범용적인 NPU 개발기
1.범용적인 NPU 개발기(0) - 들어가기 앞서

상반기 구직에 실패하고 붕 뜬 시기.무엇을 할까 고민하던 중 마침 이전에 제대로 끝마치지 못했던 NPU, 정확히는 범용적인 CNN 가속기를 제대로 설계해볼까 하는 마음이 들었다.
2.범용적인 NPU 개발기(1) - 설계계획(1)
범용적인 CNN 가속기 input의 크기, weight의 개수에 상관없이 convolution을 수행할 수 있을 것
3.범용적인 NPU 개발기(2) - 아키텍처(1)
일단 기존의 CNN 가속기 아키텍처 2가지를 알아보자 각각 systolic array 방식과 adder tree 방식인데 먼저 systolic array 방식부터 알아보자
4.범용적인 NPU 개발기(3) - 아키텍처(2) - convolution
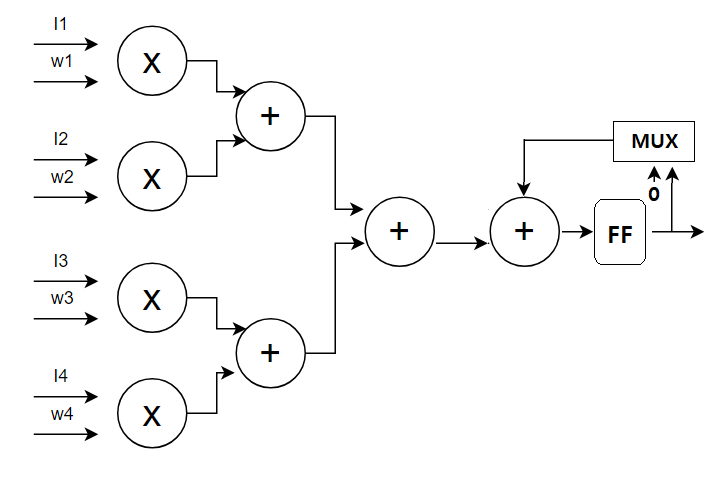
내가 생각한 convolution layer를 수행하기 위한 아키텍처는 2가지가 있는데 한가지는 구현이 쉽지만 효율이 떨어질 것으로 예상되는 것이고 다른 하나는 효율이 좋지만 구현이 어려울 것으로 예상되는 구조이다.후자는 코드 작성에 들어가기에 몇가지 문제점이 남아있어
5.범용적인 NPU 개발기(4) - 아키텍처(3) - Relu, maxpooling
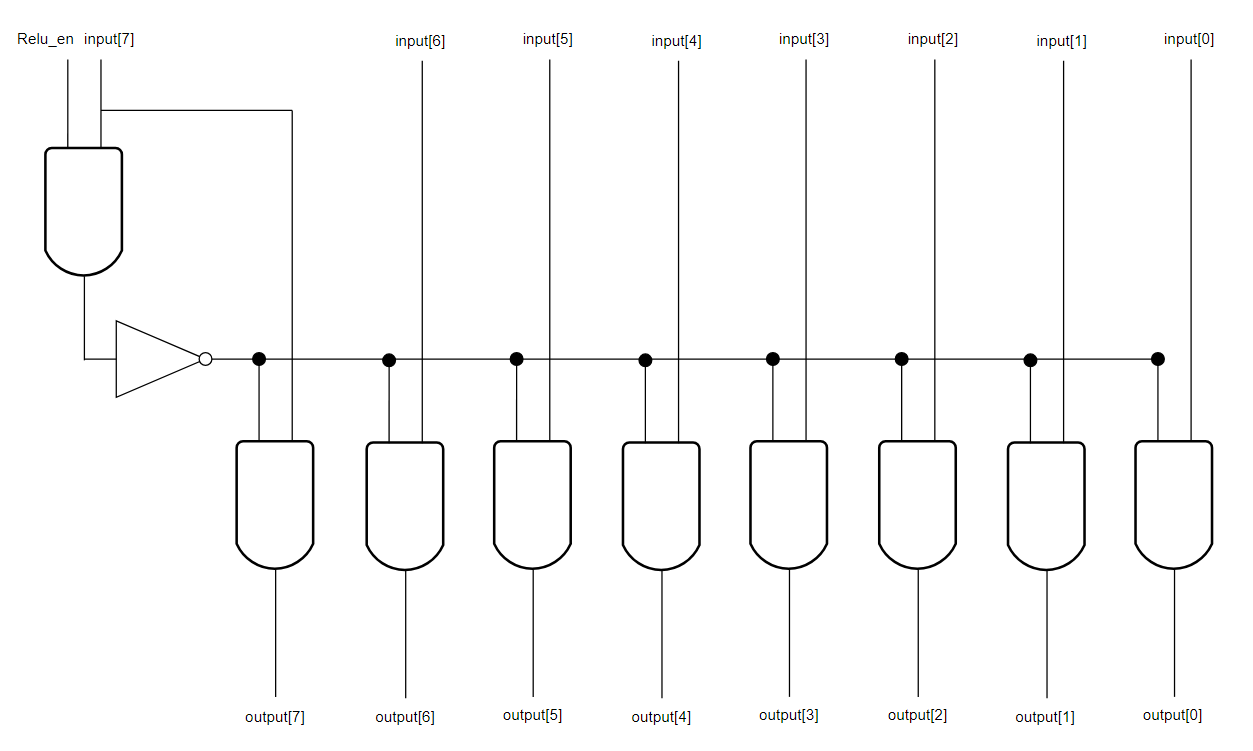
NPU의 연산부는 convolution, Relu, maxlooling을 수행할 수 있어야한다. 이전 포스팅에서 convolution을 다루는 부분을 설명했으니 다음은 Relu와 maxpooling을 수행하는 모듈에 대해 설명해보자.
6.범용적인 NPU 개발기(5) - 코드 및 설명(1) - arithmetic_core
코드 작성하고 디버깅하느라 이전 포스팅을 올리고 많은 시간이 지났다. 현재 코드 작성을 완료하고 테스트벤치 등을 통해 functionality check를 끝낸 상태인데 본래라면 synthesis를 하고 그 결과에 따라 더 최적화를 진행하겠지만 아쉽게도 나는 더이상
7.범용적인 NPU 개발기(6) - 코드 및 설명(2) - processing_element(1)
친구의 조언을 받아들여 깃허브를 만들었다.https://github.com/thousrm/universal_NPU-CNN_accelerator/tree/main버전 관리에 용이해보여 적극적으로 이용할 생각이다.모듈의 이름을 직관적이지 못하게 지었는데 사실 기능
8.범용적인 NPU 만들기(7) - 코드 및 설명 - processing_element(2)
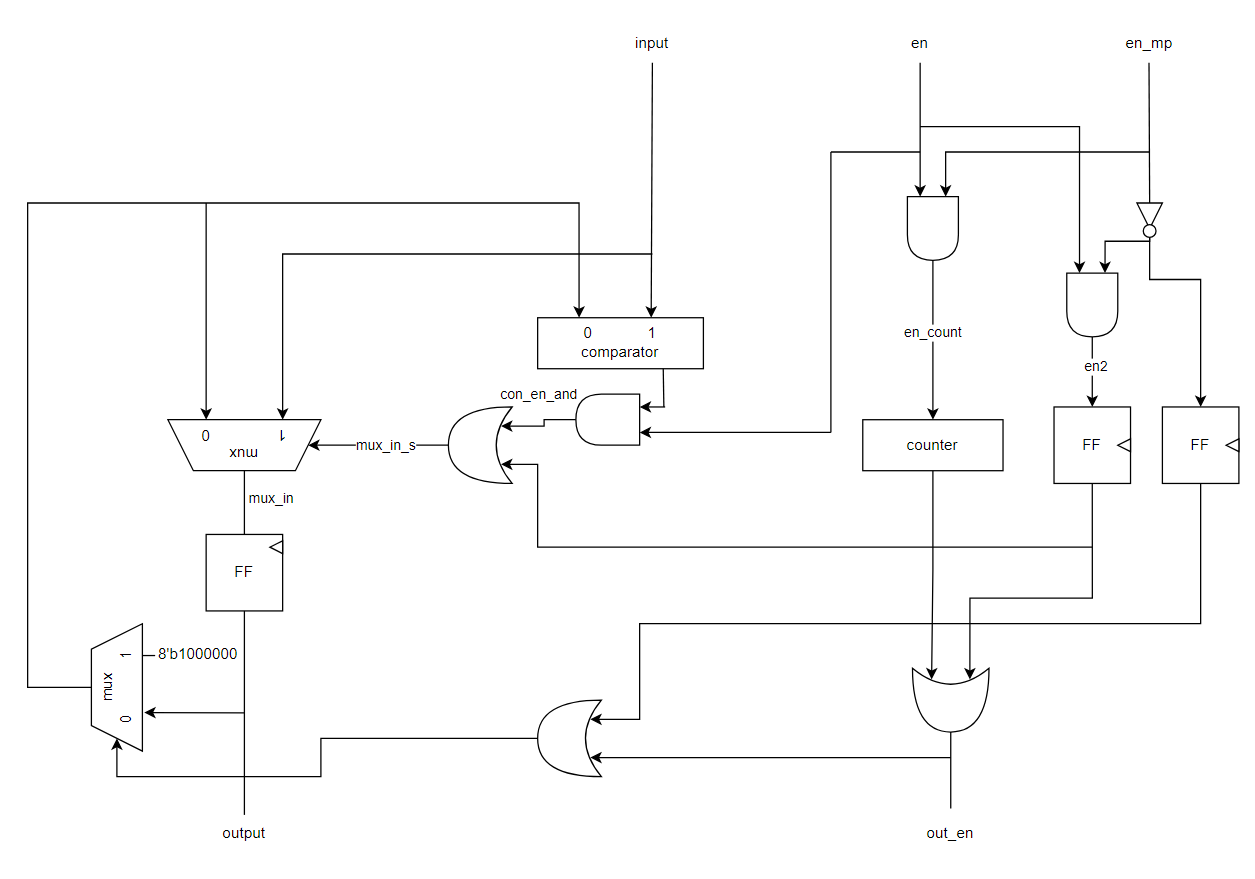
내 생각에 하드웨어 디자인에서 오류가 나는 대부분의 경우는 timing 문제인 것 같다. 내가 아직 간단한 모듈들만을 디자인해봐서 그런걸지도 모르지만 개개의 세부 부분들이 기능적으로 잘못 작동하는 경우는 거의 없었고 있더라도 수정하기 쉬웠다. 자꾸 오류가 나서 디버깅을
9.범용적인 NPU 만들기(8) - 코드 및 설명 - Relu, maxpooling
Relu는 애초에 매우 간단한 구조라 이전에 설명했던 것과 동일한데 maxpooling은 이전에 생략한게 좀 있었고 또 중간중간 수정한 부분이 있어 설명이 필요하다.ReluRelu 모듈은 추후 BN 기능을 추가할 예정이나 아직 곱셈기를 설계하지 못했기 때문에 일단은 R
10.범용적인 NPU 만들기(9) - 곱셈기(1) - 이론(1) - signed multiplication
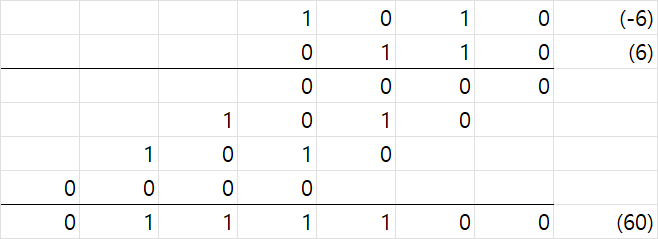
이전 포스팅을 작성한지 상당한 시간이 지났다. 지난 포스팅에서 processing element의 설계가 끝나 그동안 곱셈기에 대해 공부하고 아키텍처를 설계하고 있었다.이전에 말했듯이 효율적인 곱셈기+덧셈기를 설계하는 것은 그 자체로 하나의 프로젝트라 할 수 있는 정도
11.범용적인 NPU 만들기(10) - 곱셈기(2) - 이론(2) - Modified Booth Algorithm

오늘은 중요한 알고리즘인 Modified Booth Algorithm(이하 MBE)에 대해 설명할 예정이다. 현재 설계하는 곱셈기는 MBE + Wallace tree 방식으로 설계할 예정이다. wallace tree에 대해서는 다음 포스팅에서 다루겠다. 간단하게 요약
12.범용적인 NPU 만들기(11) - 곱셈기(3) - 이론(3) - Wallace Tree
https://github.com/thousrm/universal_NPU-CNN_accelerator/releases/tag/0.1첫 릴리즈 버전이 5일 전 출시되었다. 아직 Arithmetic Part만이 구현되어있다.저번 포스팅을 올리고 한달 가까이 지났다
13.범용적인 NPU 만들기(12) - 곱셈기(4) - 아키텍처
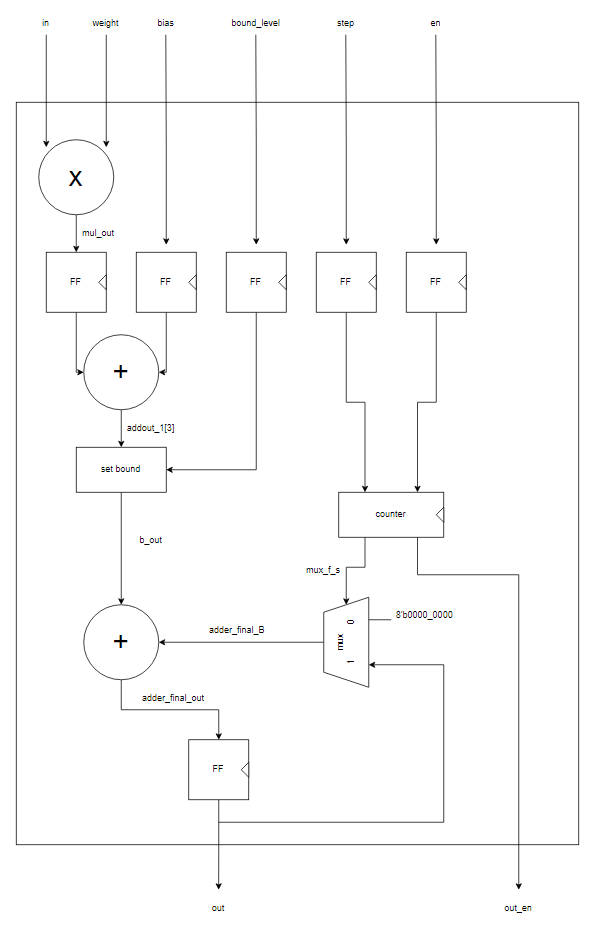
이전의 간이로 설계하였던 곱셈기에서 제대로 된 설계로 바뀌면서 processing_element 모듈에 변화가 생겼다. multiplier가 input feature map과 weight들을 받아들여 partial product들을 생성한 후 adder tree들에
14.범용적인 NPU 만들기(13) - NPU_simple
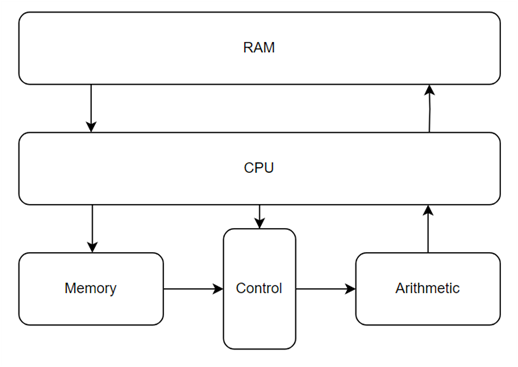
저번주 드디어 필요한 모든 모듈을 갖춘 버전을 릴리즈했다. 해당 버전은 이전의 arithmetic part뿐만 아니라 control part와 memory part도 모두 갖추었으며 cpu의 명령에 따라 cnn 가속기로 온전하게 동작한다.
15.범용적인 NPU 개발기 2nd (0) - 들어가기 앞서
비록 회사도 경력도 폐업과 함께 없어졌지만 그곳에서 갈고 닦은 내 실력은 사라지지 않았다.1년이 안되는 기간동안 나는 뉴블라에서 일일이 나열하기 힘들정도로 매우 많은 것들을 배웠다.지금와서 보면 예전에 내가 짰던 코드는 매우 부끄러운 수준이라 이대로 두기엔 너무 창피하
16.범용적인 NPU 개발기 2nd (1) - TOP Architecture
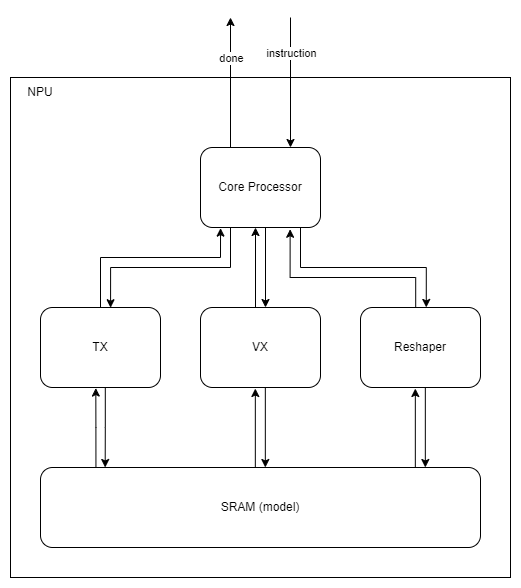
초안 기준 TOP level Architecture는 이와 같다.TX는 Tensor eXecuter의 약자로 convolution이나 matric multiplication과 같은 연산을 수행한다.VX는 Vector eXecuter의 약자로 TX에서 수행하지 못하거나
17.범용적인 NPU 개발기 2nd (2) - TX Architecture
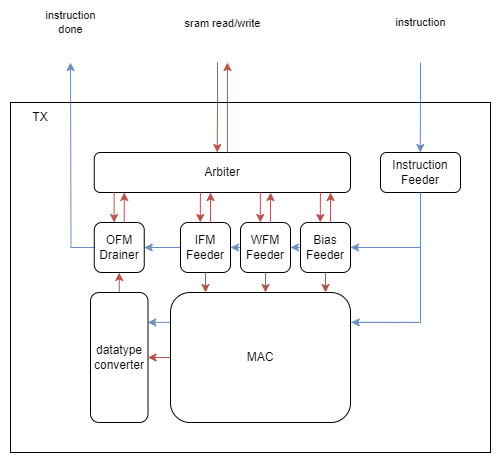
초안 기준 TX의 Architecture는 이와 같다.IFM, WFM, Bias Feeder에서 instruciton에 따라 sram에서 필요한 데이터를 가져오면 MAC에서 이를 계산한 후 datatype converter를 통해 필요한 형식으로 변환한 후 OFM D
18.범용적인 NPU 개발기 2nd (3) - MAC Architecture
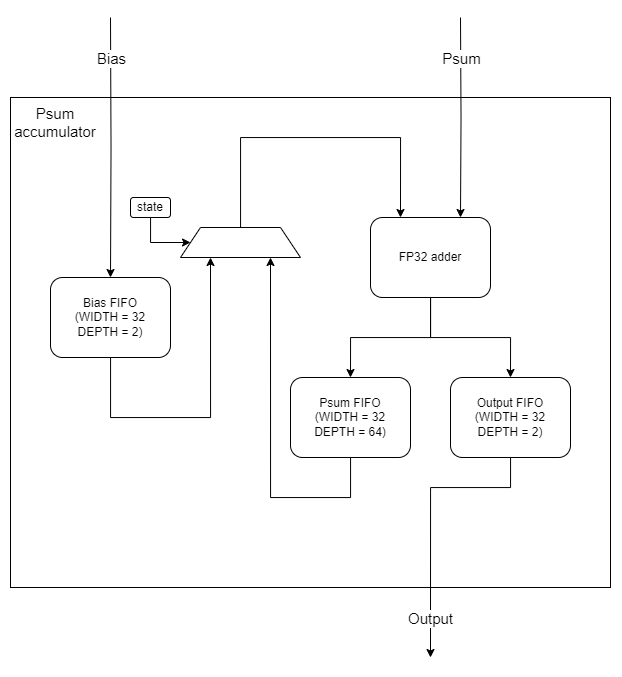
초안 기준 MAC TOP의 Architecture는 이와 같다. 전체 구조를 간단하게 설명하자면 MAC은 preprocessing 단계, arithematic 단계, post processing 단계로 나누어져 있다. preprocesing 단계에서는 arith