딥러닝으로 CV 시작!
- 목 차
Previous Chapter
- 컴퓨터 비전 task "상상 해보기"
- 다층 퍼셉트론(Multi-Layer-Perceptron) 구조
- CNN 이해하기 (1_Channel Convolution)
- CNN 이해하기 (3_Channel Convolution)
- CNN 이해하기 (Pooling)
Current Chapter
- 심화된 CNN 구조
- Transfer Learning 이해하기
later Chapter
- Object Detection
- Segmentation
last chapter
- 모델들의 아이디어와 구조(코드)
6. 심화된 CNN 구조
6-1) Inception Module (naive Version) "GoogLeNet"
Vanishing gradient(기울기 소실) : 레이어가 깊어지면 오차를 역전파(BackPropagation)에서 Input layer로 갈수록 기울기가 사라져 학습이 제대로 이루어지지 않는 문제
Vanishing gradient 문제를 해결하면서 레이어를 깊게 만들어 보는 것이 핵심!
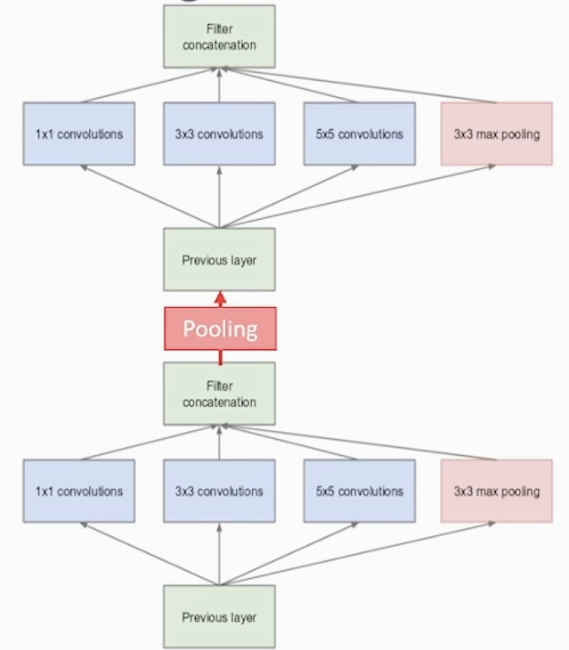
<Inception Module 중 간단한 구조>
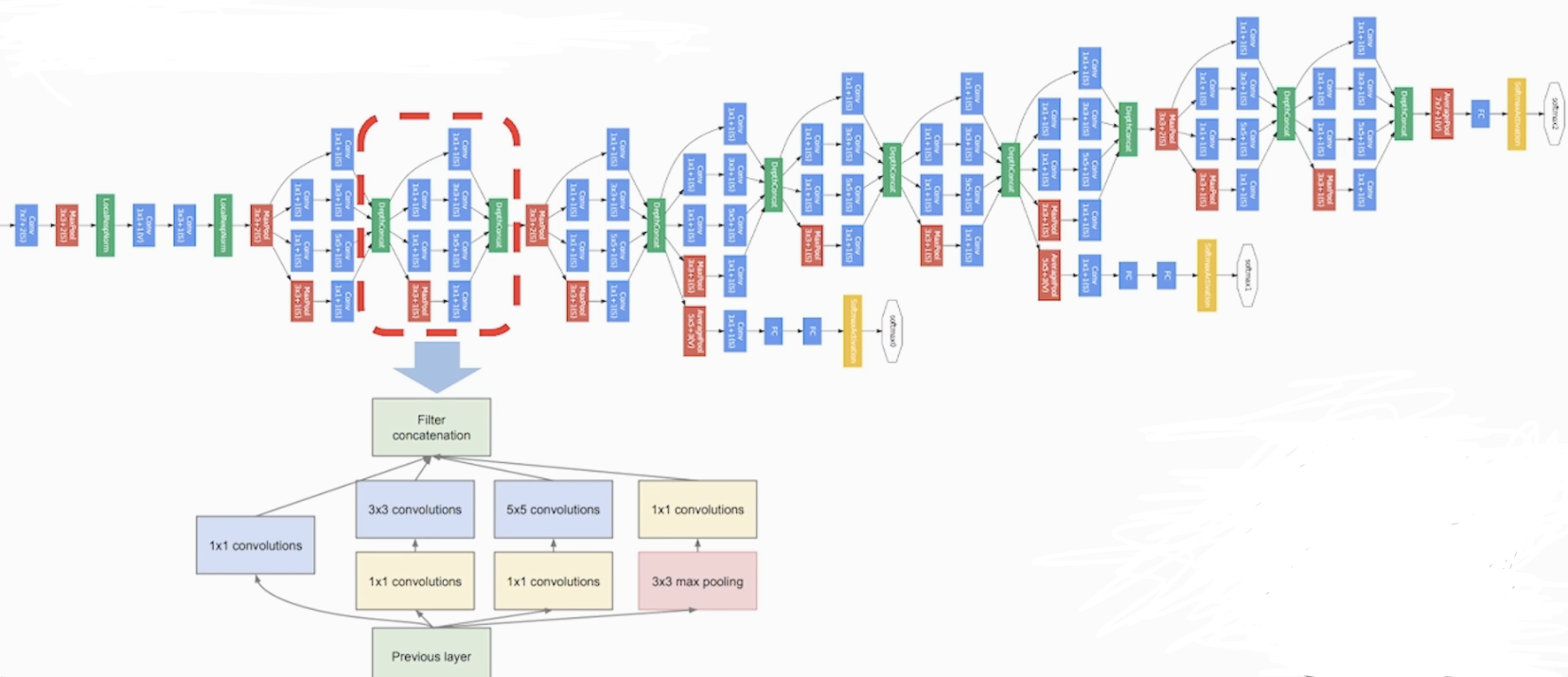
<Inception Module 아이디어>
다양한 크기의 kernel size를 통해서 여러 Conv를 통해 다양한 feature map을 추출 해보자
최종적으로 다양한 Conv 레이어들을 Concatenation(연쇄) 하자
최적의 커널의 필터 사이즈와 Pooling을 고민해서 찾기보다는 다 적용해서 합쳐보자
kernel size가 클수록 global feature을 추출할 수 있습니다
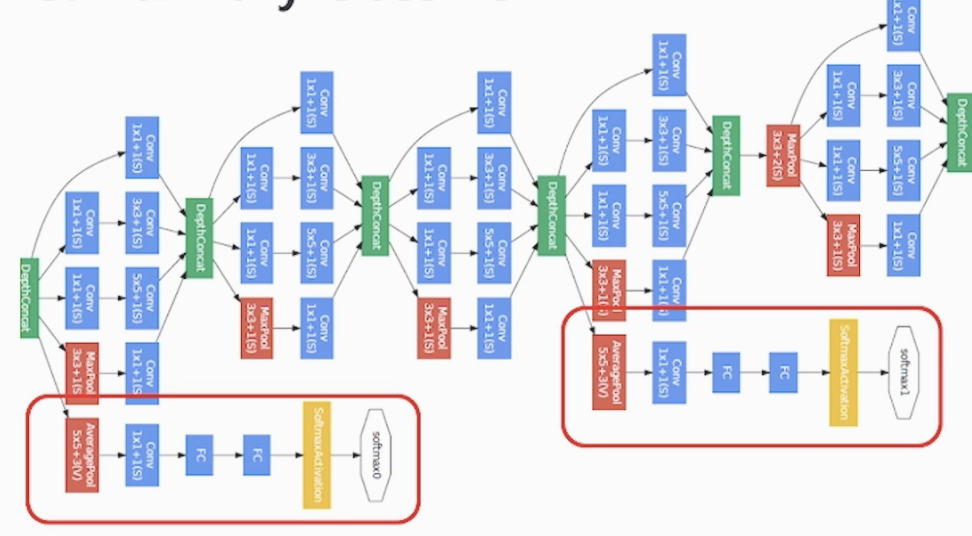
<GoogLeNet 구조>
- Inception Module을 연속적으로 이어 구성
- 여러 사이즈의 필터들이 서로 다른 공간을 기반으로 Feature를 추출하고 이를 결합하여 복잡하고 다양한 Feature extractor layer 구성이 가능합니다
<나의 Inception Module 구성 코드>
# Naïve Inception 블록을 만들기 위한 함수
def my_naive_inception(input_layer, conv1_filter, conv3_filter, conv5_filter, dense_filter):
conv1 = keras.layers.Conv2D(conv1_filter, (1,1), padding='same', activation='relu')(input_layer)
conv3 = keras.layers.Conv2D(conv3_filter, (3,3), padding='same', activation='relu')(conv1)
conv5 = keras.layers.Conv2D(conv5_filter, (5,5), padding='same', activation='relu')(conv3)
max_pool = keras.layers.MaxPooling2D((3,3), strides=(1,1), padding='same')(input_layer)
# 위에서 언급한 4개의 layer 통해서 나온 feature map들을 모두 concatenation 한다.
out_layer = keras.layers.Concatenate()([conv1, conv3, conv5, max_pool])
return out_layer6-2) Inception Module (1 x 1 Conv) "GoogLeNet"
위 Naive version에서 조금 더 변형 된 버전 입니다
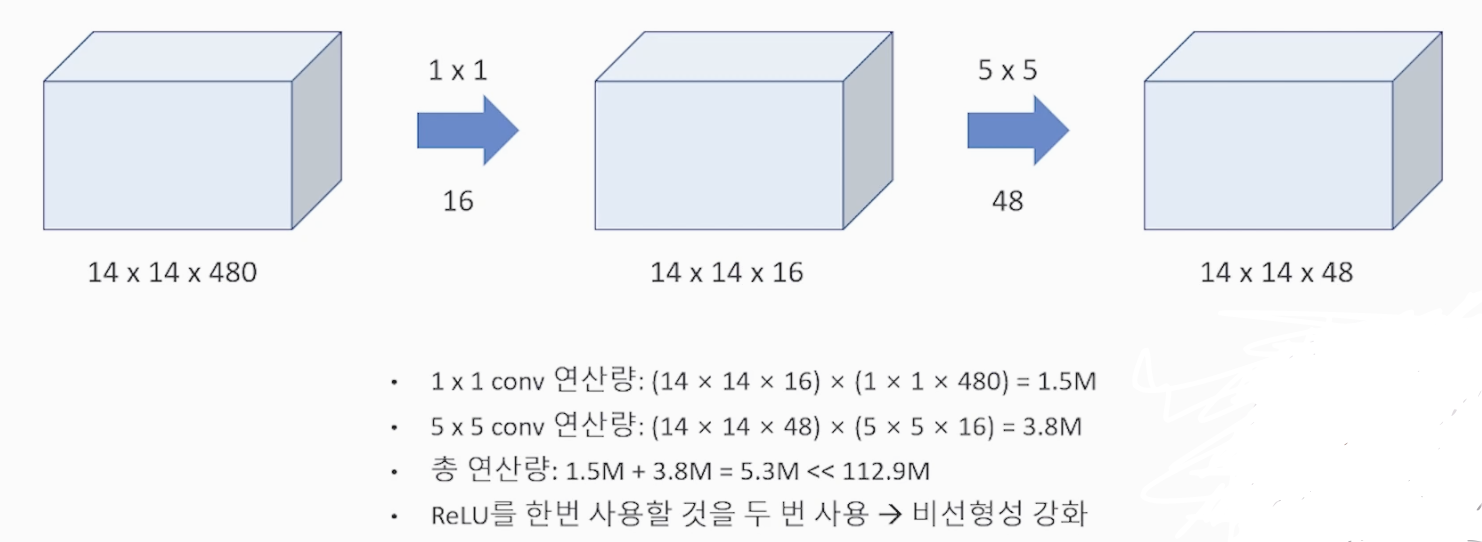
채널이 깊은 Input tensor가 주어졌을 때 1 by 1 Conv를 통해서 채널을 감소시켜 파라미터 수를 감소시키고 연산량을 감소 시킵니다. 활성화 함수를 2번 사용하게 되면서 'relu'를 통해 비선형성을 추가로 더합니다.
- input channel 수 = filter channel 수 (input channel 수 =! output channel 수)
- filter의 수 = output channel의 수
<1 by 1 Filter 연산>
파라미터 수 계산 시에는 Filter 와 output 사이즈의 곱으로 표현한다
<Global Average Pooling 사용 구조>
Global Average Pooling은 feature map 전체를 대상으로 평균을 구하는 Pooling 연산 입니다

<Auxiliary Classfier 활용 구조>
매우 깊은 네트워크에서 '기울기 소실'문제를 해소하기 위하여 Auxilary Classifier 라는 과정을 중간중간에 덧 붙여서 역전파 시 중간중간 마다 Loss를 구하기 때문에 역전파가 끝까지 갈 수 있습니다
대신 지나치게 영향을 주는 것을 방지하기 위해 Auxiliary Classfier의 Loss에 0.3을 곱해 줍니다
구조는 average Pooling > 1x1 Conv > FC > Fc > softmax > output 으로 중간 feature를 받아서 수행 합니다. (중간 feature map을 정규화 효과가 있어 과적합 방지도 된다고 합니다. 추후 다른 모델에도 적용해보자)
(Auxiliary Classifier : 가짜 분류기)
(그림의 빨간 영역이 Auxiliary Classifier)
6-3) Skip Connection (ResNet)
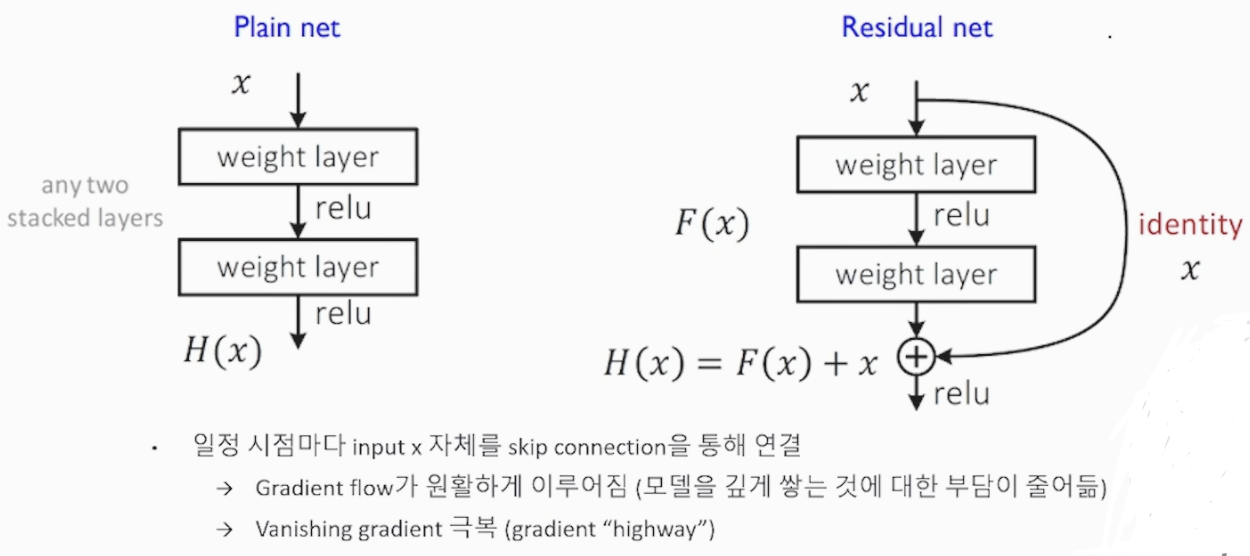
Residual Learning 학습 방법 중 입력 데이터를 여러 Layer를 거치는 과정 외에 바로 출력 전에 전체 과정과 합하여 주는 방식 입니다.
역전파(Backpropagation)에서 입력 데이터 자체(identity mapping)의 error(Loss)를 그대로 더 해주면서 Vanishing gradient를 방지할 수 있습니다(Gradient flow가 원활하게 이뤄져 모델의 깊이에 대한 부담이 줄어 듭니다)
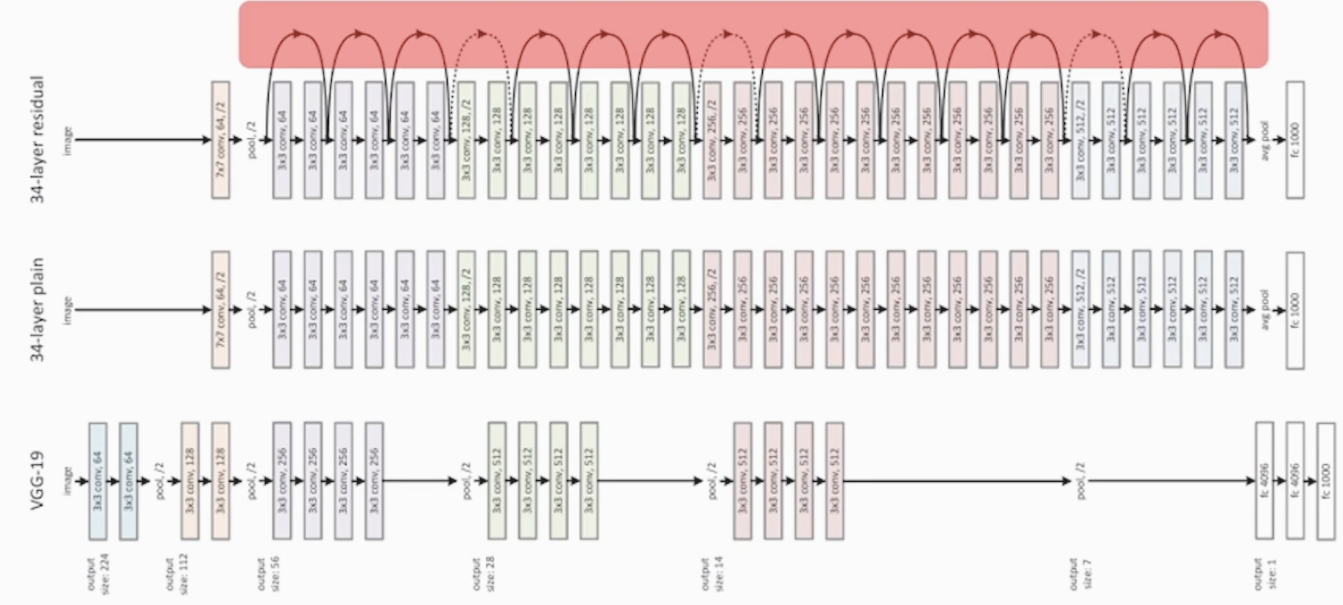
<34개의 레이어 ResNet, residual 학습>
빨간 영역이 Skip_Connection
<Skip connection 구조>
(Skip connection = Gradient "highway")
<Residual Module 구성 코드>
def residual_module(input_layer, n_filters):
merge_input = input_layer
# if문에서는 채널 사이즈가 동일한지 확인하고, 만일 동일하지 않다면 1x1 convolution을 통해서 채널 사이즈를 맞춰 준다.
if input_layer.shape[-1] != n_filters:
merge_input = keras.layers.Conv2D(n_filters, (1,1), padding='same', activation='relu')(input_layer) # n_filter로 채널 사이즈를 맞춰 준다.
# Conv2D layer
conv1 = keras.layers.Conv2D(n_filters, (3,3), padding='same', activation='relu')(input_layer)
# Conv2D layer
conv2 = keras.layers.Conv2D(n_filters, (3,3), padding='same', activation='linear')(conv1)
# Add를 통해서 skip connection을 구현하는 부분
out_layer = keras.layers.Add()([conv2, merge_input])
out_layer = keras.layers.Activation('relu')(out_layer)
return out_layer
# input layer 정의
input = keras.layers.Input(shape=(256, 256, 3))
residual_out = residual_module(input, 64) # input layer와 필터(채널)수를 arg로 받음
# 모델 확인
model = keras.models.Model(inputs=input, outputs=residual_out)
model.summary()
# 모델 구조 시각화
plot_model(model, show_shapes=True, to_file='residual_module.png')6장 정리 : 레이어를 깊게 쌓으면서 다양한 Feature를 추출하는 과정에서 Vanishing gradient 문제를 방지할 수 있는 여러 방법들을 알아 보았습니다.
7. Transfer Learning 이해하기
7-1) 대규모 모델 학습의 어려움
딥러닝 방식이 발전하면서 점점 방대한 데이터를 요구하고, 다량의 파라미터 연산을 요구하면서 비용이 크게 증가합니다. 이제부터 데이터도 없고, 연산 비용을 지불할 자금과 시간도 없을 때 딥러닝 모델을 잘 학습 시키기 위한 'Transfer Learning' 에 대하여 배워보겠습니다
<데이터 고민 알고리즘>
7-2) Transfer Learning의 아이디어
처음부터 학습 시키는 training from scratch 라고 합니다.
Transfer Learning(Knowledge Tranfer) 은 학습된 모델(Pre-Trained)을 이용하는 방법 입니다
(파라미터 값을 잘 갱신 해둔 것, 저장된 파라미터 값들을 그대로 가져와서 일부만 수정해서 사용합니다)
- Tranfer Learning의 목적
데이터의 사이즈의 영향을 줄일 수 있고, 연산 비용 감소 등 pre-trained 된 모델을 가져옴으로서 파라미터에 대해서 학습을 효율적으로 task에 활용할 수 있습니다.
데이터 사이즈와 pre-trained 데이터와의 유사성으로 train data를 이용한 학습의 정도를 결정합니다
<Training from scatch & Transfer Learning>
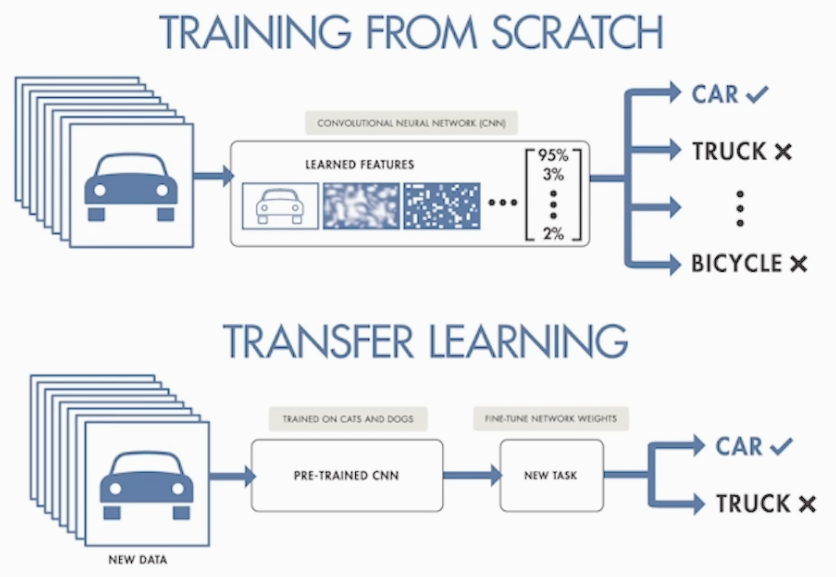
7-3) Transfer Learning의 적용
CNN 딥러닝 기법은 Feature 레이어가 전달 될수록 Domain(Task)적인 Feature들을 학습 합니다(Local > global)
<데이터 사이즈가 작을 때 학습>
데이터가 부족하기 때문에 잘 학습 된 파라미터를 가져와서 Classification만 하기 위해 끝 부분 완전연결계층에서만 train 시킵니다. 가져온 파라미터를 사용하는 부분을 Freeze 시킨다고 합니다
데이터 사이즈와 pre-trained 데이터의 유사성을 통해 Train & Freeze 비율을 조절 합니다
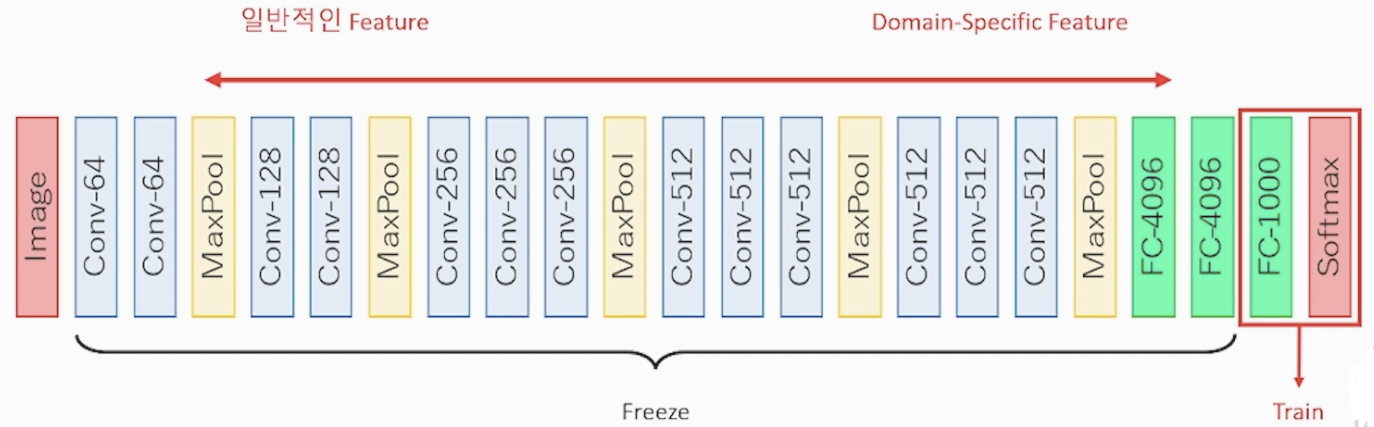
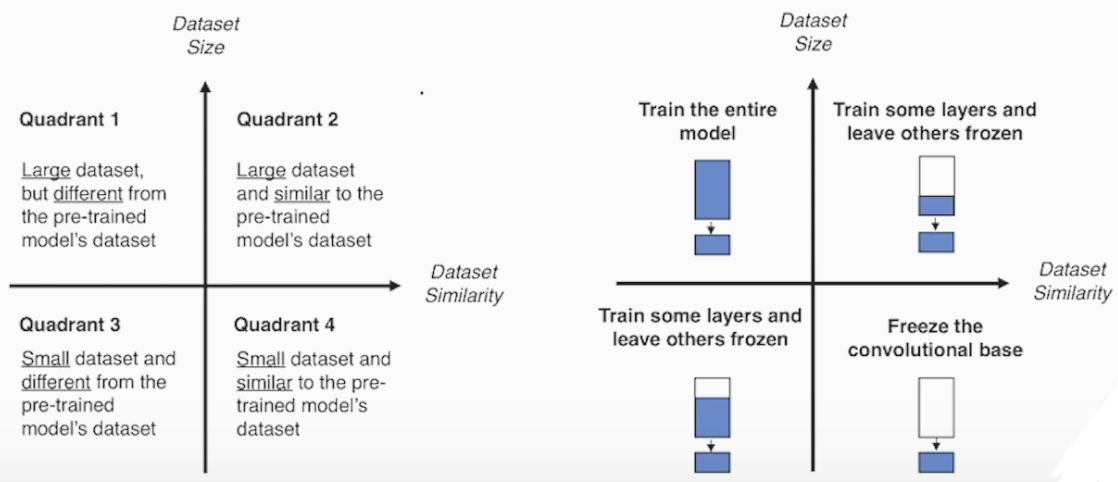
<데이터셋의 유사성(pre-trained data)과 사이즈(my data)에 따른 학습 방법 그래프>
데이터 사이즈가 충분히 크다면 유사성에 따라 전체를 학습 시키거나 50% 정도 학습 시키는게 좋고
데이터 사이즈가 너무 작을 경우도 유사성에 따라 기본 피처만 제외하고 학습 시키거나 직접적으로 분류하는 레이어만 학습 시킵니다
데이터 셋이 중간 사이즈 일 때는 유사성에 맞게 비율을 적절히 설정해야 합니다
- 유사성(x축), 사이즈(y축) 기준 4구역으로 나눴을 경우 아래와 같이 나눠 집니다