딥러닝으로 CV 시작!
- 목 차
Current Chapter
- 컴퓨터 비전 task "상상 해보기"
- 다층 퍼셉트론(Multi-Layer-Perceptron) 구조
- CNN 이해하기 (1_Channel Convolution)
- CNN 이해하기 (3_Channel Convolution)
- CNN 이해하기 (Pooling)
later Chapter
- 심화된 CNN 구조
- Transfer Learning 이해하기
later Chapter
- Object Detection
- Segmentation
last chapter
- 모델들의 아이디어와 구조(코드)
1. 컴퓨터 비전 task "상상 해보기"
- 이미지 분류의 전체 과정
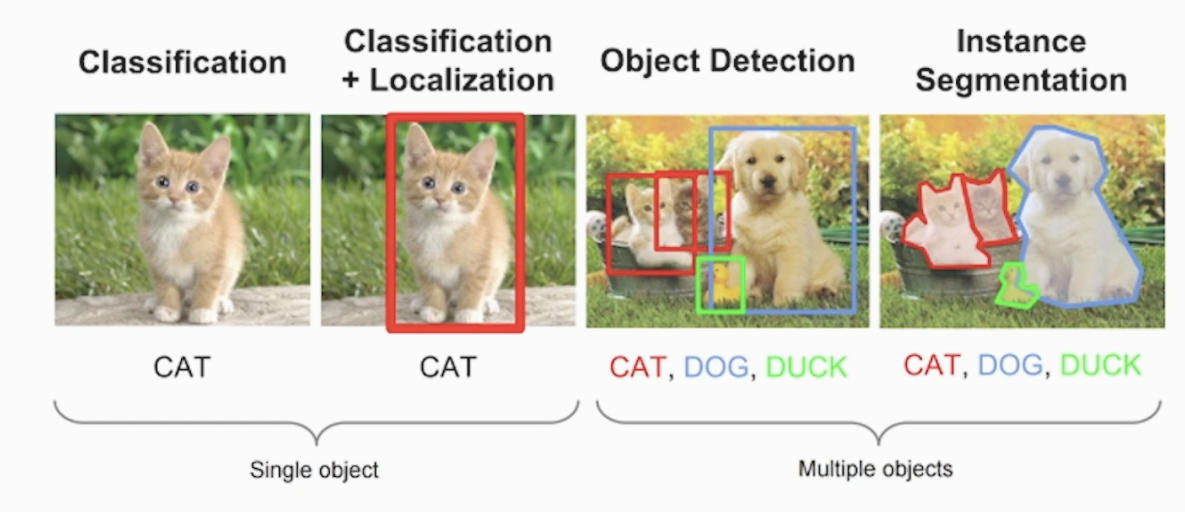
이미지는 픽셀이라는 기본 단위를 가지고 있으며 이 픽셀들의 특징(feature map)을 추출하고 주변 픽셀들의
관계를 통해 이미지 정보(feature map)을 학습 합니다
-
Classification (분류)
-
Lacalization (Box Bounding)
위 2번째 그림의 빨간색 사각형을 BBox 라고 하고 고양이를 객체(Object)라고 합니다.
Bounding Box를 통해 Object의 위치를 찾는 과정을 Localization 이라고 합니다 -
Object Detection (Multiful Object)
BB로 각 객체들을 위치별로 분류 합니다 -
Segmentation (분할)
BB로 분류만이 아닌 비선형성 도입으로 객체들을 픽셀 주변의 관계성을 분석해 영역별로 객체를 구분합니다
개별 객체(Instance 개체) 별로 영역을 분할 합니다. 뒷 내용에서 자세히 다루겠습니다
(Semantic Segmentation에 활용, Instance Segmentation)
2. 다층 퍼셉트론(Multi-Layer-Perceptron) 구조
2-1) MLP 모델 (Multi-Layer-Perceptron)
딥러닝 구조의 핵심 : 은닉층(hidden layer)들을 겹겹이 쌓아가며 깊게 쌓는 구조
<뉴런과 퍼셉트론>
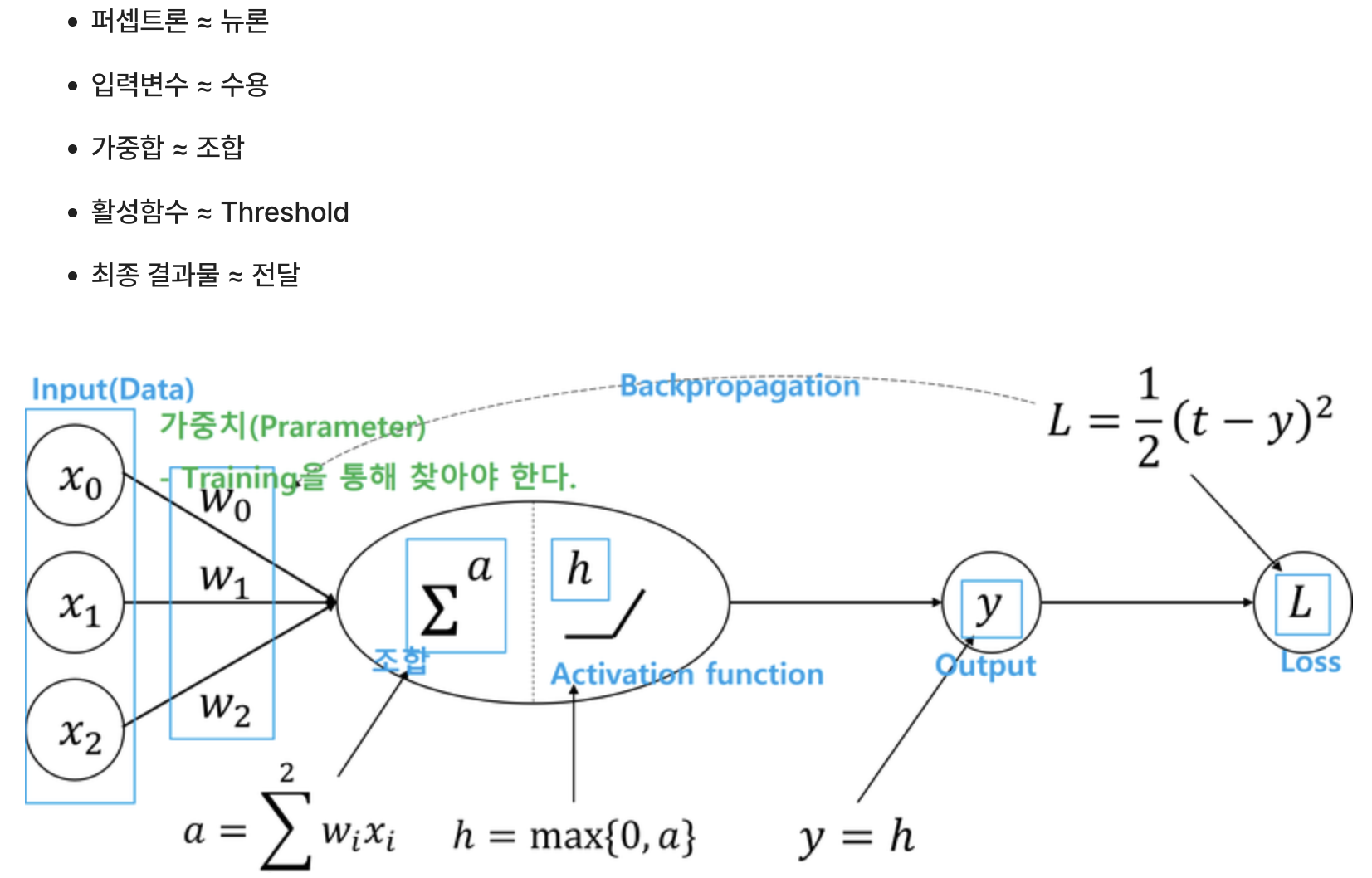
-
뉴런 : 시냅스로부터 탐지된 자극을 수상돌기(수용)를 통해 세포핵에 전달 후 역치(활성함수)를 넘어서는 자극에 대해 축색돌기를 이용하여 다른 뉴런으로 정보(전기신호)를 전달
-
퍼셉트론 : 입력변수(수용)의 값들에 대한 가중합(조합)에 대해 활성함수(threshold)를 적용하여
최종 결과물을 생성(전달)
이와 같이 매우 유사한 형태라는 것을 알 수 있습니다
<은닉층이 많아지면서 생기는 변화>
은닉층을 늘려가면서(모델이 깊어지고 복잡) 오분류를 줄여 갑니다
은닉층이 수행하는 과정을 Representation 이라고 합니다
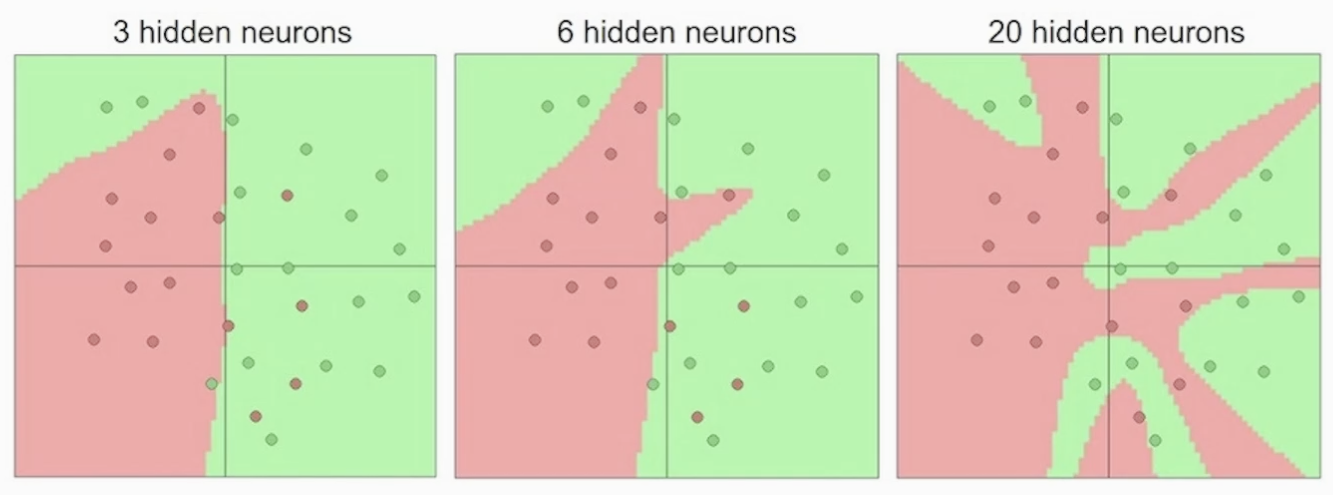
- Representation_learning의 효과는 데이터 공간 구조를 비틀고 변경하면서 데이터를 가장 잘 분류할 수 있는 공간을 선으로 구분하는 것
2-2) MLP 모델의 한계
실제로 Mnist dataset을 학습시켜보면 뒷 부분부터는 학습(fit)이 잘 안되는 것을 알 수 있습니다
<Mnist data의 구조>
2차원으로 이루어진 0~9까지의 10개 클래스를 가진 데이터
- 2차원(채널까지는 3차원) 픽셀 데이터를 784개의 1차 벡터로 만들 때 정보를 잃으면서 data와 MLP 구조가 불합치 (하나의 픽셀로는 정보를 파악할 수 없습니다. 픽셀끼리의 관계를 통해 패턴을 파악합니다)
3. CNN 이해하기 (1_Channel Convolution)
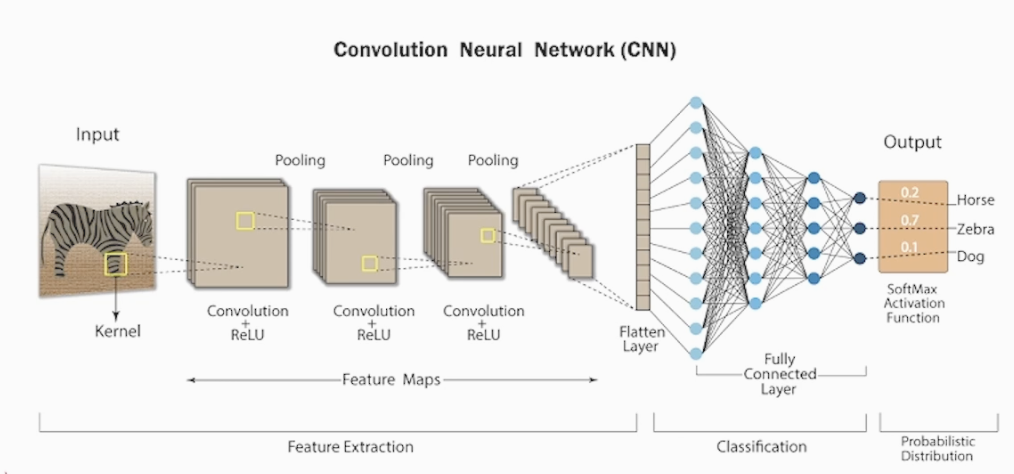
3-1) CNN (Convolution Neural Network)
1개의 채널만 갖고 있는 데이터를 통해 CNN을 먼저 이해하려 합니다
Conv2D, Pooling, 완전 연결 계층(Dense, MLP구조) 들의 Layer를 갖는 구조 입니다
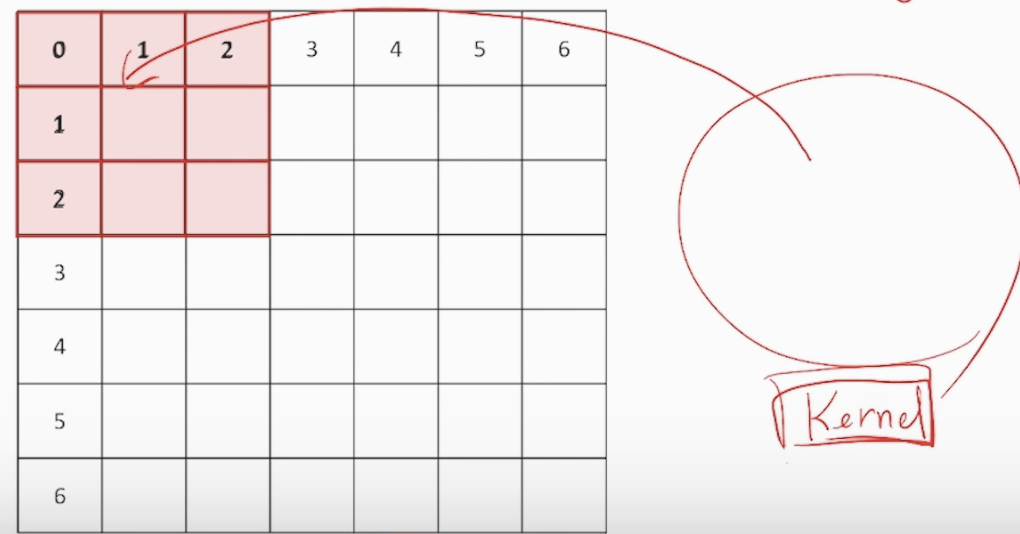
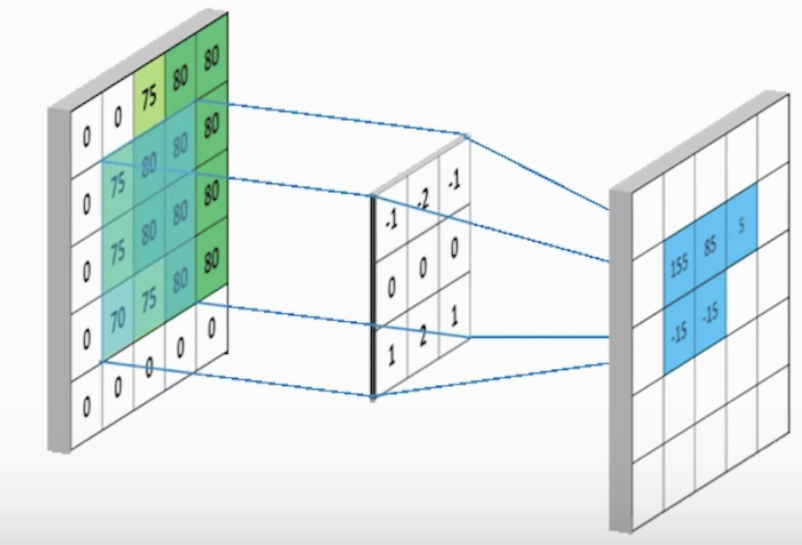
<Convolution 연산, Over-riding>
빨간 사각형을 kernel(filter)라 하고 kernel을 이미지에 덮는 과정을 Over-riding이라 합니다
오버 라이딩을 통해 겹쳐졌을 때 대응하는 원소들을 합과 곱으로 1개의 값을 구하고 stride(간격)에 맞게
이동합니다. 이 과정을 반복하며 데이터의 feature map(특징)을 추출해 냅니다
<마지막 Convolution 연산 사진>
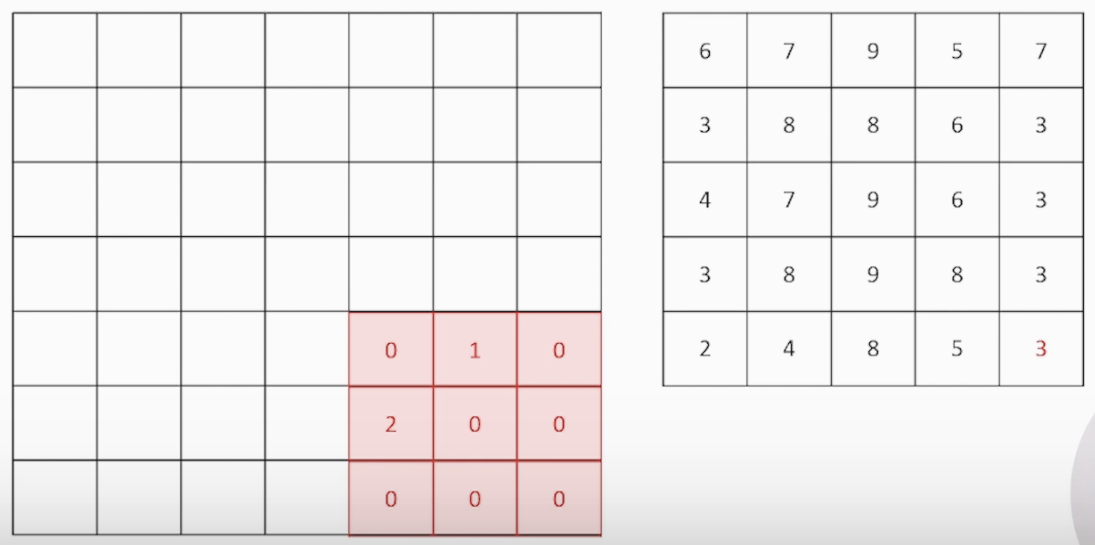
3-2) Filter 이해하기 (중요! 뒤에서 혼동 옵니다)
딥러닝 활용이전에는 사람이 직접 Filter를 직접 만들어 사용하는 Hand=Crafted filter를 사용했습니다
아래 사진과 같이 합성곱을 진행할 Filter 안에 수를 임의로 사람이 설정
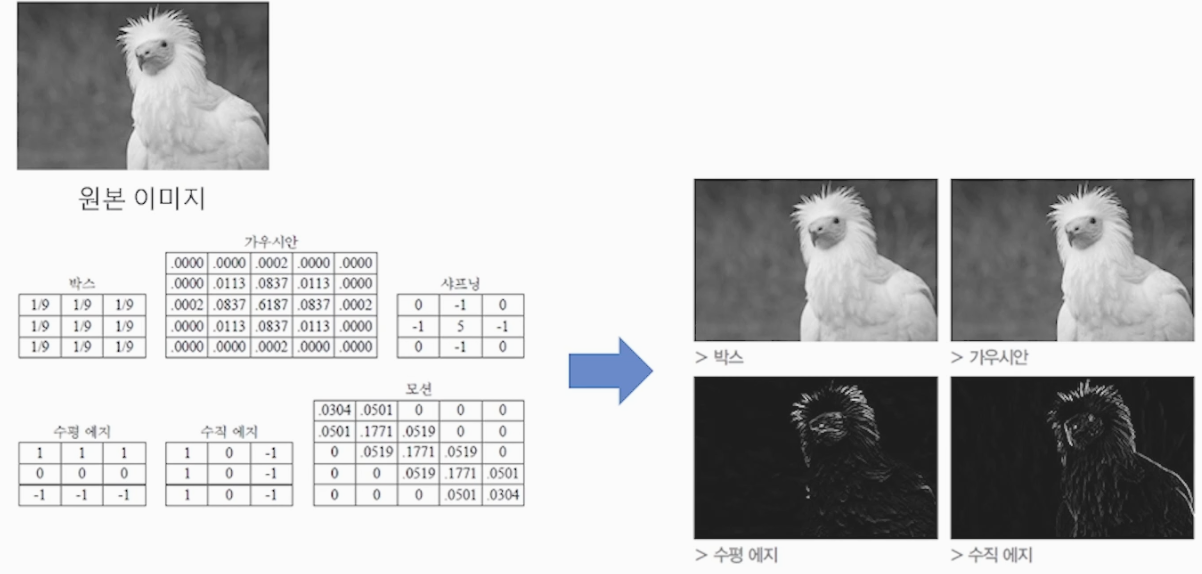
- Filter (이미지 추출기)
다양한 Filter를 통하여 Convolution 연산을 진행하며 이미지의 다양한 정보(패턴)을 추출합니다.
Convolution + Pooling(차원축소) 이 과정을 반복하여 패턴을 찾는 것을 feature extraction
이라고 합니다
3-3) Channel이 하나일 때, 2개 이상의 Layer (Padding)
위에서의 과정을 1개의 Layer에서의 과정이라면 이미지를 2개 이상의 Layer를 Convolution 연산을
진행한다면 이미지의 feature map의 사이즈가 줄어 듭니다 (다양한 패턴을 찾기 위해 레이어를 늘려야 합니다)
계속 줄어든다면 Layer를 쌓기에 한계가 있습니다. 그래서 사용하는 기법이 Padding 입니다
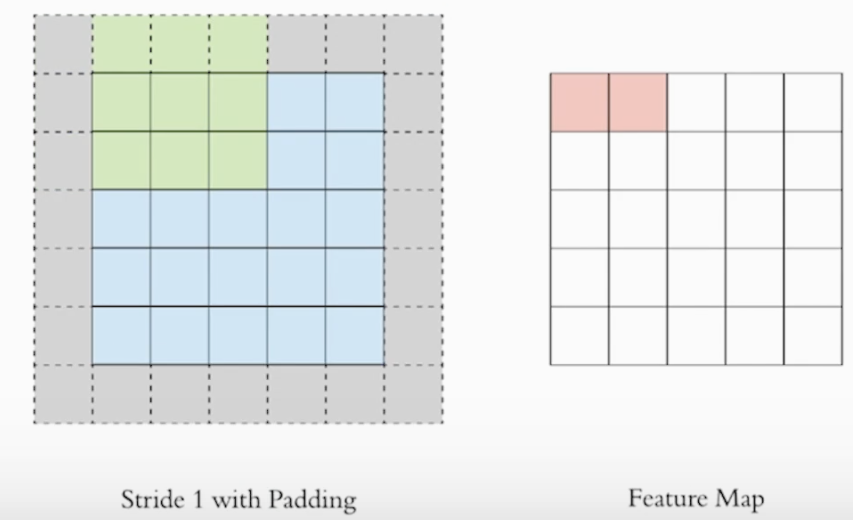
- Padding
아래 그림과 같이 외곽에 0을 채운 빈 공간을 만들어 kernel을 활용해 feature map(특징,패턴)을 추출하여도 원본 이미지의 사이즈가 줄어들지 않게 만드는 기법 입니다. 마찬가지로 이동하는 간격은 stride로 설정해 줍니다. (그림은 stride=1)
4. CNN 이해하기 (3_Channel Convolution)
위에 내용(채널 1개)에 Channel을 3개로 늘렸을 때의 Convolution 연산을 알아 보겠습니다 (Layer 1개)
Channel : 이미지는 픽셀로 가로,세로 외에 채널을 통해 색을 판단 합니다. RGB 3개의 채널을 부여해 봅니다
<RGB 별로 커널은 갖는 사진>
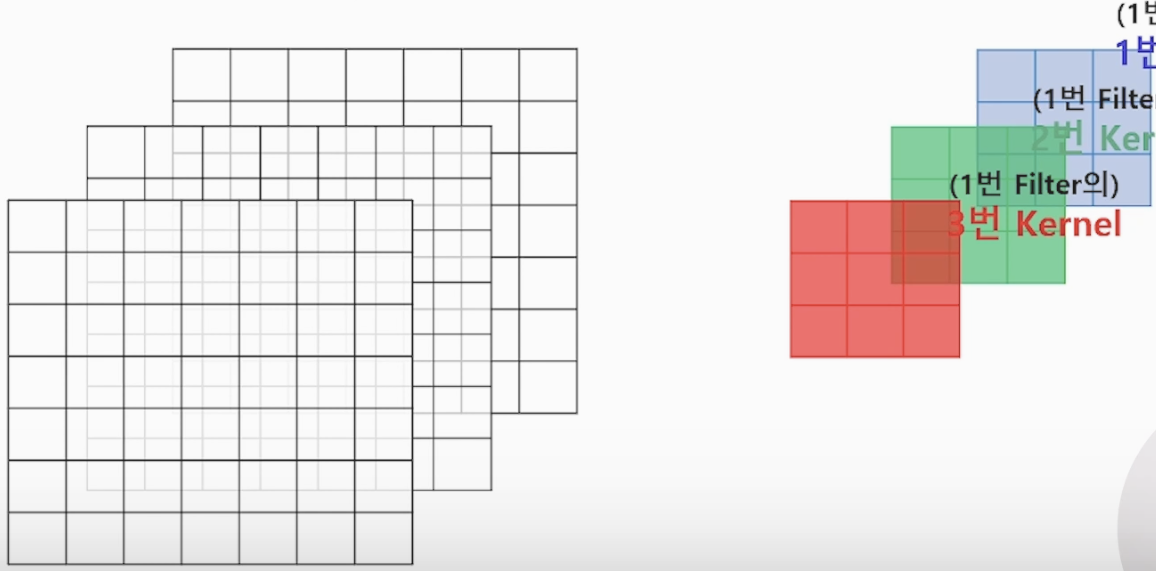
위 사진은 3x3x3, 3x3의 커널이 3개 있는(채널이 3개) 필터가 1개 있는 사진 입니다
- 중요! input 채널 1개당 커널 1개가 생성 됩니다. 여러개의 kernel들이 1개의 Filter를 구성합니다.
(Filter는 kernel의 상위 개념)
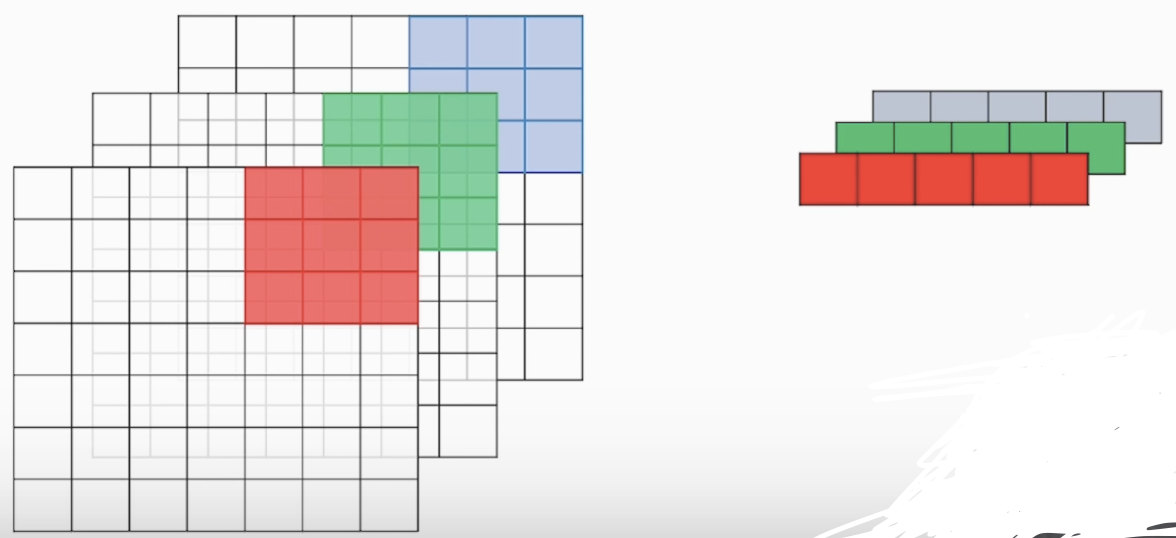
<채널(커널)이 3개일 때 연산>
아래 사진과 같이 채널(커널)을 전부 합성곱을 하고 더하여 출력 합니다
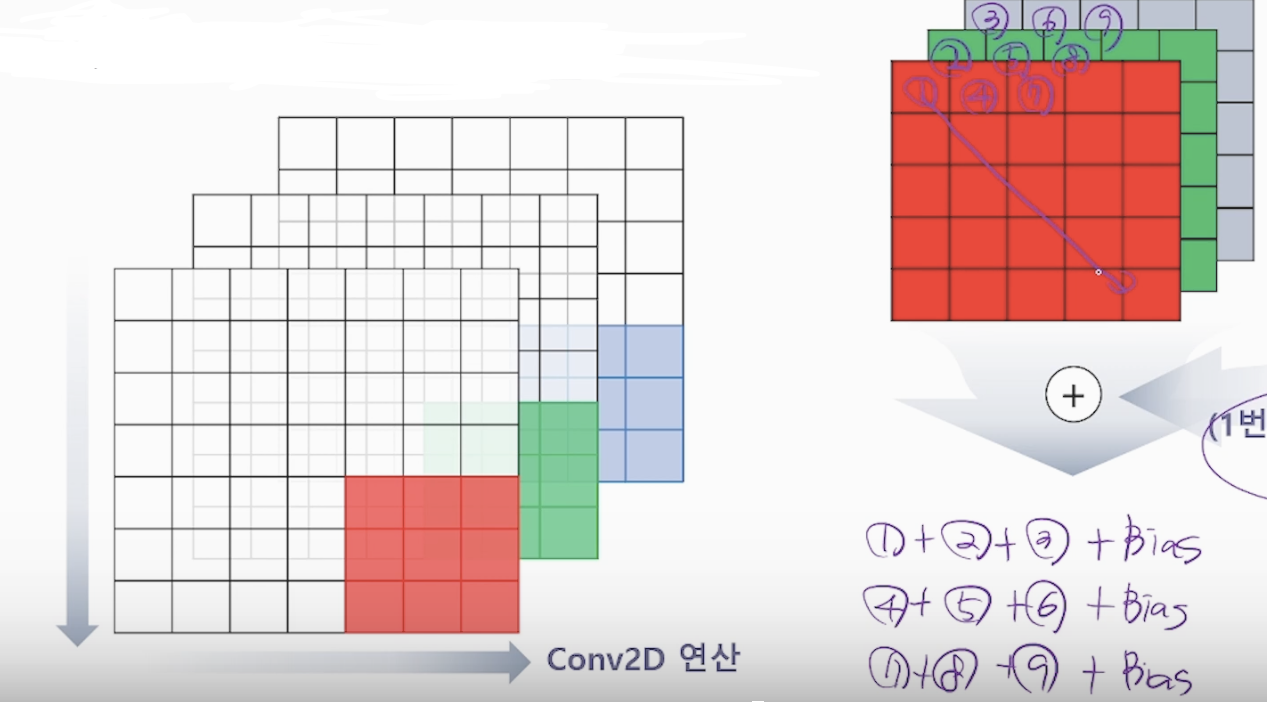
<bias 추가 연산>
합성곱 후 feature map 구성하는 값 출력 전에 bias를 각 커널의 합성곱에다가 bias를 더해줍니다
그림에서는 25번의 위 과정을 반복하고 (5x5)x3개의 칸에 같은 bias 값이 더해진다 를 기억 해주세요!
이렇게 필터 1개로 1개의 feature map이 생성 됩니다!
input의 채널수와 output의 채널 수는 다르다! filter의 수와 output의 채널 수는 같다
개념 중요합니다! 뒤에 층을 넘어가면서 크기를 구하는 식에 사용되고, 연산을 줄이기 위한 층 설정에도
사용 됩니다.
필터가 많아질 수록 여러개의 feature map을 만들 수 있습니다. 그만큼 패턴을 많이 추출합니다
4-3) Hyper-Parameter에 대한 고민(kernel size, Channel size, Stride)
하이퍼 파라미터 : 학습 이전에 사람이 설정해서 학습 과정을 제어하거나 모델의 아키텍처를 조절하는 매개변수 입니다
-
Kernel size
1) Kernel size와 파라미터의 수는 비례 합니다
2) Kernel size가 작아질수록 데이터에 존재하는 global feature 보다 local feature에 집중합니다
(넓은 범위에 특징보다는 지역적 특징에 집중해서 패턴을 찾는다는 뜻) -
Channel size
1) Filter의 channel size가 커질수록 Conv 연산을 통해 다양한 패턴을 찾을 수 있습니다
2) Channel size가 커지면 파라미터의 수는 비례 합니다 -
Stride
1) Stride 값이 커지면 데이터를 빠르게 훑고 지나가는 연산을 합니다
2) 꼼꼼하게 살펴봐야 할 경우는 작게 하는 것이 좋습니다
4-4) 1 x 1 Convolution
<1 x 1 연산 그림>
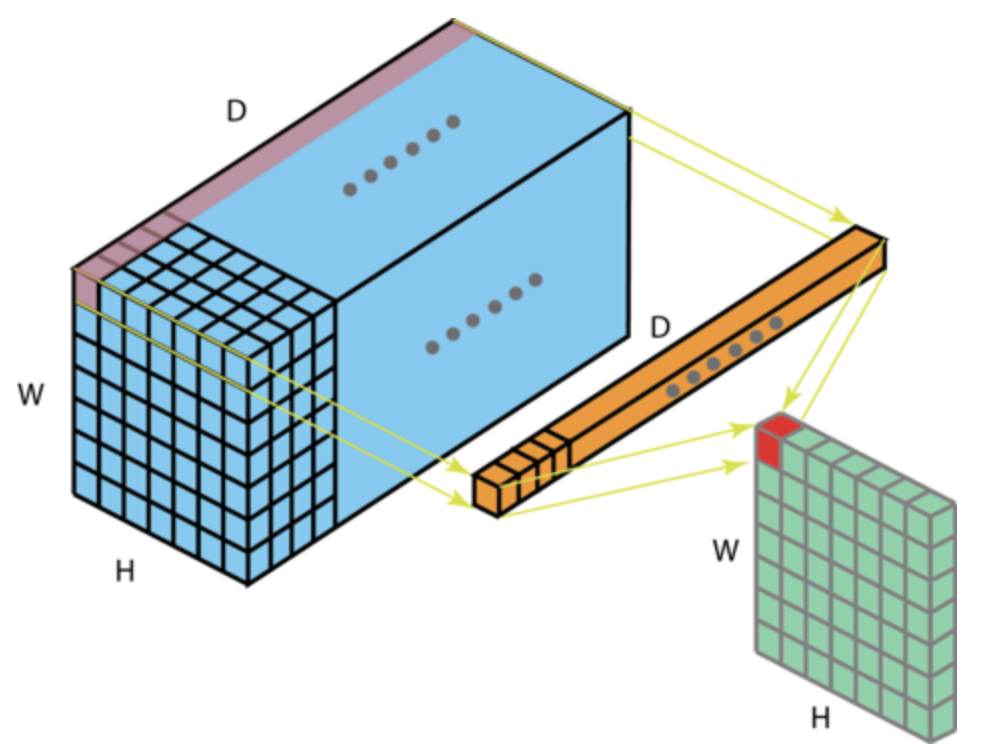
주황색이 1x1 Convolution layer 입니다. 1 by 1 레이어를 통해 채널 수를 줄여서 파라미터 수를 줄여 연산 비용을 줄입니다. 원하는 Channel size로 변경할 때도 도움을 줍니다
뒤에서 더 심도있게 활용합니다
4-5) Transposed Convolution
인코더(압축) 디코더(압축해제) 구조 중에 디코더 부분에서 Transposed Convolution 진행
저화질을 고화질로 바꾸기 위해서 사용하고 Segmentation에 활용 합니다
Up-sampling으로 작아진 이미지를 복원하고, padding과 stride로 크기를 자유롭게 조절할 수 있습니다
5. CNN 이해하기 (Pooling)
5-1) Pooling
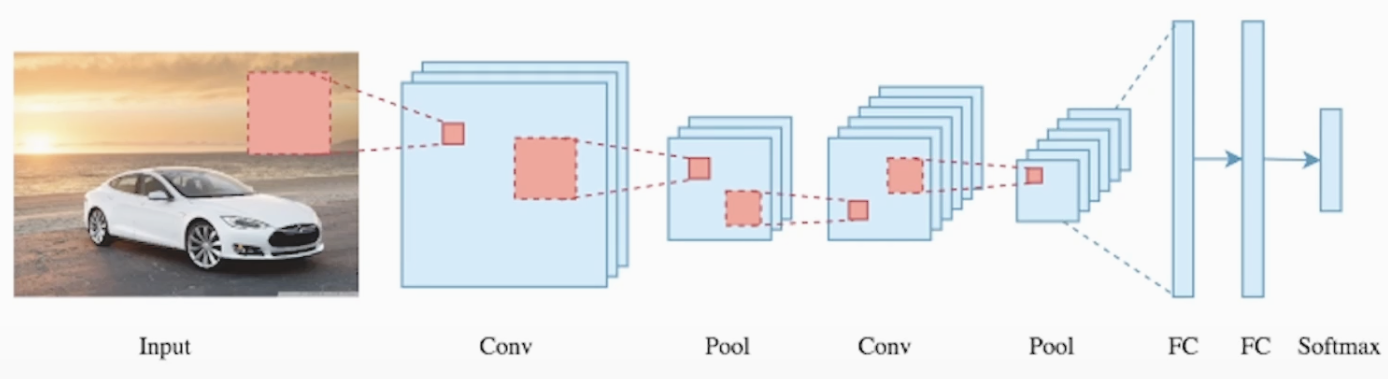
복습 CNN 전체 구조
입력 이미지 > conv (feature extraction) > Pooling(차원 축소) > Flatten > FC (MLP) > softmax classification
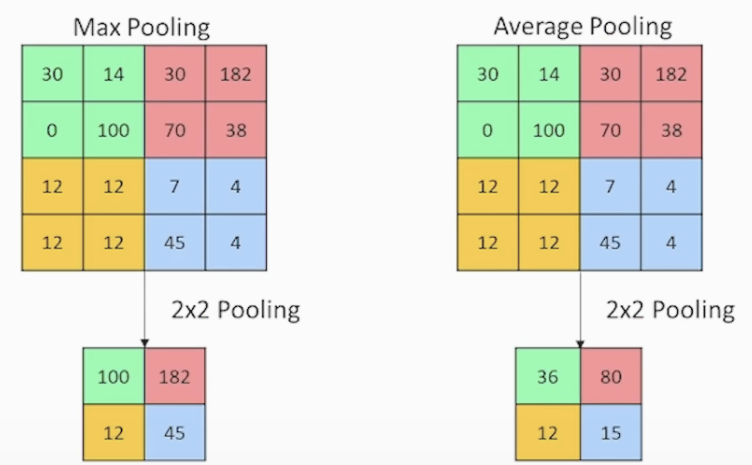
<Pooling 사진>
아래 사진과 같이 필터의 크기(사진 2x2)로 MaxPooling은 필터 영역에서 최대값을 출력해서 차원을 축소하고 파라미터를 사용하지 않고 압축하는 기법 (Down_Sampling)입니다. 종류로는 Average, Max, Sum 등이 있습니다
5-2) Convolution + Pooling 종합
Conv + Pooling 2가지 연산이 전부 적용 된 CNN의 구성과 특성
Convolution 을 통해서 이미지의 특징(패턴)을 추출 합니다 Feature map 생성
Pooling 을 통해서 정보를 축약해서 연산을 줄이고, 학습 속도를 올립니다
위 과정을 통하여 모델을 더욱 깊게 만드는 방향으로 구성합니다. 깊게 만들면서 여러 채널을 가진 feature map들을 형성 합니다. 그러면 더욱 복잡하고 다양한 패턴(특징)을 추출할 수 있습니다
Conv는 활성화 함수로 대체적으로 relu를 사용합니다
5-3) CNN 구조 구현
<CNN 모델 구성 코드>
# Q. tf.keras.Model을 사용하여 model을 정의해 주세요.
# Functional API 방법
model = tf.keras.Model()
# input 레이어 설정(크기)
input_tensor = tf.keras.layers.Input(shape=(28, 28, 1))
x = tf.keras.layers.Conv2D(filters=32, kernel_size=3, strides=1, padding='same', activation='relu')(input_tensor)
x = tf.keras.layers.Conv2D(filters=64, kernel_size=3, activation='relu')(x)
x = tf.keras.layers.MaxPooling2D(2)(x)
# 3차원으로 되어있는 Feature map 결과를 Fully Connected 연결하기 위해서는 Flatten()을 적용해야 합니다.
x = tf.keras.layers.Flatten()(x)
# Flatten 된 결과를 100의 노드를 가진 Fuly Connected Layer와 연결
x = tf.keras.layers.Dense(100, activation='relu')(x)
output = tf.keras.layers.Dense(10, activation='softmax')(x)
# 모델 확인
model = tf.keras.Model(inputs=input_tensor, outputs=output)
model.summary()<파라미터 수 계산>
커널 속 원소가 각 가중치
1번째 conv 레이어 : 파라미터 수(가중치, 편향의 수) = (3 * 3 * 1 + 1) * 32 (필터수,채널수) = 320개
2번째 conv 레이어 : (3*3*32(input 필터,채널) +1(편향)) * 64 = 18496
맥스풀링은 파라미터를 사용하지 않는다
맥스풀링으로 크기가 13x13x64 = 10816 개로 축소
뉴런 100개의 Dense layer : 10816 * 100 + 100(편향) = 1081700
출력층 : 10개의 클래스 : 100 x 10 + 10(편향) = 1010
320 + 18496 + 1081700 + 1010
총합 1,101,526