내 생각에 하드웨어 디자인에서 오류가 나는 대부분의 경우는 timing 문제인 것 같다. 내가 아직 간단한 모듈들만을 디자인해봐서 그런걸지도 모르지만 개개의 세부 부분들이 기능적으로 잘못 작동하는 경우는 거의 없었고 있더라도 수정하기 쉬웠다. 자꾸 오류가 나서 디버깅을 할 의욕을 잃게 하는 대부분의 문제는 timing 문제였다.
이번에 깨달은 점은 실제 코드 작성에 들어가기전에 timing 그래프 등을 그려가며 아키텍처를 미리 상세하게 설계하는 것이 매우 중요하다는 것이었다.
사실 나는 무언가를 하기전에 상세하게 계획을 짜는 것을 그다지 좋아하지 않는다. 그래서 하드웨어 설계를 할 때도 전반적인 구조만 구상했을뿐 세부 모듈들의 구조까지 사전에 미리 상세하게 설계하고 코드작성에 들어가지는 않았다.
문제가 생기면 그때 고치면 되지하는 생각으로 그동안 해왔었다. 그런데 이번에 복습겸, 포스팅겸 미리 아키텍처와 timing 그래프를 비교적 상세하게 그리고 작업하면서 느낀게 이 과정을 제대로 수행하면 코드 작성과 디버깅이 매우 편해진다는 점이다.
미리미리 아키텍처를 상세하게 그려두면 코드 작성은 그냥 그거 보고 하면 된다. 그리고 그렇게 코드 작성의 구조가 상세하게 잡혀있으니 작성에 있어서 즉흥적인 부분이 줄고(여전히 꽤 있기는 하다.) 체계가 잡힌다. 그러니 당연히 오류가 나는 부분도 적어지고 디버깅 시간이 줄어든다. 특히 timing 문제에서 말이다.
counter & multiple clk adder
reg [2:0] p_step;
reg mux_f_s;
//reg out_en_b;
output reg out_en;
/// counter
always @(posedge clk) begin
if(reset == 0) begin
p_step <= 3'b000;
mux_f_s <= 1'b0;
out_en <= 1'b0;
end
else if (en_d == 1) begin
if (p_step == step_d) begin
p_step <= 3'b000;
out_en <= 1'b1;
mux_f_s <= 1'b0;
end
else begin
p_step <= p_step +1;
out_en <= 1'b0;
mux_f_s <= 1'b1;
end
end
else begin
mux_f_s <= 0;
out_en <= 1'b0;
end
end
//adder
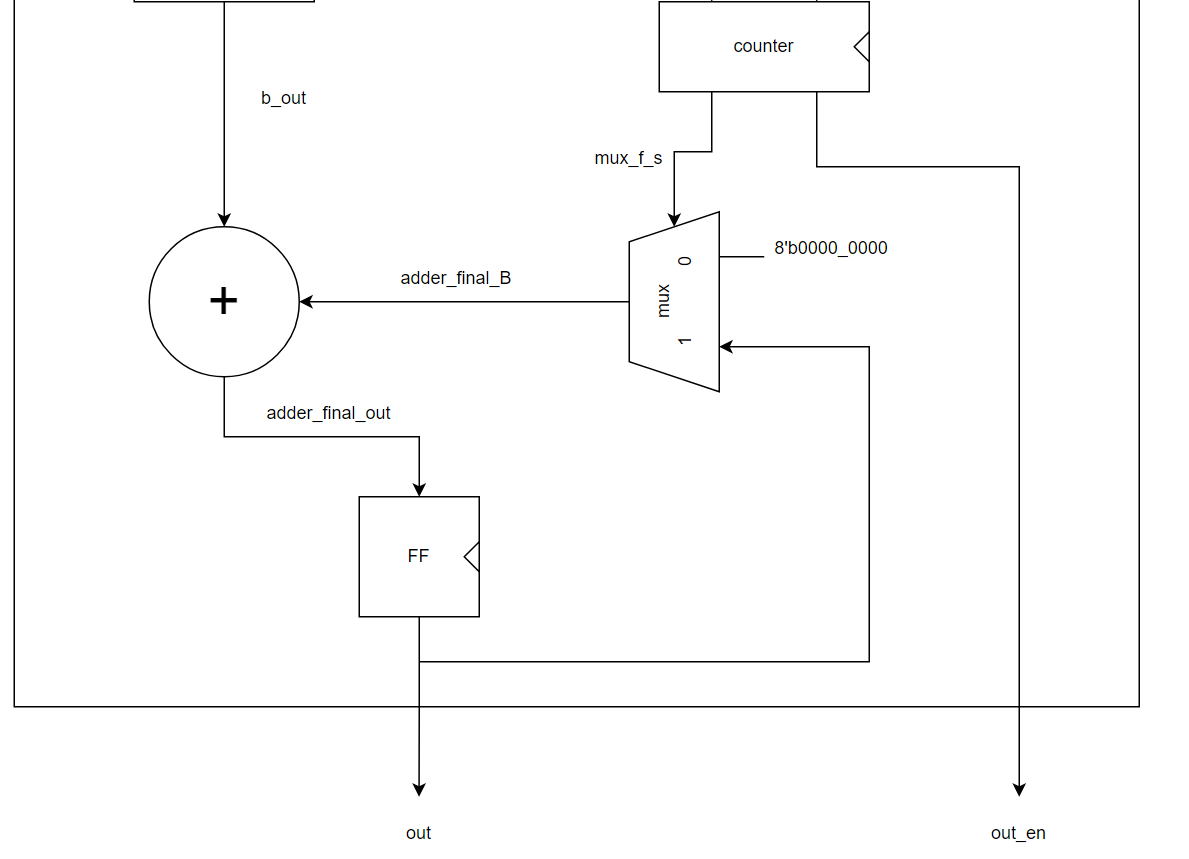
wire signed [outport-1:0] adder_final_B, adder_final_out;
assign adder_final_B = mux_f_s ? out : 8'b0000_0000;
A_8_f A_final(b_out, adder_final_B, adder_final_out);
///clk+2
D_FF8 F1 (adder_final_out, out, clk, reset);
//D_FF1 F2 (out_en_b, out_en, clk, reset);counter와 multiple clk adder는 서로 긴밀하게 연계되어있기 때문에 한번에 설명하고자 한다.
두 부분은 간단하지만 내가 설계하고자하는 범용적인 npu(cnn accelerator)에서 핵심적인 기능을 담당하기에 좀 더 상세하게 설명하고자 한다.
결국 해당 부분은 input에 맞게 이전의 output을 더 할지 말지, out_en을 내보낼지 말지를 결정한다.
counter는 en의 입력과 현재상태에 따라 이 둘을 결정하는데 말로 설명하기보다는 이해하기 쉽게 timing 그래프로 설명하자
step = 0인 경우

step = 0인 경우, 즉 계산하는데 1clk만 쓰는 경우이다.
en_d와 함께 adder tree의 output인 b_out에 유효한 값이 출력되고 그 다음 posedge clk에서 counter가 en_d = 1을 인식하고 step == p_step 이므로 mux_f_s = 0과 out_en = 1을 출력한다.
mux_f_s는 최초 0이었고 계속해서 step == p_step이므로 그 이후로도 0이고 그에따라 adder_final_B 역시 계속 8'b0000_0000이 되어 입력되었던 b_out은 adder에서 +0이 되어 그대로 나와 FF을 거쳐 out_en = 1과 같은 clk에 출력된다.
step = 1인 경우
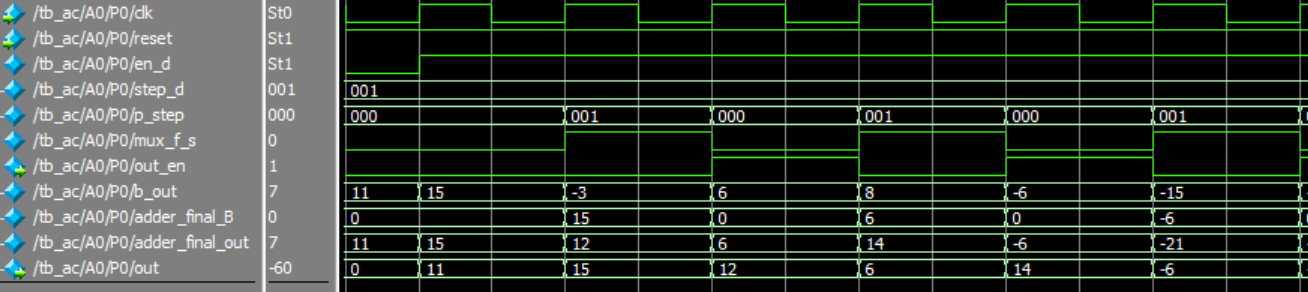
step이 1인 경우 계산하는데 2clk이 필요하므로 out_en이 0, 1을 번갈아 출력해야한다. 정확히 말하면 step 값마다 출력해야한다.
헷갈릴 수 있으므로 clk0, clk1등으로 clk을 구분해서 설명하겠다.
clk0
- en_d=1이 된다.
- mux_f_s = 0 이므로 adder_final_B = 0 이다. 그러므로 들어온 b_out은 adder_final_out으로 그대로 출력된다.
clk1
- clk0의 adder_final_out이 out으로 출력된다.
- counter가 en_d = 1을 인식한다. p_step = 0으로 step = 1과 다르므로 현재 p_step에 1을 더하고 mux_f_s = 1, out_en = 0을 출력한다.
- mux_f_s = 1이므로 adder_final_B로 out, 즉 이전 clk의 adder_final_out이 출력된다.
- adder에서 b_out과 adder_final_B가 더해져 adder_final_out으로 출력된다. 이 값은 결국 clk0과 clk1의 b_out의 합이다.
clk2
- clk1의 adder_final_out이 out으로 출력된다.
- counter가 en_d = 1을 인식한다. p_step = step = 1이므로 현재 p_step = 0으로 하고 mux_f_s = 0, out_en = 1을 출력한다.
- 결과적으로 유효한 값이 out으로 출력될 때 out_en도 1로 출력된다.
보기 좋게 쓰지는 않았지만 당연히 clk2에서도 mux_f_s = 0 이므로 adder_fibal_B = 0 이고 들어온 b_out은 adder_final_out으로 그대로 출력된다.
이 과정에 따라 precessing_element는 여러 clk의 값들을 더한 후 out_en을 적절하게 출력해 유효한 값임을 나타낸다.
결과적으로 9개를 초과하는 weight를 가지는 필터도 여러 clk을 계산해 컨볼루션을 수행한다.
weight가 그 이상인 경우도 계산하는데 clk2에서 일어나는 일이 미뤄지고 clk1에서 일어나는 일이 그대로 여러번 일어나게 될 뿐 구조자체는 똑같다. 그래도 이해를 위해 step = 3, 즉 계산하는데 4clk이 필요한 경우의 timing도 첨부하겠다.
step = 3

단 이 구조의 경우 한가지 문제가 있는데 multiple clk adder를 수행하는데 en이 끊길 경우 문제가 발생할 수 있다는 것이다.
정확하게 말하면 한번의 계산들의 사이사이, 예를 들어서 한번 계산하는데 3clk이 걸린다고 할때 en이 1-1-1 - 0-0-0 - 1-1-1 -0- 1-1-1 이런식으로 들어오는 것은 문제가 되지 않는다.
하지만 1-0-1-1 -0- 1-1-0-1 - 1-0-0-0-1-1 이런 식으로 1번의 계산이 다 끝나지 않았는데 en이 0 으로 들어오는 경우는 문제가 발생한다.
보다 상세하게 설명하면 weight의 개수가 27개인 필터를 계산할 때 27개의 input과 27개의 weight과 연달아 제대로 들어오지 않고 모종의 이유로 인해 9개만 들어오고 대기했다 다시 들어오고 하는 경우 문제가 발생할 수 있다는 것이다.
사실 이는 mux를 하나 추가하면 간단하게 해결할 수 있다. 하지만 내가 생각하기에 중간중간에 en이 끊기는 것, 즉 유효한 input이 끊기는 경우는 아마 dram으로부터 불러오는 과정 중의 지연시간등으로 인해 인한 것일텐데
그것이 고작 1개 분량의 input feature map, 위의 경우 27*8 bit 분량을 다 불러와놓지 못해 발생하지는 않을 것 같다. 여러 분량의 input feature map을 한번에 캐시에 담는거야 불가능하지만 애초에 이 각각 사이에는 대기시간이 있어도 문제없이 작동한다.
그래서 면적을 줄이기위해서 일단 빼두기는 했는데 그래도 혹시 모르니 마지막 FF전에 mux를 추가한 버전도 깃허브에 올려두겠다. 이름은 Processing_element_mod.v 이다

하드웨어 디자인에 있어서 timing 문제가 주요한 오류 원인이라는 점에 공감합니다. 상세한 설계 단계에서부터 이를 고려하는 것이 중요하다는 깨달음이 인상적이네요. 특히, 본문에서 언급한 설계 방식이 디버깅을 용이하게 하고, 디자인 프로세스를 체계적으로 만드는 데 큰 도움이 된다는 점이 흥미롭습니다. 하드웨어 설계의 세계에 접해본 적이 없는 저로서는 새로운 지식을 얻을 수 있는 좋은 글이었습니다. 계속해서 좋은 글 부탁드립니다!