이전 포스팅을 올리고 2달이나 지났다. 그동안 control part와 memory part를 설계하느라 바빠 포스팅을 하지 못했다.
https://github.com/thousrm/universal_NPU-CNN_accelerator/releases/tag/v1.0
저번주 드디어 필요한 모든 모듈을 갖춘 버전을 릴리즈했다. 해당 버전은 이전의 arithmetic part뿐만 아니라 control part와 memory part도 모두 갖추었으며 cpu의 명령에 따라 cnn 가속기로 온전하게 동작한다.
사실 control part와 memory part는 arithmetic part만큼 조사한 후 설계하지 못했다. 그 이유는 찾을 수 있는 정보가 거의 없었기 때문이다.
arithmetic part의 경우 효율적인 adder의 구조나 partial product 생성법 등 많은 정보를 찾을 수 있었지만 다른 둘의 경우는 아키텍처마다 그 구조가 크게 상이하기도 하고 애초에 관련한 정보를 찾기도 어려웠다.
어쩌면 내가 제대로 못찾은 것뿐일지도 모르지만... 참고할 수 있는 것들이 적었기에 처음부터 복잡한 구조의 control과 memory를 설계하기는 어려웠고 이것이 비용 대비 효율적인지도 알 수 없었다. 그래서 우선적으로 기본적인 기능만을 갖춘 버전을 설계하기로 했고 이름이 simple인 이유가 바로 이것이다.
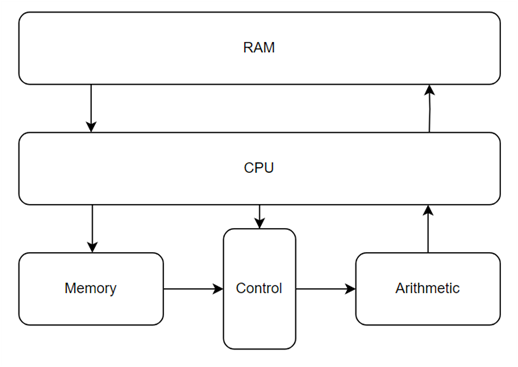
해당 버전에서 control part는 기능이 거의 전무하다. 스스로 판단하는 것은 없고 일일이 모든 명령을 cpu로부터 받는다. weight에 대한 zero skipping과 같은 기능들이 제한적으로 가능하긴 하지만 어디까지나 cpu의 판단에 의해 이뤄질뿐이다.
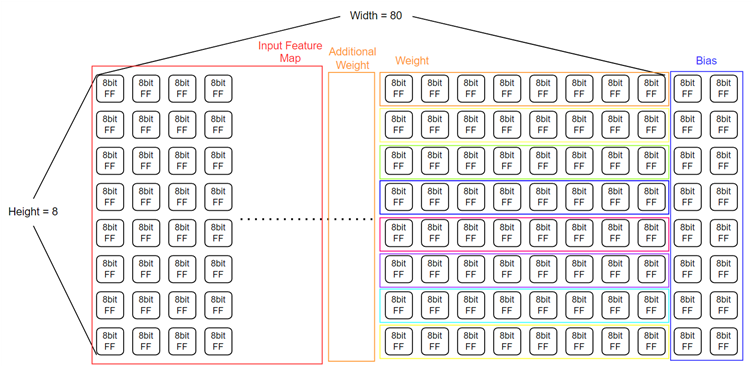
memory part는 Flip Flop이 2차원으로 배열된 구조이다. memory 파트도 사실 매우 간단해서 설명할게 별로 없다.
Bias와 weight가 저장되는 공간은 지정되어 있고 이 둘이 차지하고 남은 공간에 input feature map이 저장되는 구조이다. 이를 통해 여러 크기의 filter에 대해서도 효율적으로 memory를 이용할 수 있게 하였다.
이쯤되면 아마 이렇게 간단한 2개를 설계하는데 왜 2달이나 걸렸나 궁금할텐데 그 이유는 npu를 구동시킬 testbench 파일(run_npu_simple.v)을 작성하는데 시간이 오래걸렸기 때문이다.
실제 cnn의 모델에서 파라미터와 input을 받아들여 가속기를 구동시키는, 즉 본래 cpu가 수행하는 일들은 시뮬레이션에서 testbench를 통해 수행하는데 이걸 작성하는데 시간이 꽤 오래걸렸다.
여러가지 input과 filter에 대해서도 구동할 수 있게하다보니 작성 중 조금 헷갈렸지만 그래도 일단 2차원 input인 경우 크기 관계 없이 3*3, 4*4 필터에 대해 작동할 수 있다.
사실 솔직히 말하자면... 이 testbench는 어디까지나 설계한 npu를 이용해 cnn을 가속할 수 있다는걸 보여줄뿐이지 실제 모델에 적용하려면 내용을 여기서 많이 추가해야한다.
하지만 그렇게 했다간 본 모듈도 아닌 testbench를 작성하는데 시간을 너무 많이 쓸거같아서 그냥 간단한 cnn 모델만 구동할 수 있는 정도로만 작성했다.
작성한 testbench 파일에서 핵심은 결국 memory part를 어떻게 이용하냐인데 그에 대한 설명은 깃허브의 readme에 설명되어있다. 다만 어디까지나 이건 내가 생각한 이용법이고 testbench를 어떻게 작성하냐에 따라 달라지기에 다른 효율적인 방법이 있을 수 있다.
혹시 생각났다면 이를 내게 알려주길 바란다. 큰 도움이 될 것이다.
일단 simple 버전을 완성하긴 했지만 사실 개선해야할 사항이 한두개가 아니다. 이걸 생각날때마다 적용하는건 비효율적이라 생각해 먼저 메모해두었다가 이전 목표를 완수한 다음 정리해 다음 버전에 적용하는 방식으로 하기로 했다.
일단 다음 마이너 버전에서 적용할 예정인 개선 사항들은 다음과 같다.
- set_bound와 flip flop의 위치 바꿔서 정확도 올리기 (완료)
- adder단계에서 truncation 되는 하위 비트들의 연산 부분 최적화
- memory part의 write 방식을 더 경직적이게 만들어서 area 최적화
그 외에도 여러가지가 있지만 당장 해결이 어려울 것 같아 우선 다음 버전에서 적용할 것을 목표로 하는 것들을 이상이다.
