자연어 처리
- 목차
- 자연어 처리 기초
- 감성 분석 실습
- 자연어 전처리
1. 자연어 처리 기초
- 형태소 분석 (형태소 : 의미를 가지는 요소로서는 더 이상 분석할 수 없는 가장 작은 말의 단위
- 어휘 사전 구축 (벡터화, 인코딩)
대표 인코딩 방법
1) CountVectorizer : 각 문장에서 단어 출현 횟수를 카운팅 하는 방법 (BOW, Bag Of Word)
2) TfidfVectorizer : 다른 문서보다 특정 문서에 자주 나타나는 단어에 높은 가중치를 주는 방법 (다른 문서와 내 문서의 겹치지 않는 단어에 가중치(비중)를 높게 주는 방법), 학습을 골고루 할 수 있게 해주려고?
형태소 분석기 : 문장을 토큰화 하는 것
- konlpy : 한국어 처리를 위한 형태소 분석기
- 형태소 : 가장 작은 말의 단위
# 라이브러리 불러오기
import pandas as pd
import warnings
warnings.fillterwarnings('ignore')
# konlpy 설치
!pip install konlpy
# 라이브러리 불러오기 (Okt)
import konlpy
from konlpy.tag inmport Okt
tokenizer = Okt()
# 토큰화 (형태소 단위)
text = "함께 탐험하며 성장하는 AI 학교 AIFFEL"
tokenizer.morphs(text)
# 토큰화 (명사만 추출)
tokenizer.nouns(text)
# 토큰화 (품사 태깅)
tokenizer.pos(text) CountVectorizer
# CountVectorizer
from sklearn.feature_extraction.text import CountVectorizer
vect = CountVectorizer()
# 단어 토큰화 (Okt)
words = tokenizer.morphs(text)
# 데이터 학습 : CountVectorizer 알고리즘에 의해 학습 된다
vect.fit(words)
# 학습 된 어휘 확인
vect.get_feature_names_out()
# 단어 사전
vect.vocabulary_
# 단어 사전 크기
len(vect.vocabulary_)
# 인코딩
df_t = vect.transform(words)
# 인코딩 된 데이터 Matrix
df_t.toarray()
# 어휘와 피처 매칭해서 보기 (DataFrame)
df = pd.DataFrame(df_t.toarray(), columns=vect.get_feature_names_out()) # 최신 버전은 out 없이 사용)
# test (새로운 단어가 들어왔을 경우)
test = "AI 공부하며 함께 성장해요!"
# 단어 토큰화 (Okt)
words = tokenizer.morphs(test)
# 인코딩 된 데이터 행렬 (위에 학습된 사전을 가지고 할 것이라 transform만 하면 된다)
test_t = vect.transform(words)
test_t.toarray()
# 어휘 피처 매칭
test_t = pd.DataFrame(test_t.toarray(), columns=vect.get_feature_names_out())TfidfVectorizer
# tf-idf (방법은 CountVectorizer 와 동일하다)
from sklearn.feature_extraction.text import TfidfVectorizer
# tf-idf 활용 어휘 사전 구축
vect = TfidfVectorizer()
words = tokenizer.morphs(text)
vect.fit(words)
vect.vocabulary_
# 인코딩 된 데이터 행렬
vect.transform(words).toarray()2. 감성 분석 실습
- 머신러닝 프로세스
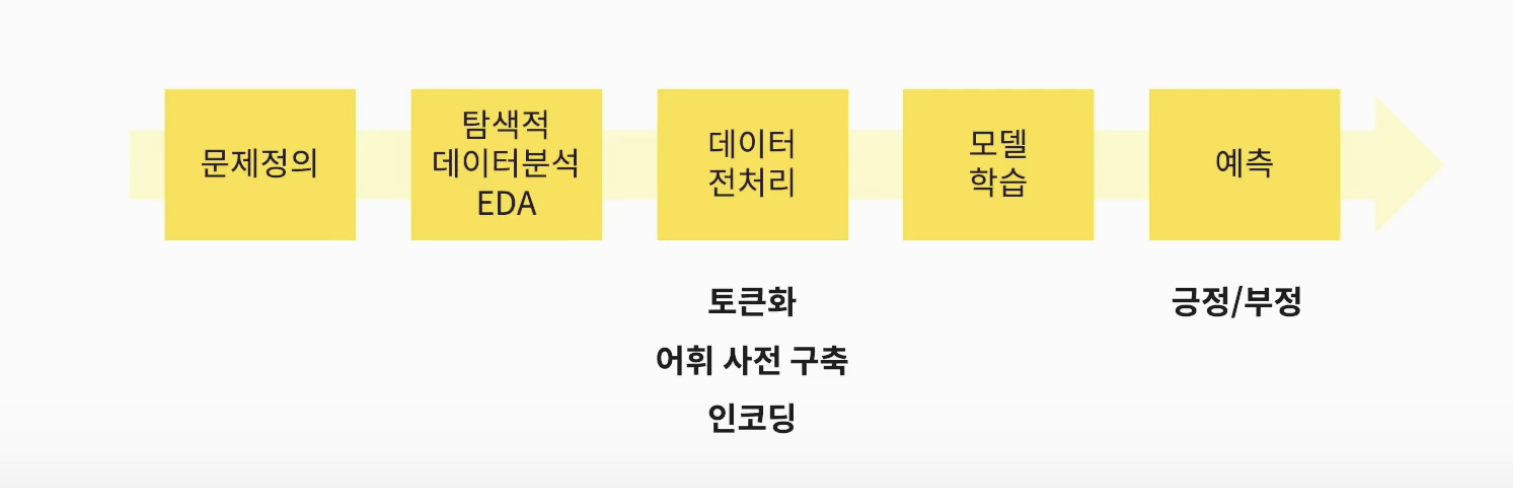
- 자연어 전처리 과정
1) 토큰화
2) 어휘 사전 구축 (형태소 쪼개기(Okt), 학습(fit))
3) 인코딩 (transform)
# 데이터 불러오기
라이브러리, 데이터(csv_load)
# EDA 및 데이터 전처리
# 데이터 샘플
df.head()
# 데이터 크기
df.shape
# target 확인
df['label'].value_counts()
# 결측치 확인
df.isnull().sum()
# 얼마 없는 결측치는 삭제
print(df.shape)
df.dropna()
print(df.shape) # 삭제 됐는지 확인
# 피처 엔지니어링 (문장의 길이)
df['len'] = df['document'].apply(len)
# len 시각화 (label == 0)
import matplotlib.pyplot as plt
df[df.label==0]['len'].plot(kind='hist') # 부정일때 확인
# label == 1
df[df.label==1]['len'].plot(kind='hist') # 긍정일때 확인
# 데이터 샘플링 df[:1000] (데이터가 너무 커서 샘플링)
df = df[:1000]
# 토큰화
vect = CountVectorizer(tokenizer = tokenizer.morphs) # 위에 Okt로 토큰화 저장해두었음
vectors = vect.fit_transform(df['document'])머신러닝 교차 검증
# 머신러닝 > 교차검증(f1)
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import cross_val_score
model = RandomForestClassifier(random_state=2022)
cross_val_score(model, vectors, df['label'],scoring='f1',cv=5).mean()3. 자연어 전처리
- 어휘 사전 구축
1) 00% 이상 나타나는 단어 무시
2) 최소 N개의 문장에만 나타나는 단어만 유지 - 불용어(stopword)
1) 큰 의미가 없는 단어
2) 예) 을,는,이,가, 여기, 저기 - 띄어쓰기
- 반복되는 글자 정리
- 맞춤법 검사
어휘 사전 구축
# 토큰화(max_df) N개 보다 큰 단어 수 무시
vect = CountVectorizer(tokenizer.morphs, max_df=10) # 10번이상 나온 단어는 무시 해라!
# 토큰화(min_df) N개 보다 작은 단어 수 무시
vect = CountVectorizer(tokenizer.morphs, min_df=2) # 2번 보다 작게 나온 단어들은 무시해라!불용어(stopword) : 불필요한 단어는 제외 시키기 위함
text = "함께 탐험하며 성장하는 AI 학교 AIFFEL"
stop_words = ['하며','ai']
vect = CountVectorizer(stop_words = stop_words)띄어 쓰기 : Spacing
# Spacing 라이브러리 호출
from pykospacing import Spacing
spacing = Spacing()
text = ~~~~
spacing(text)반복되는 글자 정리 : soynlp
# 라이브러리 호출
from soynlp.normalizer import *
emoticon_normalize('하하하아아아하하하호호호홐ㅋㅋㅋㅋㅋ호호호휴ㅠㅠㅠ', num_repeats=3) # 3번만 반복되게 정의맞춤법 검사기
from hanspell import spell_checker
text = '~~~~~'
# 수정된 문장
result = spell_checker.check(text)
result.checked # 잘 모르는 단어(신조어)들은 띄어쓰기, 맞춤법 검사 안될 수 있다
비전공자지만 밑바닥부터 공격적으로 공부중입니다! 공부 해온 것들 정리해보고 있습니다. 잘못 된 부분 있으면 알려주세요~ 서로 공유 하고 싶습니다