모두 통일 하기 위해 가장 긴문장 말고는 모든 토큰이 0으로 들어간 부분 때문입니다.
model = TextGenerator(tokenizer.num_words + 1, embedding_size , hidden_size)
history = []
epochs = 10
optimizer = tf.keras.optimizers.Adam()
loss = tf.keras.losses.SparseCategoricalCrossentropy(
from_logits=True,
reduction='none'
)
model.compile(loss=loss, optimizer='rmsprop')
history = model.fit(enc_train,
dec_train,
epochs=epochs,
batch_size=256,
validation_data=(enc_val, dec_val),
verbose=1)Epoch 10/10
550/550 [==============================] - 563s 1s/step - loss: 1.1534 - val_loss: 1.8909
generate_text(model, tokenizer, init_sentence="<start> i love", max_len=20)' i love you baby '
rmsprop를 optimizer로 설정해본 결과 loss값이 더 좋게 나오는 것을 기대했지만 실험 의도와 다른 좋은 의미있는 결과를 받았습니다. adam이랑 rmsprop의 계산방식이 달라서 그런지 둘다 맞는 문장 표현이지만 느낌은 전혀 다릅니다. 문장을 분석하는데 있어서 원하는 답을 얻기 위해서는 optimizer도 고려해볼 필요가 있다는 것을 알게되는 실험이었습니다.
