부스팅 알고리즘
여러 개의 약한 학습기(weak learner)를 순차적으로 학습시키면서 잘못 예측한 데이터에 가중치를 부여하여 오류를 개선해 나가는 학습 방식
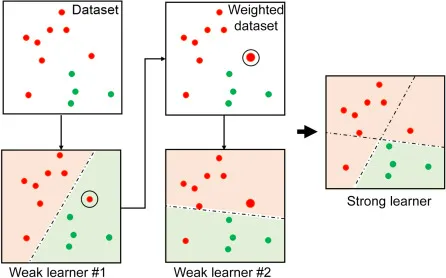
Gradient Boosting Model
- 가중치 업데이터를 경사 하강법을 통해 진행
sklearn.ensemble.GradientBoostingClassifiersklearn.ensemble.GradientBoostingRegressor
XGBoost
- 트리 기반 앙상블 기법. 가장 각광받으며, 캐글 상위 알고리즘
- 병렬 학습이 가능해 속도가 빠름
xgboost.XGBRegressorxgboost.XGBRegressor
LightGBM
- XGBoost와 함께 가장 각광받는 알고리즘
- XGBoost보다 학습 시간이 짧고 메모리 사용량이 작음
- 작은 데이터(10,000건 이하)의 경우 과적합 발생
lightgbm.LGBMClassifierlightgbm.LGBMRegressor
실습
- 이전 실습과의 다른 점: 더 높은 성능을 위해
Fare,Embarked데이터도 추가로 사용
라이브러리 임포트
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.preprocessing import LabelEncoder
from sklearn.tree import DecisionTreeClassifier, plot_tree
from sklearn.linear_model import LogisticRegression
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score,f1_score
from sklearn.neighbors import KNeighborsClassifier
from sklearn.ensemble import GradientBoostingClassifier
from xgboost import XGBClassifier
from lightgbm import LGBMClassifier전처리
X_features = ['Pclass','Sex','Age','Fare','Embarked']
# Pclass: LabelEncoder
# Sex: LabelEncoder
# Age: 결측치-> 평균으로 대치하고
le = LabelEncoder()
titaninc_df['Sex'] = le.fit_transform(titaninc_df['Sex'])
le2 = LabelEncoder()
titaninc_df['Pclass'] = le2.fit_transform(titaninc_df['Pclass'])
age_mean = titaninc_df['Age'].mean()
titaninc_df['Age'] = titaninc_df['Age'].fillna(age_mean)
le3 = LabelEncoder()
titaninc_df['Embarked'] = titaninc_df['Embarked'].fillna('S')
titaninc_df['Embarked'] = le3.fit_transform(titaninc_df['Embarked'])
# 예측에 사용할 데이터
X = titaninc_df[X_features]
y = titaninc_df['Survived']모델 불러와서 학습시키기
# 모델 불러오기
model_lor = LogisticRegression()
model_dt = DecisionTreeClassifier(random_state=42)
model_rf = RandomForestClassifier(random_state=42)
model_knn = KNeighborsClassifier()
model_gbm = GradientBoostingClassifier(random_state= 42)
model_xgb = XGBClassifier(random_state= 42)
model_lgb = LGBMClassifier(random_state= 42)
# 학습시키기
model_lor.fit(X,y)
model_dt.fit(X,y)
model_rf.fit(X,y)
model_knn.fit(X,y)
model_gbm.fit(X,y)
model_xgb.fit(X,y)
model_lgb.fit(X,y)
# 예측값 얻기
y_lor_pred = model_lor.predict(X)
y_dt_pred = model_dt.predict(X)
y_rf_pred = model_rf.predict(X)
y_knn_pred = model_knn.predict(X)
y_gbm_pred = model_gbm.predict(X)
y_xgb_pred = model_xgb.predict(X)
y_lgb_pred = model_lgb.predict(X)평가하기
평가 결과 출력 함수 만들기
def get_score(model_name, y_true, y_pred):
acc = round(accuracy_score(y_true, y_pred), 3)
f1 = round(f1_score(y_true,y_pred), 3)
print(model_name, 'acc 스코어는: ', acc, 'f1_score는: ', f1)평가 결과 출력
get_score('lor',y,y_lor_pred)
get_score('dt ',y,y_dt_pred)
get_score('rf ',y,y_rf_pred)
get_score('knn',y,y_knn_pred)
get_score('gbm ',y,y_gbm_pred)
get_score('xgb ',y,y_xgb_pred)
get_score('lgb ',y,y_lgb_pred)결과
lor acc 스코어는: 0.79 f1_score는: 0.723
dt acc 스코어는: 0.98 f1_score는: 0.973
rf acc 스코어는: 0.98 f1_score는: 0.973
knn acc 스코어는: 0.808 f1_score는: 0.731
gbm acc 스코어는: 0.889 f1_score는: 0.845
xgb acc 스코어는: 0.962 f1_score는: 0.949
lgb acc 스코어는: 0.945 f1_score는: 0.927

To Dare is To Do