Deep_Learning의 요약
- 딥러닝의 개요부터 모델 구성과 학습 방법을 위한 기법까지 전체적으로 요약해봅니다
- 실습 전체 코드는 마지막에 접어 두겠습니다(접기/펼치기가 안되요ㅠㅠ 생략)
- 이 챕터에서는 MNIST 딥러닝 모델 예제를 사용합니다 (추후 추가 예정..)
<목 차>
previous chapter
- 딥러닝이란?
- 텐서(Tensor) 표현과 연산
- 딥러닝 구조와 모델
- 딥러닝 모델 학습
Current Chapter
- 모델 저장과 콜백(save & callback)
- 모델 학습 기술
- 모델 크기 조절과 규제
- 가중치 초기화와 배치 정규화(Batch Normalization)
5. 모델 저장과 콜백(save & callback)
5-1) 모델 저장과 로드
모델을 열심히 학습시키고 저장을 안한다면 다시 처음부터 학습을 해야합니다. 즉, 어느 정도 학습이 되었다면 추후에 모델을 사용하기 위해서 저장할 필요가 있습니다. 모델을 저장할 때는 save() 함수를 사용하여 쉽게 저장할 수 있고, 다시 모델을 불러올 때는 load_model() 함수를 사용하면 됩니다.
- 모델을 저장하고 로드하는 것에서 중요한 점
-
Sequencial API 또는 Functional API를 사용한 경우 모델의 저장 및 로드가 가능
-
Subclassing API 방식은 사용할 수가 없습니다. Subclassing API 방식은 save_weights()와 load_weights()를 이용해 모델의 파라미터만 저장 및 로드하는 것이 가능합니다.
만약 JSON 형식으로 모델을 저장하려면 to_json()를 사용
JSON 파일로부터 모델을 로드하려면 model_from_json()을 사용
YAML로 직렬화하여 저장할 경우 to_yaml()를 사용
YAML 로드는 model_from_yaml()를 사용
.h5 형식 저장 및 로드
model.save('Your model.h5')
loaded_model = models.load_model('mnist_model.h5')
loaded_model.summary().json 형식 저장 및 로드
# 위에서 학습시킨 model의 구조를 json 형식으로 model_json에 저장합니다.
model_json = model.to_json()
# json으로 저장한 모델을 읽어옵니다.
loaded_model = keras.models.model_from_json(model_json)
5-2) 콜백 (callback)
모델을 fit() 함수를 통해 학습시키는 동안 callbacks 매개변수를 사용하여 학습 시작이나 끝에 호출할 객체 리스트를 여러 개 지정할 수 있습니다. 콜백의 대표적인 예로는 ModelCheckpoint, EarlyStopping, LearningRateScheduler, Tensorboard가 있습니다.
A. ModelCheckpoint
tf.keras.callbacks.ModelCheckpoint: 정기적으로 모델의 체크포인트를 저장하고, 문제가 발생할 때 복구하는데 사용합니다.
check_point_cb = callbacks.ModelCheckpoint('keras_mnist_model.h5', save_best_only=True)
history = model.fit(x_train, y_train, epochs=10,
validation_data=(x_val, y_val),
callbacks=[check_point_cb])B. EarlyStopping
tf.keras.callbacks.EarlyStopping: 검증 성능이 한동안 개선되지 않을 경우 학습을 중단할 때 사용합니다.
일정 patience 동안 검증 세트에 대한 점수가 오르지 않으면 학습을 멈추게 됩니다. 모델이 향상되지 않으면 학습이 자동으로 중지되므로, epochs 숫자를 크게 해도 무방합니다. 학습이 끝난 후의 최상의 가중치를 복원하기 때문에 모델을 따로 복원할 필요가 없습니다.
early_stopping_cb = callbacks.EarlyStopping(patience=3, monitor='val_loss',
restore_best_weights=True)
history = model.fit(x_train, y_train, epochs=10,
validation_data=(x_val, y_val),
callbacks=[check_point_cb, early_stopping_cb])C. LearningRateScheduler
tf.keras.callbacks.LearningRateSchduler: 최적화를 하는 동안 학습률(learning_rate)를 동적으로 변경할 때 사용합니다.
에폭 수가 10 미만일 경우는 학습률을 그대로 하고, 10 이상이 되면 -0.1%씩 감소시키는 코드입니다.
def scheduler(epoch, learning_rate):
if epoch < 10:
return learning_rate
else:
return learning_rate * tf.math.exp(-0.1)- LRS 사용 코드
lr_scheduler_cb = callbacks.LearningRateScheduler(scheduler)
history = model.fit(x_train, y_train, epochs=15,
callbacks=[lr_scheduler_cb], verbose=0)
round(model.optimizer.lr.numpy(), 5)D. Tensorboard
tf.keras.callbacks.TensorBoard: 모델의 경과를 모니터링할 때 사용합니다.
텐서보드를 이용하여 학습과정을 모니터링하기 위해서는 logs 폴더를 만들고, 학습이 진행되는 동안 로그 파일을 생성합니다. 텐서보드에는 효율적인 모니터링을 위해서 여러가지 기능들을 제공하고 있습니다.
log_dir = './logs'
tensor_board_cb = [callbacks.TensorBoard(log_dir=log_dir, histogram_freq=1, write_graph=True, write_images=True)]
model.fit(x_train, y_train, batch_size=32, validation_data=(x_val, y_val),
epochs=30, callbacks=tensor_board_cb)6. 모델 학습 기술
6-1) 모델의 학습 기술
<학습기술 전체 그림>
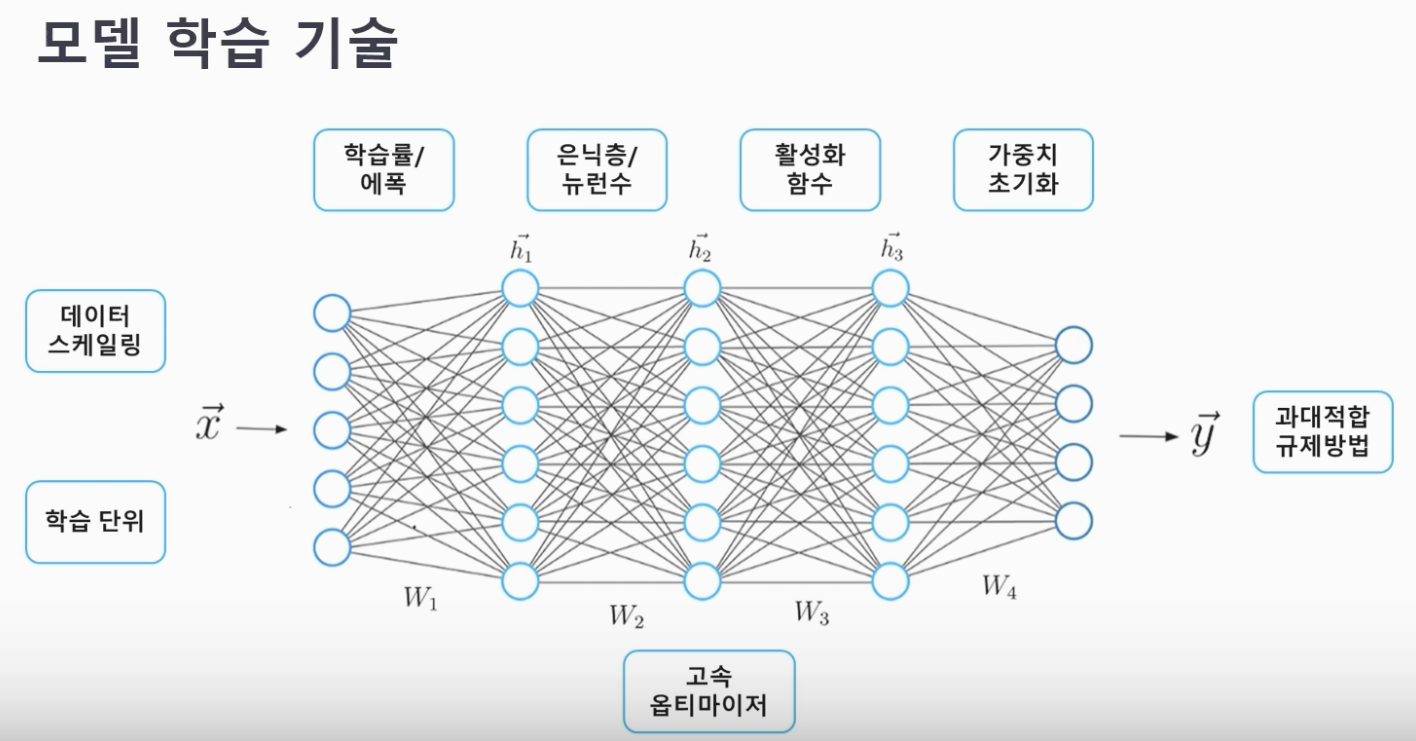
A. 학습 단위
Full batch : 모든 데이터를 다 입력해서 학습 시키는 방식
Stochastic : 전체 데이터 중 랜덤으로 추출하여 알고리즘에 넣는 방식
Mini Batch : 전체 데이터 중 일부를 묶어 모델에 사용하는 방식(많이 쓰임)
- 한번 학습할 때 얼마만큼의 미니배치 크기를 사용할지 결정해야 하고, 배치 크기가 작을수록 학습 시간이 많이 소요 되고 클수록 적게 소요 된다. (딥러닝에서 많이 사용 된다. 딥러닝은 데이터와 매개변수가 엄청엄청 많기 때문입니다)
B. 데이터 스케일링
표준화(Standardization) : 특성들의 평균 0, 분산 1 로 하는 스케일링을 사용해서 특성들의 정규분포화 하는 과정
정규화(Normalization) : 특성들을 특정 범위로 스케일링, 가장 작은 값은 0, 가장 큰 값은 1로 모든 특성이 0~1의 범위를 갖도록 함
(제일 큰 값으로 전체 데이터들을 나눠주는 방법)
C. 학습률과 에폭
-
모델의 학습 정도가 학습률(에타, Learning_rete)에 따라 달라지므로 적합하게 찾아야 함
-
학습률 = 가중치의 조정 단위, 하이퍼파라미터, 오차가 최소화 되는 간격으로 변경
-
학습률이 너무 크면 오버슈트, 작으면 최소값 이전에 스톱!
-
에폭은 한번의 학습 과정을 몇 번 수행할지 지정
-
에폭이 너무 작으면 과소적합, 크면 과대적합이 발생할 수 있음
-
학습률과 에폭은 반비례 관계
D. 은닉층과 뉴런수
모델의 크기를 결정 해주는 은닉층과 뉴런수!
모델을 구성할 때 얼마나 쌓을지 얼마나 많이 뉴런을 구성할지에 따라 크기가 달라지므로 데이터에 맞게 모델을 구성 해야 합니다. 모델 구성에 따라서 파라미터의 개수도 달라집니다(학습과 최적화에 영향을 주겠죠?)
F. 활성화 함수 (입력값에 목적에 맞게 형태를 바꾸어 출력해주는 중간 함수)
Activation Function! 입력값에 목적에 맞게 형태를 바꾸어 출력해주는 중간 함수입니다
딥러닝 성능에 주요 요소 중 하나로 가중치(W)와 편향(bias)를 조정합니다
문제에 맞게 목적에 맞는 활성화 함수를 사용해야 학습이 잘 됩니다
크게 Sigmoid 계열과 Relu계열로 구분 (선형과 비선형)
G. 가중치 초기화
-
모델의 학습 초기에 처음 가중치를 어떻게 할건지 정해지는 부분
-
초기값을 0(.Zeros)으로 할 경우 모든 노드들의 가중치가 0이 되므로 딥러닝을 사용하는 의미가 없습니다
-
가중치 초기화는 활성화 값이 골고루 분포 되는 것이 중요 합니다
한쪽으로 치우치거나 모여 있으면 신경망의 수가 적어져서 표현력이 떨어 집니다
가중치 초기화 방법으로는 Xavier(Glorot) 와 HE 가 대표적으로 나눠져 있으며 전자는 분류, 후자는 회귀에 적합 합니다.
사비에르는 루트 1/n He는 루트 2/n을 표준편차로 사용 합니다
H. 옵티마이저
모델이 실제값과 예측값의 차이를 최소화하는 역할을 수행
(손실함수 값이 최소가 되도록 하는 최적의 매개변수를 찾음)
옵티마이저 종류로는 앞 chapter에서 설명했던
SGD, RMSprop, Adagrad, Adadelta, Adam
- SGD 단점 : 단순하고 계산은 빠르지만 안장점(Saddle point)에서 탈출이 어렵다
- 학습률 감소 (lr decay)를 이용함
- RMSprop는 최근 값에 비중을 주며 갱신하는 방식 (Adagrad 개선), 지수적 감소 사용
- Adagrad는 스케일링 단위(수식에서 h)의 제곱을 이용하여 기울 전체 내역을 고려하는 방식
(제곱으로 조절 하다보니 손실 값이 클 때 크게 감소한다)
6-2) 과소적합과 과대적합(Overfitting)
A.과소적합(Underfitting)
-
학습 데이터를 충분히 학습하지 않아 성능이 매우 안 좋은 경우
-
모델이 지나치게 단순한 경우 발생, 복잡한 모델을 사용하거나 데이터 충분히 수집
-
에폭(epochs)수를 늘려 충분히 학습 시켜줘야 함
B. 과대적합(Overfitting) : 딥러닝에서 매우 관건
-
모델이 학습 데이터에 지나치게 적응한 상태
-
새로운 데이터에서 성능 저하가 발생하는 경우이며, 학습 데이터가 매우 적거나 모델이 지나치게 복잡한 경우, epochs가 매우 많을 경우 발생
-
오버피팅을 해결하기 위해서는 다양한 학습 데이터 수집 및 학습, 파라미터가 적은 모델, 모델 단순화, 데이터의 특성 수를 줄이기 등이 있다
-
구체적으로는 학습 데이터 증강, Dropout 레이어 추가(batch norm 같이 사용하면 좋음), 모델이 데이터에 비해 너무 복잡(파리미터 수를 줄여야함)(레이어 감소, 뉴런 감소 등), Early stopping 사용(과한 학습 방지)
3) IMDB 딥러닝 모델 예제
데이터 로드 및 분리
# 인덱스 1만개 제한, 즉 인덱스는 0~9999까지 구성
from keras.datasets import imdb
import numpy as np
(train_data, train_labels), (test_data, test_labels) = imdb.load_data(num_words=10000)
print(train_data[0])
print(train_labels[0])인덱스 > 실제 단어 변환
word_index = imdb.get_word_index()
# word_index # 주석 지우면 인덱스 변환된 거 확인단어 > 인덱스 변환
index_word = dict([(value, key) for (key, value) in word_index.items()])
# index_wordReview 만들기, 인덱스 맵핑 단어 연결
review = ' '.join([str(i) for i in train_data[0]])
# 0~2 인덱스는 ?로 대체, 쓸데없는 인덱스 들어 있음 (i-3)
review = ' '.join([index_word.get(i-3, '?') for i in train_data[0]])
review원핫 인코딩 변환
def one_hot_encoding(data, dim=10000): # imdb 데이터의 num_words를 10000으로 설정해서 dim도 10000으로 맞춰줍니다.
results = np.zeros((len(data), dim))
for i, d in enumerate(data):
results[i, d] = 1.
return results
x_train = one_hot_encoding(train_data)
x_test = one_hot_encoding(test_data)
print(x_train[0])정답 레이블 긍정,부정이 정수형 > 실수형 변환
y_train = np.asarray(train_labels).astype('float32')
y_test = np.asarray(test_labels).astype('float32')
print(y_train[0])
print(y_test[0])모델 구성
import tensorflow as tf
from tensorflow.keras import models, layers
model = models.Sequential()
model.add(layers.Dense(16, activation='relu', input_shape=(10000, ), name='input'))
model.add(layers.Dense(16, activation='relu', name='hidden'))
model.add(layers.Dense(1, activation='sigmoid', name='output'))모델 컴파일 및 학습
model.compile(optimizer='rmsprop',
loss='binary_crossentropy',
metrics=['accuracy'])
model.summary()
history = model.fit(x_train, y_train,
epochs=20,
batch_size=512,
validation_data=(x_test, y_test))모델 시각화
import matplotlib.pyplot as plt
history_dict = history.history
loss = history_dict['loss']
val_loss = history_dict['val_loss']
epochs = range(1, len(loss) + 1)
fig = plt.figure(figsize=(12, 5))
ax1 = fig.add_subplot(1, 2, 1)
ax1.plot(epochs, loss, color='blue', label='train_loss')
ax1.plot(epochs, val_loss, color='red', label='val_loss')
ax1.set_title('Train and Validation Loss')
ax1.set_xlabel('Epochs')
ax1.set_ylabel('Loss')
ax1.grid()
ax1.legend()
accuracy = history_dict['accuracy']
val_accuracy = history_dict['val_accuracy']
ax2 = fig.add_subplot(1, 2, 2)
ax2.plot(epochs, accuracy, color='blue', label='train_accuracy')
ax2.plot(epochs, val_accuracy, color='red', label='val_accuracy')
ax2.set_title('Train and Validation Accuracy')
ax2.set_xlabel('Epochs')
ax2.set_ylabel('Accuracy')
ax2.grid()
ax2.legend()
plt.show()위 전체 코드를 실행해서 시각화 해보면 val_loss,acc가 점점 증가하면서 과적합(오버피팅) 됨을 확인할 수 있습니다
뒤 내용에서 오버피팅을 방지하는 방법을 배우겠습니다.
7. 모델 크기 조절과 규제
7-1) 모델의 크기 조절
위 IMDB 딥러닝 모델의 과대적합을 해결하기 위해서 모델의 크기 를 조절하려 합니다
방법으로는 유닛 수(뉴런의 수)와 레이어를 조절합니다
먼저 레이어의 뉴런 수를 증가/감소 시켜 모델 전체의 파라미터 수를 조절 해보겠습니다
두번째로는 레이어의 수를 증가 시켜 더 깊은 신경망을 만들어 모델의 크기를 증가 시키는 방법이 있습니다
(데이터의 양에 비해 모델이 너무 크면 과대적합이 발생하니 적절하게 조절해야 합니다)
A. 뉴런 수 증가 (기존 128개 > 2048로 크게 증가)
b_model = models.Sequential()
# 기존 128 > 2048개
b_model.add(layers.Dense(2048, activation='relu', input_shape=(10000, ), name='input3'))
# 기존 128 > 2048개
b_model.add(layers.Dense(2048, activation='relu', name='hidden3'))
b_model.add(layers.Dense(1, activation='sigmoid', name='output3'))
b_model.compile(optimizer='rmsprop',
loss='binary_crossentropy',
metrics=['accuracy'])
b_model.summary()
# 전체 파라미터 수가 24,680,449개로 증가B. 모델 크기 감소, 뉴런 수 감소 (기존 128개 > 16로 크게 감소)
b_model = models.Sequential()
# 기존 128 > 16개
b_model.add(layers.Dense(16, activation='relu', input_shape=(10000, ), name='input3'))
# 기존 128 > 16개
b_model.add(layers.Dense(16, activation='relu', name='hidden3'))
b_model.add(layers.Dense(1, activation='sigmoid', name='output3'))
b_model.compile(optimizer='rmsprop',
loss='binary_crossentropy',
metrics=['accuracy'])
b_model.summary()
# 전체 파라미터 수가 160,305개로 감소
# 모델의 크기를 감소 시켰더니 과대적합 문제에 덜 민감해짐을 시각화로 확인7-2) 규제(Regularization)
모델의 오버피팅을 방지하는 방법 중 규제 가 있습니다.
보통 가중치의 파라미터 값이 커서 오버피팅이 발생하는 경우가 많습니다. 이를 방지하기 위해
큰 가중치 값은 큰 규제를 가하는 방법 이 규제화 입니다.
규제를 통해 가중치의 절댓값을 가능한 작게 만들어서 가중치의 모든 원소를 0에 가깝게 하여 모든 특성이 출력에 주는 영향을 최소한으로 만드는 것을 의미합니다. 즉, 기울기를 작게 만드는 과정이 되겠습니다.
규제를 통해서 가중치의 분포가 더 균일하게 되고, 복잡한 네트워크일수록 네트워크의 복잡도에 제한을 두어 가중치가 작은 값을 가지도록 합니다. 규제가 모델이 과대적합 되지 않도록 강제로 제한하는 역할을 하므로 적절한 규제값을 찾는 것이 중요합니다.
모델의 손실함수에서 큰 가중치에 비용을 추가하는 형태로 규제를 적용할 수 있으며 대표적인 방법으로 L1 규제와 L2 규제가 있습니다. L1 규제는 가중치의 절댓값에 비례하는 비용이 추가되고, L2 규제는 가중치 감쇠(weight decay)라고도 불리며, 가중치의 제곱에 비례하는 비용이 추가됩니다. 또한, L1과 L2를 둘다 합쳐서 사용하는 경우도 존재합니다.
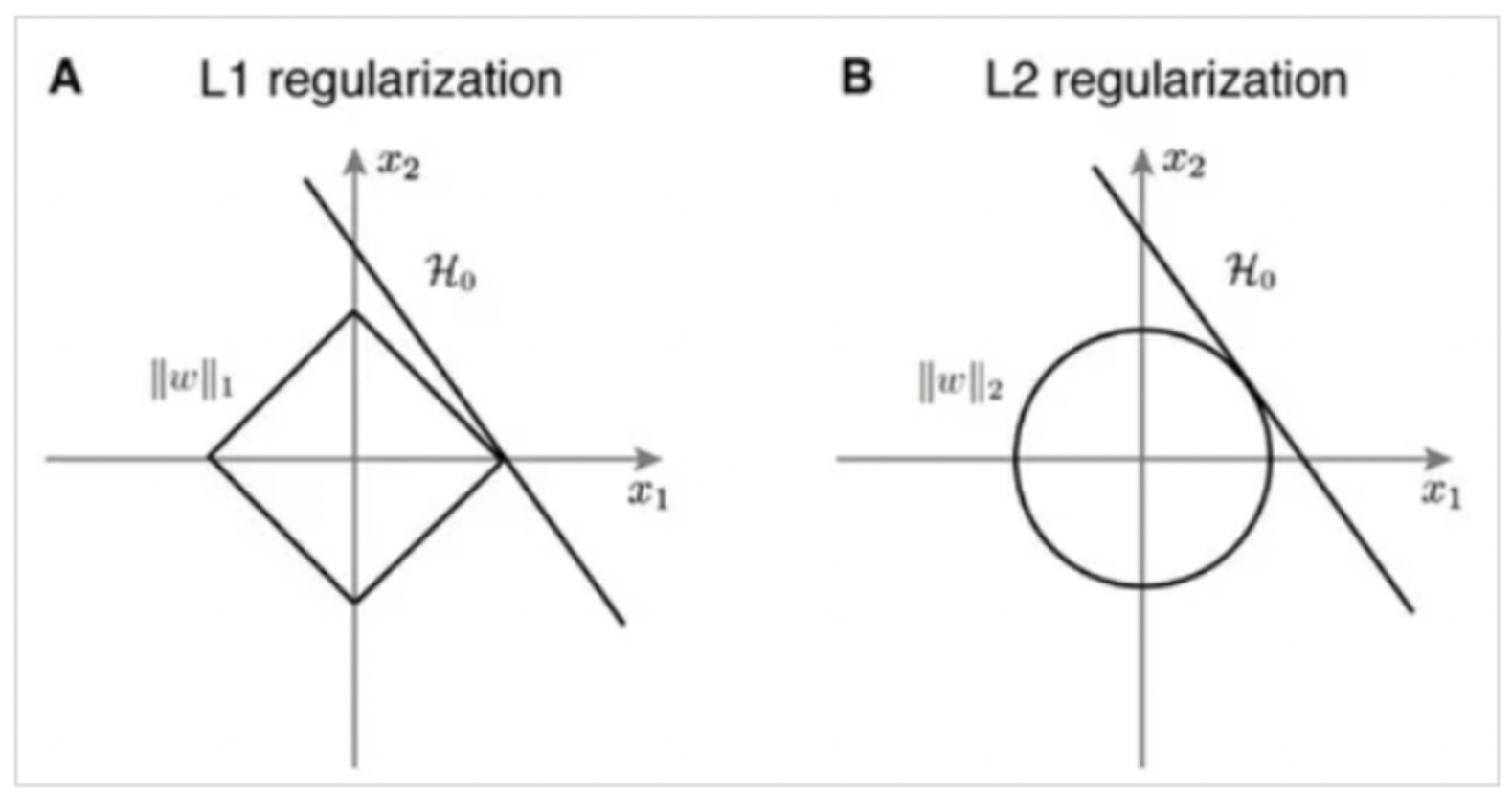
- L1 규제
L1 규제는 가중치의 절댓값 합에 비례하는 비용을 손실 함수에 추가 하는 방법이며, 가중치의 절대값은 L1 노름(norm) 이라고 합니다
절대값들의 합에 하이퍼파라미터 알파 값을 곱을 통해 규제의 조절이 가능합니다. 규제는 레이어 안에 arg로 구현합니다
- L2 규제
L2 규제는 가중치의 제곱에 비례하는 비용을 손실 함수의 일정 값에 더하는 방법 이며, 가중치의 제곱은 L2 노름(norm) 이라고 하며 다음과 같이 표현됩니다.
하이퍼파라미터 람다를 가중치 제곱의 합과 곱을 통하여 규제를 조절 합니다. 람다 값이 커지면 가중치 감소(weight decay)가 커지고, 작으면 규제가 적어 집니다. L1 qhek Robust한 모델을 생성하므로 많이 사용 됩니다
(Robust : 입력값의 작은 변화에 출력값이 크게 변하지 않는것을 뜻합니다. 즉, 예민하지 않다)
7-3) Dropout
딥러닝 모델의 과대적합을 방지하기 위한 규제 기법 중 하나로 자주 사용되는 드롭아웃이 있습니다. 다른 규제 기법과 달리 드롭아웃은 개념도 쉽고 효과적이며 사용하기도 간편하여 가장 널리 사용되는 방법입니다. 드롭아웃은 모델이 학습할 때 사용하는 노드의 수를 전체 노드 중에서 랜덤한 일부만을 사용 하는 방법입니다.
Dropout layer를 생성하고 (%로 확률을 정해줍니다) 위치는 입력 레이어 다음에 추가합니다. 입력 피처에 대한 오버피팅을 방지하기 위함 입니다. 은닉층 사이에 추가하여 모델의 복잡성을 줄일 수도 있습니다. 출력 층 이전에 입력 하여 출력 레이어의 오버피팅도 방지합니다
<Dropout 코드>
model = models.Sequential()
model.add(layers.Dense(16, activation='relu', input_shape=(10000, )))
# Dropout layer 추가 (20%)
model.add(layers.Dropout(0.2))
model.add(layers.Dense(16, activation='relu'))
# Dropout layer 추가 (20%)
model.add(layers.Dropout(0.2))
model.add(layers.Dense(1, activation='sigmoid'))
model.compile(optimizer='rmsprop',
loss='binary_crossentropy',
metrics=['accuracy'])
model.summary()<Dropout 과정 그림>
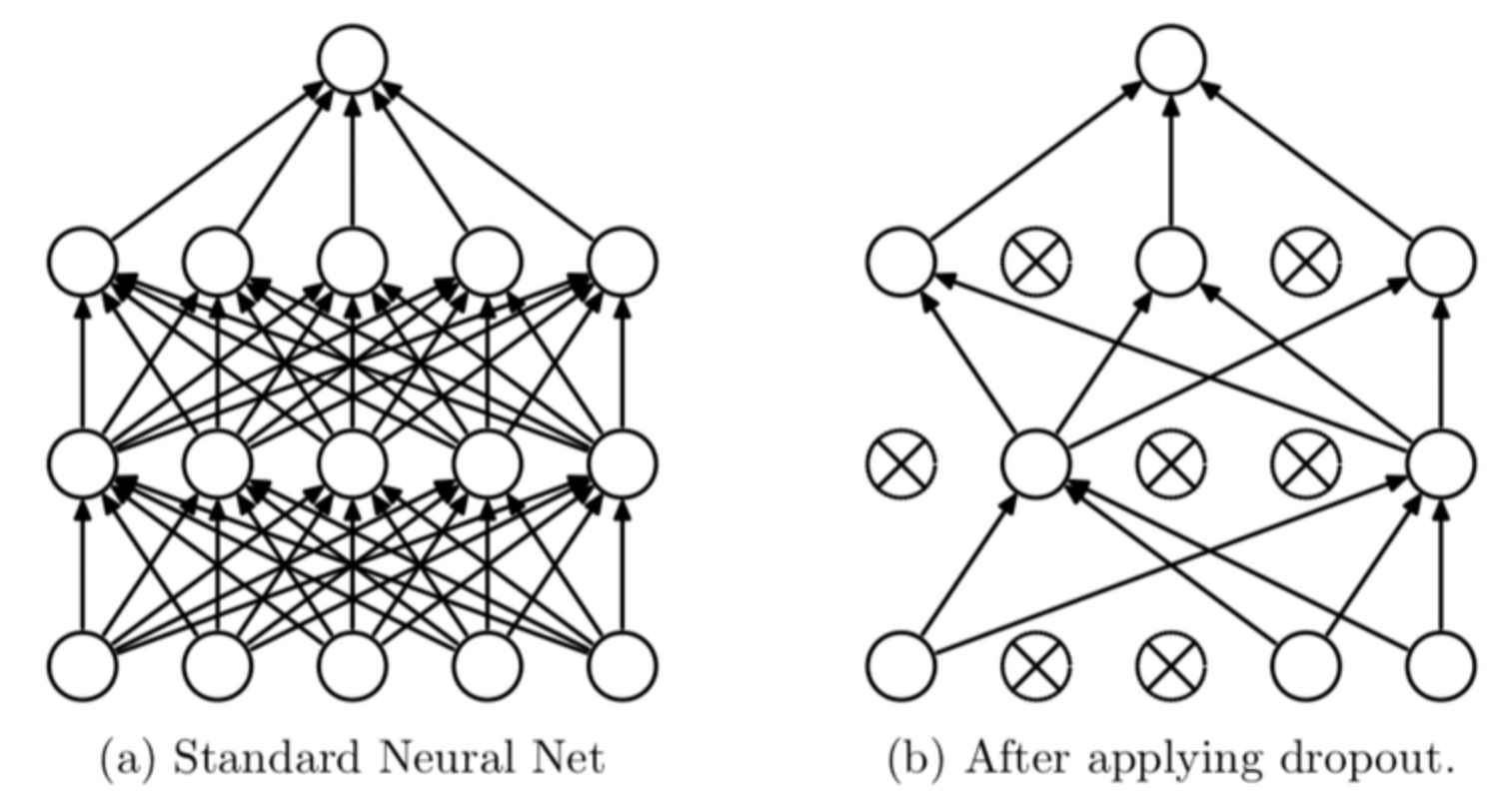
8. 가중치 초기화와 배치 정규화(Batch Normalization)
8-1) 가중치 초기화 (Weights Initialization)
모델의 초기 가중치 값을 설정 해주는 것으로 모델 성능에 큰 영향을 미칩니다.
가중치의 분포가 일부 값으로 치우치거나 0,1로 모이게 되면 활성화 함수를 통과한 값들도 치우치게 되면서 표현할 수 있는 신경망의 수가 적어집니다(기울기 소실(Vanising gradient), 폭주 등)
즉, 모델의 활성화 값이 골고루 분포 되는 것이 중요합니다.
<초기화의 종류>
A. 제로 초기화(.Zeros()) : 초기값을 0으로 설정, 모든 가중치 값이 같아진다 (역전파 포함)
B. 정규분포 초기화(RandomNormal()) : 정규분포를 따르도록 무작위 값 초기화, 제로보다는 퍼지지만 여전히 신경망의 표현을 제한합니다
C. 균일분포 초기화(RandomUniform()) : 균일분포를 따르는 무작위 값으로 초기화한 결과도 제로 초기화보다는 분포가 퍼져있는 것을 알 수 있습니다. 그러나 활성화 값이 균일하지 않으므로 역전파로 전해지는 기울기 값이 사라질 수 있습니다(기울기 소실)
D. Xavier 정규분포 초기화(GlorotNormal()) : 비교적 분포로 고르고 레이어마다 표현이 잘 됩니다. 즉, 더 많은 가중치에 역전파가 전달이 가능하게 됩니다. 일반적으로 Xavier(Glorot) 방법은 활성화 함수가선형함수인 경우에 매우 적합 합니다.
E. Xavier 균일분포 초기화(GlorotUniform())
F. He 정규분포 초기화(HeNormal()) :표준편차 루트 2/n 분포로 초기화, 활성화값 분포가 균일하게 분포되어 있습니다. 참고로 ReLU와 같은 비선형함수 일 때 더 적합하다고 알려진 초기화 방법입니다.
G. He 균일분포 초기화(HeUniform())
8-2) Reuters 딥러닝 모델 예제 (생략 추후 추가!)
8-3) 배치 정규화(Batch Normalization)
배치 정규화는 모델에 입력되는 샘플들을 균일하게 만드는 방법으로 가중치의 활성화값이 적당히 퍼지게끔 '강제'로 적용 시키는 것을 의미합니다.
보통 미니배치 단위로 데이터의 평균이 0, 표준편차는 1로 정규화를 수행하여 학습 자체가 빨리 진행될 수 있도록 만들어주고, 학습 후에도 새로운 데이터에 일반화가 잘 될 수 있도록 도와줍니다. 또한, 초기값에 크게 의존하지 않아도 되고, 과대적합을 방지하는 역할을 수행합니다.
배치 정규화는 데이터 전처리 단계에서 진행해도 되지만 정규화가 되어서 레이어에 들어갔다는 보장이 없으므로 주로 Dense 레이어 이후, 활성화 함수 이전에 활용됩니다.
Dropout 계층과 같이 사용하면 오버피팅 방지에 좋습니다. 이유는 서로 보완적인 기법이며, Batch Normalization은 학습 시간을 단축하고 안정성을 높이는 데 도움을 주고, Dropout은 다양한 뉴런 조합을 학습하여 일반화 능력을 향상시킵니다. 이러한 조합은 모델의 성능을 향상시키고 과적합을 방지하는 데 유용합니다.
<적용 코드 예시>
import tensorflow as tf
from tensorflow.keras import models, layers
model = models.Sequential()
model.add(layers.Dense(128, input_shape=(10000, ), name='input'))
# Batch Normalization 계층 추가
model.add(layers.BatchNormalization())
model.add(layers.Activation('relu'))
model.add(layers.Dense(128, name='hidden'))
# Batch Normalization 계층 추가
model.add(layers.BatchNormalization())
model.add(layers.Activation('relu'))
model.add(layers.Dense(46, activation='softmax', name='output'))
model.compile(optimizer='rmsprop',
loss='categorical_crossentropy',
metrics=['accuracy'])
model.summary()정리하자면 오버피팅 방지 여러 방법 중 분포를 고르게 해서 표현력을 높게 해주는 방법으로는 '가중치 초기화' & '배치 정규화' 가 있습니다.
오버피팅 방지 방법 중 '규제'와 규제 같은 'Dropout'이 있습니다
오버피팅 방지 방법 중 모델의 크기를 조절하는 방법으로는 '뉴런의 수 조절' & '레이어 수 조절' 있습니다
추가로 '데이터 증강' & '하이퍼 파라미터 조절' 등 최적의 매개변수들을 찾는 것 입니다