랜덤 포레스트 Random Forest
의사결정 나무의 과적합 취약성과 불안정성을 보완하기 위한 아이디어로, 트리 여러 개를 결합하여 숲(forest)를 만드는 것.
배깅 Bagging
머신러닝의 데이터 부족 문제를 해결하기 위한 Bootstrapping + Aggregating 방법론
- Bootstrapping: 데이터를 복원 추출하여 유사하지만 다른 데이터셋을 생성하는 것
- Aggregating: 데이터의 예측, 분류 결과를 합치는 것
- Emsenble: 여러 개의 모델을 만들어 결과를 합치는 것
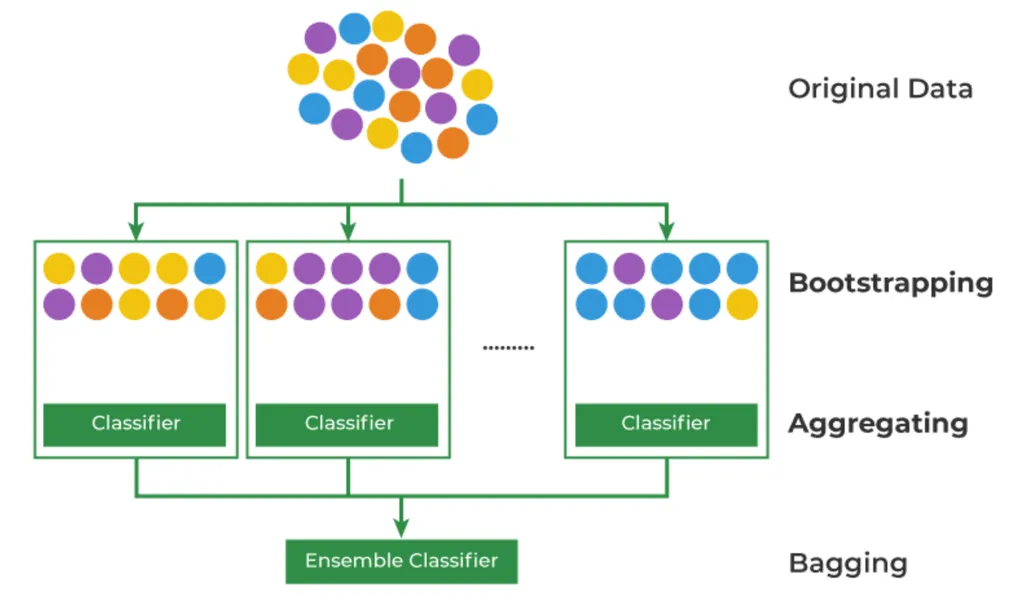
- 이렇게 생성한 데이터 샘플들은 모집단의 분포를 유사하게 따라가므로, 다양성을 보장하면서 데이터의 부족한 이슈를 해결
Tree로 Forest 만들기
- 여러 가지 데이터 샘플에서 각자 의사결정 트리를 만든다.
- 각각의 트리에서 도출된 결과들을 합하여 다수결의 원칙에 따라 결론을 내린다.
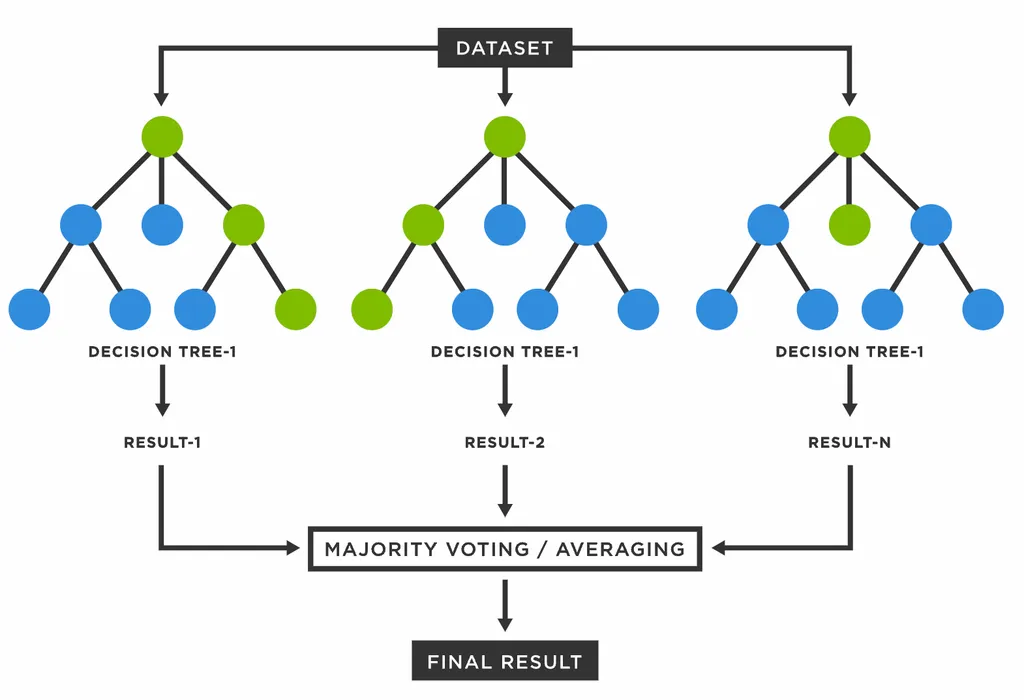
- 의사결정 나무의 장점은 수용하고 단점은 보완했기 때문에, 랜덤 포레스트는 일반적으로 굉장히 뛰어난 성능을 보여 현재까지도 자주 쓰이는 알고리즘이다.
장점
- Bagging을 통해 과적합을 피할 수 있음
- 이상치에 견고하며 데이터 스케일링 불필요
- 변수 중요도를 추출하여 모델 해석에 중요한 특징 파악 가능
단점
- 컴퓨터 리소스 비용이 크다
- 앙상블 적용으로 해석이 어렵다
실습
sklearn.ensemble.RandomForestClassifiersklearn.ensemble.RandomForestRegressor
# 로지스틱회귀, 의사결정나무, 랜덤포레스트
from sklearn.linear_model import LogisticRegression
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score,f1_score
model_lor = LogisticRegression()
model_dt = DecisionTreeClassifier(random_state=42)
model_rf = RandomForestClassifier(random_state=42)
model_lor.fit(X,y)
model_dt.fit(X,y)
model_rf.fit(X,y)
y_lor_pred = model_lor.predict(X)
y_dt_pred = model_dt.predict(X)
y_rf_pred = model_rf.predict(X)
def get_score(model_name, y_true, y_pred):
acc = round(accuracy_score(y_true, y_pred), 3)
f1 = round(f1_score(y_true,y_pred), 3)
print(model_name, 'acc 스코어는: ',acc, 'f1_score는: ', f1)
get_score('lor',y,y_lor_pred)
get_score('dt',y,y_dt_pred)
get_score('rf',y,y_rf_pred)
# lor acc 스코어는: 0.8 f1_score는: 0.732
# dt acc 스코어는: 0.88 f1_score는: 0.833
# rf acc 스코어는: 0.88 f1_score는: 0.836+) Feature Importance 확인하기
X_features
# ['Pclass', 'Sex', 'Age']
model_rf.feature_importances_
# array([0.17077185, 0.40583981, 0.42338834])
To Dare is To Do