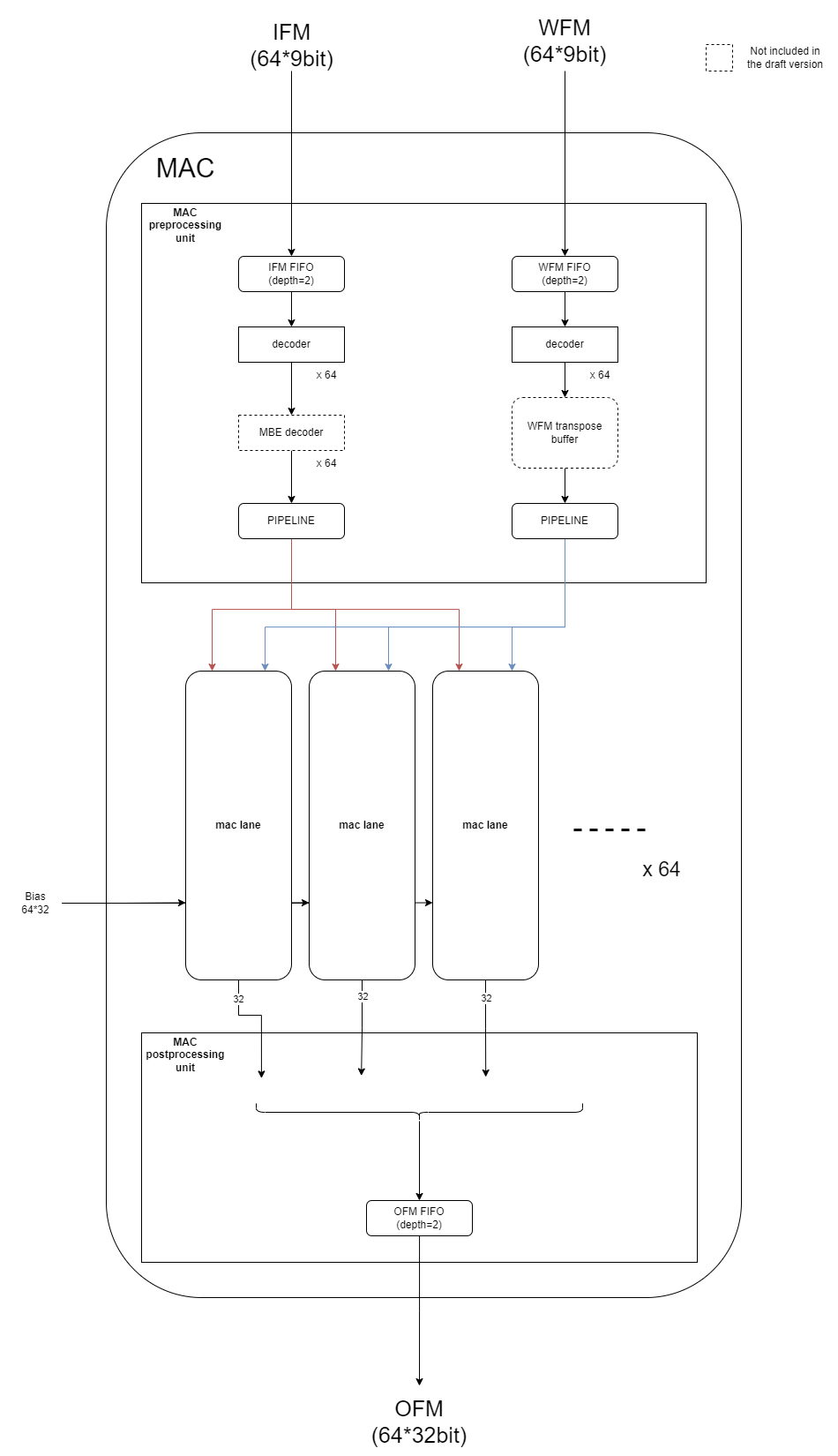
초안 기준 MAC TOP의 Architecture는 이와 같다.
지원하는 data type은 fp16, fp8(1,4,3), int9이다.
1개 mac lane에서는 매 사이클마다 fp8, int9의 경우 64개의 multiply와 addition을 수행할 수 있고 fp16의 경우 그 절반인 32개 가능하다.
mixed multiplication의 경우 fp32가 포함되면 32, 아니면 64이다.
mac 모듈에는 lane이 64개 있으므로 fp8, int9의 경우 64*64 per cycle, fp16은 32*64 per cycle이 된다.
전체 구조를 간단하게 설명하자면 MAC은 preprocessing 단계, arithematic 단계, post processing 단계로 나누어져 있다.
preprocesing 단계에서는 arithematic 단계에서 계산이 이루어질 수 있도록 들어온 data를 decoding하고 정렬하는 일을 수행한다.
마지막의 pipeline을 따로 표시한건 preprocessing에서의 최종 data들이 arithematic 단계를 담당하는 64개의 mac lane으로 보내지게 되는데
각 mac lane도 크기가 상당한데 64개나 되는 lane들에 크기가 큰 data들을 전부 보내줘야해서 그냥 그대로 두면 PnR 단계에서 문제가 생긴다.
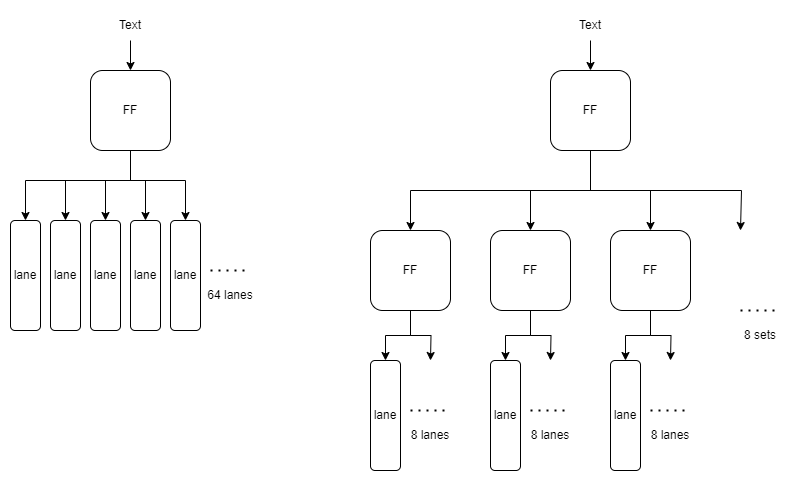
그래서 데이터 1 set을 저장한 flip flop -> 64 lanes으로 바로 보내는 방식이 아니라 1 set flip flop -> 8 flip flops -> 64 lanes 이런 식으로 단계를 나눠서 PnR이 좀 더 쉽게 이루어 질 수 있도록 한다.
중간의 8개 FF에는 전부 같은 data가 저장되어 있다. 그러니 합성할 때 해당 인스턴스에 대해 register merging 옵션 등을 조정해서 하나로 합쳐지는걸 방지해야한다.
MBE decoder와 WFM transpose buffer는 초안에서 빠져서 점선으로 표시되어 있다.
MBE decoder의 경우는 이걸 설계할 경우 multiplier도 이에 맞게 설계해줘야 하는데 그러기엔 시간이 많이 걸릴거 같아서 일단 초안에서는 빠졌다.
WFM transpose buffer의 경우 아직 이걸 넣어야할지 말아야할지 확정하지 못해서 일단 초안에서는 뺐다. transpose buffer는 크기가 커질 경우 congestion 이슈가 발생하기 쉬운데 고민해보고 굳이 필요가 없다면 아예 빼서 문제가 발생하지 않게 할 예정이다.
arithematic 단계에서는 각 mac lane에서 multiply & addition의 연산이 이뤄진다.
mac lane끼리는 서로 data를 주고 받지 않고 독립적이다.
각 lane의 구조는 다음과 같다.
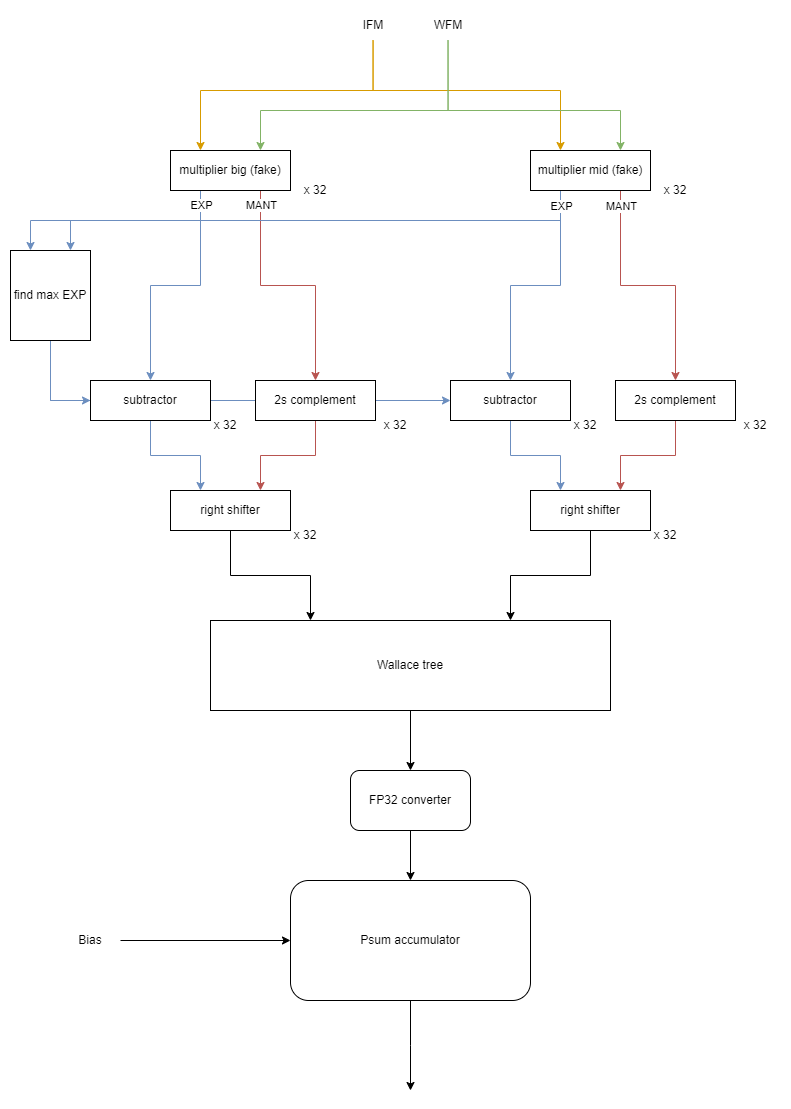
먼저 multiplier에서 IFM과 WFM data의 곱셈을 수행한다.
이때 multiplier로 들어오는 IFM과 WFM은 이미 preprocessing 단계에서 decoding 되어 sign, exp, mant가 분리되어있다.
즉 만약 int로 -9였다면 sign 1, exp 0, mant 9 이런식으로 들어온다. floating point의 경우는 애초에 sign, exp, mant가 분리되어 있으므로 그대로 들어온다.
이후 exp과 mant가 처리되는 경로에 약간 차이가 있다.
exp는 find max로 보내져서 64개 exp 중 가장 큰 값을 찾고 해당 값에서 각 exp 값을 뺀다.
mant의 경우 2's complement를 통해 다시 부호를 갖게 한다.
이렇게 처리된 exp와 mant는 right shifter로 보내져서 자릿수를 맞추고 wallce tree에서 덧셈이 이루어진다음 fp32 converter에서 fp32로 변환된다.
그 다음 Psum accumulator로 보내지는데 해당 모듈의 구조는 다음과 같다.
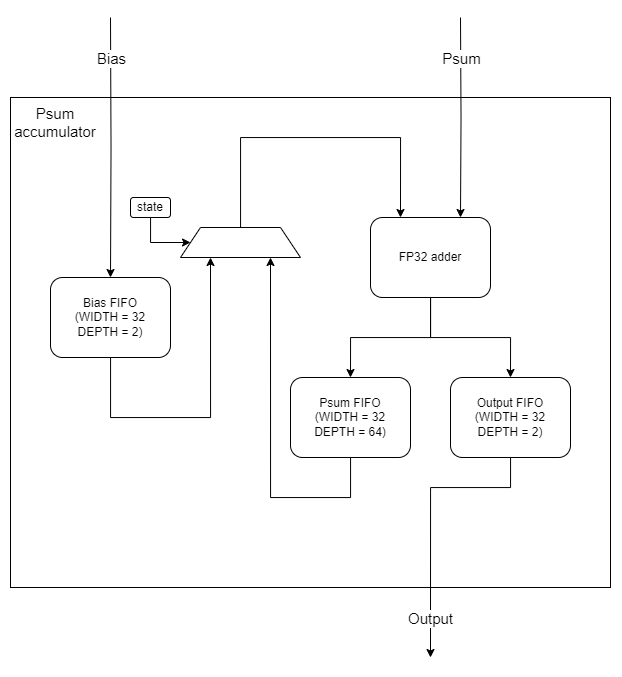
Psum accumulator는 아직 계산이 완전히 끝나지 않은 psum들을 저장해두었다가 다시 계산에 쓰는 모듈이다.
예를 들어서 64x128 x 128x64 의 matrix multiplication을 수행한다고 하자.
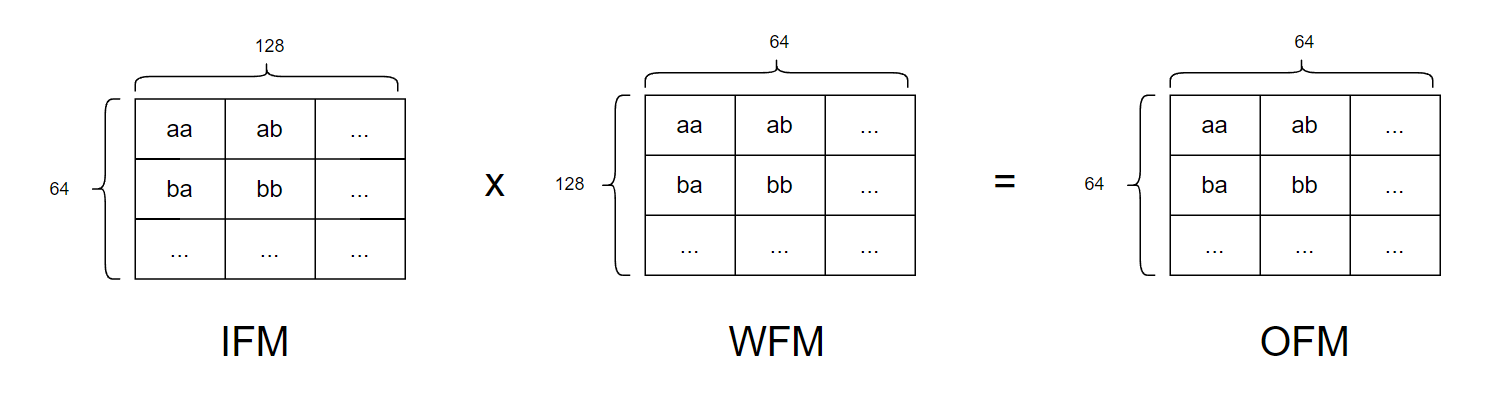
이때 data reuse를 위해 WFM을 최대한 고정시킨다고 하면 계산은 이런 식으로 이루어지게 된다.
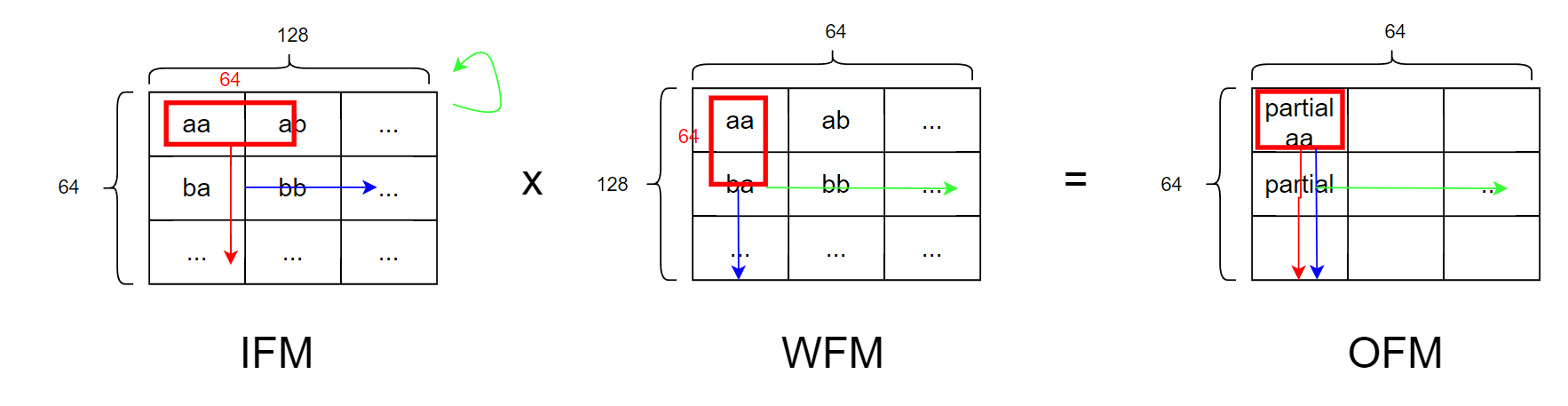
순서는 빨간화살표 -> 파란색 -> 연두색이다.
OFM의 element 1개를 채우기 위해선 128번의 multiplication이 필요한데 mac lane은 1 cycle 당 64개밖에 못한다.
그래서 2 cycle에 걸쳐서 계산해야하는데 이걸 바로 다음 cycle에 연달아 해버리면 WFM도 바뀌어야해서 WFM data를 reuse 할 수 없다.
그래서 WFM data를 최대한 쓸 수 있는 때까지 reuse를 하고 바꾸기 위해서 이런 순서로 연산을 한다.
이 과정에서 중간에 아직 계산이 완료되지 않은 부분합이 저장되었다가 다시 연산에 쓰여서 최종적인 OFM이 나오게 되는데 이 부분합을 저장하기 위한게 설계 그림의 Psum FIFO이다.
Psum FIFO의 depth가 64이므로 최대 64번 WFM data를 reuse 할 수 있다.
1개 element당 128 multiplication이 아니라 그보다 더 늘어나도 이 과정을 여러번 반복하면 그만이라 문제 없이 연산 가능하다.
이렇게 최종적인 연산이 끝나면 계산은 전부 완료되었으므로 postprocessing 모듈로 각 lane의 값을 모아서 보낸다.
postprocessing 단계는 지금 비어있다. 왜냐하면 본래 여기서 수행해야할 것들을 그 다음 모듈인 datatype converter로 전부 옮겼기 때문이다.
다만 혹시 처리해야할 것들이 있을지 몰라서 일단 모듈 자체는 남겨두었는데 나중에 없는걸로 확정되면 삭제할 예정이다.

아래 채용 공고에 관심 있으시면 한번 검토 해보시면 좋지 않을까 생각합니다.
https://talent.hyundai.com/apply/applyView.hc?recuYy=2024&recuType=N2&recuCls=841