이전의 간이로 설계하였던 곱셈기에서 제대로 된 설계로 바뀌면서 processing_element 모듈에 변화가 생겼다.
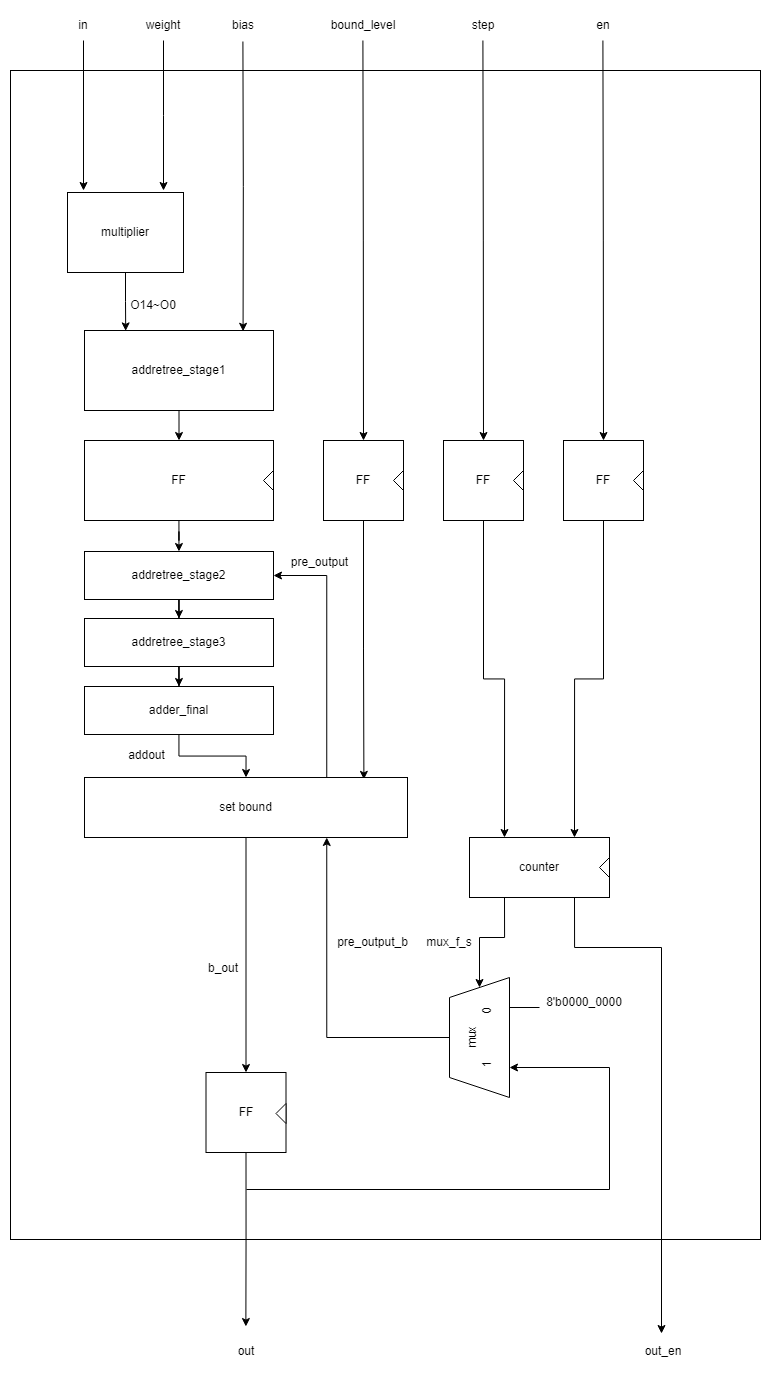
multiplier가 input feature map과 weight들을 받아들여 partial product들을 생성한 후
adder tree들에 의해 합산이 진행되는 구조다. 중간에 pipelining을 위한 FF이 존재한다.
set bound는 이전에 설명했던대로 데이터의 상한값을 정해 하위 비트를 어디까지 사용할지를 정하는 부분이다.
여러 clk cycle에 걸쳐 계산할 경우 이전의 output이 더해지는데 이때 bount_level에 따라 데이터에 수정이 필요하므로 마찬가지로 set bound를 걸쳐 adder tree로 입력된다.
(pre_output_b -> pre_output)
adder tree 내부에는 여러 종류의 adder가 배치되어있다. 이는 이전 포스팅에서 언급하였듯이 wallace tree의 효율을 증가시키기 위해서이다.
adder tree의 input, output, 내부의 배치된 adder의 종류들은 깃허브에서 excel 폴더의 mul_adder.xlsx를 보면 한번에 알 수 있다.
특기할 점은 깃허브에서 코드를 보면 알겠지만 같은 기능을 수행하는 다른 구조의 adder가 여러개 존재한다는 점이다.
이는 언급하였듯 현재 synthesis 툴이 없어서 어느 구조가 가장 효율적인지를 몰라 일단 알아보거나 생각나는 구조들을 전부 작성한 후 남겨두었기 때문이다.
만일 적합한 툴을 가진 사람이 있다면 내게 timing, area, power report를 보내주면 매우 감사하겠다.
사실 synthesis 툴이 없어서 최적화를 매우 제한적으로 수행할 수밖에 없었다.
adder_final
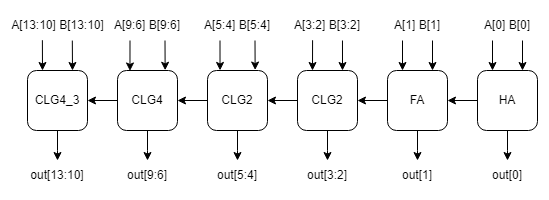
위는 마지막 adder인 adder_final의 구조를 나타낸 것이다.
CLG는 carry look ahead adder를 뜻한다.
adder_final을 설계하는데는 상당히 고민을 많이 했는데 그 이유는 해당 모듈이 processing element의 전체에 상당한 영향을 끼칠 것으로 생각했기 때문이다.
이는 processing element가 구조적으로 파이프라이닝이 제한된다는 단점이 존재하기 때문이다.
구체적으로 말하자면 현 processing element는 9개를 초과하는 weight를 가진 필터를 계산하는데 여러 clk cycle을 쓰는 구조이다.
이 때문에 이전의 output을 input으로 사용하는데 이 점이 파이프라이닝에 제한을 만든다.
무슨 뜻이냐면 일단 이전 output (아키텍처상 pre_output)을 adder의 input으로 사용한 이후 추가적인 파이프라이닝을 하는게 불가능하다.
그렇기에 파이프 라이닝을 추가로 하기 위해선 pre_output을 나중에 받아들여야하고 이는 wallace tree에 구조상 상당한 영향을 미친다. 결과적으로 stage가 하나 더 추가되어야 할 확률이 높다.
현재 stage2 ~ set bound까지 이어지는 흐름에서 추가로 파이프라이닝을 하기가 매우 애매한데 문제는 이 구간의 압박이 상당하다는 점이다.
즉 현재 stage2 ~ set bound 구간의 critical path가 상당히 길어서 아마 전체 모듈의 critical path가 해당 구간으로 잡힐 가능성이 크고 결국 전체 모듈이 해당 구간이 얼마나 빠르게 진행되냐에 영향을 크게 받을 것이다.
그래서 파이프라이닝을 하면 좋겠는데 그러기도 구조상 애매하다. 그렇기에 최대한 최적화를 해야하는데 해당 구간에서 가장 영향이 클것으로 예상되는 하위 모듈이 adder_final 모듈이다.
결과적으로 adder_final의 critical path가 얼마나 빠르게 진행되느냐가 모듈 전체에 큰 영향을 미칠 것이기에 해당 모듈을 설계하는데 상당한 노력을 들였다.
일반적으로 가장 빠르다는 carry look ahead adder를 사용했는데 사실 carry look ahead adder도 어떻게 배치하느냐에 따라 여러 종류가 있다.
block 방식이라던가 recursive 방식이라던가 그 외에도 세부적으로 많은 종류가 있었는데 여러가지 찾아본 결과 초기 2비트를 HA와 FA로 대체하는 block식이 가장 빠를 것으로 예상되어서 이를 채택했다.
다만 이는 내가 직접 synthesis를 해서 낸 결과가 아니라 아마 tool이 주어진다면 설계가 바뀔 수도 있을 것이다.
이것으로 Arithmetic part의 설계가 끝났다. 코드 설명은 너무 길어서 생략할 예정이다. 분량만 많지 구조적으로 복잡하지도 않기 때문이기도 하고.
다음으로 설계할 것은 Memory part와 Control part인데 여러모로 공부해야할게 많고 또 취업 시즌이기도 해서 아마 다음 포스팅은 상당히 늦어질 것 같다.
두서 없는 횡설수설한 일지를 여기까지 읽어주셔서 매우 감사하다.
상당한 나중이 되겠지만 다음 포스팅으로 찾아뵙겠다.

좋은 글 감사합니다