데이터셋 확인
기본 라이브러리 임포트
import pandas as pd
import numpy as np
import scipy.stats as stats
from datetime import datetime, timedelta데이터셋 임포트
df = pd.read_csv('/Users/hye/Desktop/내배캠/ML_과제/statistics.csv')
컬럼명 확인
df.columns
# 결과:
Index(['Customer ID', 'Age', 'Gender', 'Item Purchased', 'Category',
'Purchase Amount (USD)', 'Location', 'Size', 'Color', 'Season',
'Review Rating', 'Subscription Status', 'Shipping Type',
'Discount Applied', 'Promo Code Used', 'Previous Purchases',
'Payment Method', 'Frequency of Purchases', 'Discount Applied encoded',
'Subscription Status encoded'],
dtype='object')결측치 확인
df.isnull().sum()
- 결측치 없음
컬럼별 통계 살펴보기
df.describe(include = 'all')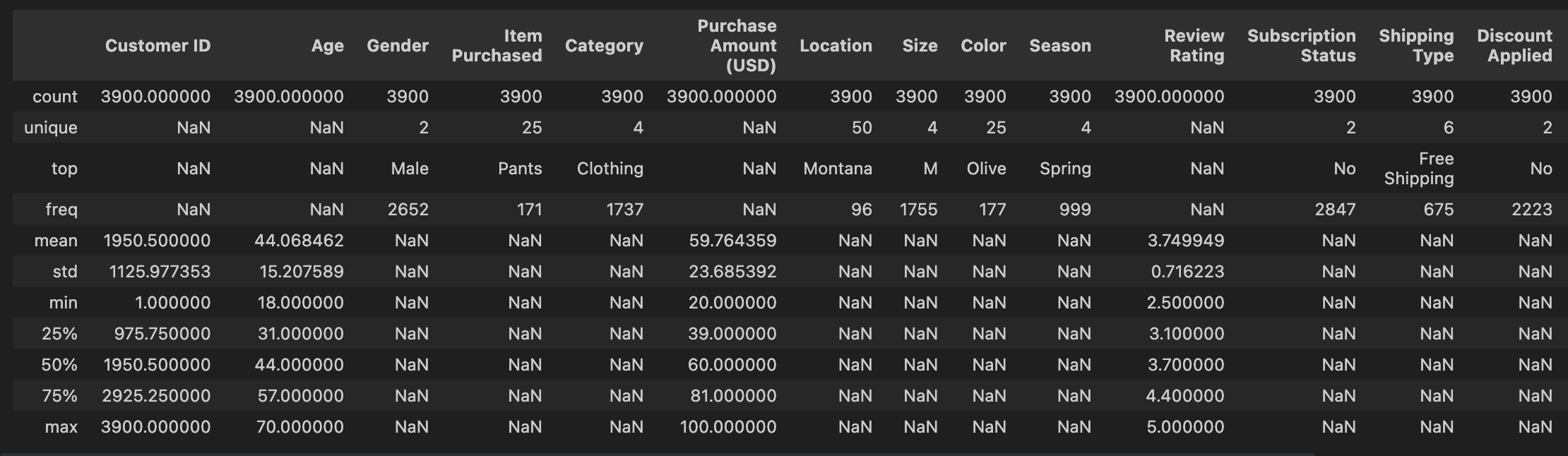
문제 1. 기초 통계
- statistics csv 파일을 읽고, 성별 Review Rating 에 대한 평균과 중앙값을 동시에 구해주세요. 결과는 소수점 둘째자리까지 표현해주세요.
- 그리고 이에 대한 해석을 간략하게 설명해주세요.
- 결과 제출형태
- 코드와 결과값
- 해석
풀이
gender_review = df[['Gender', 'Review Rating']].groupby('Gender').agg(['mean', 'median'])
gender_review = gender_review.apply(lambda x: round(x, 2))
display(gender_review)
print('여성의 평균: 3.74점, 중앙값: 3.7점')
print('남성의 평균: 3.75점, 중앙값: 3.8점')
print('해석: 남성의 Review Rating의 평균 및 중앙값이 여성보다 약간 높다.')결과:

문제 2. 통계적 가설검정
- 성별, Review Rating 컬럼에 대한 T-TEST 를 진행해주세요.
- 해당 데이터셋의 컬럼들은 정규성을 만족한다고 가정하겠습니다.
- 귀무가설과 대립가설을 작성해주세요.
- t-score, P-value 를 구해주세요.
- 그리고 이에 대한 귀무가설 채택/기각 여부와 그렇게 생각한 이유를 간략하게 설명해주세요.
- 결과 제출형태
- 귀무가설, 대립가설
- 코드와 결과값
- 해석(채택여부 및 이유)
풀이
from scipy.stats import ttest_ind
print('귀무가설: 여성의 Review Rating과 남성의 Review Rating에는 차이가 없다.')
print('대립가설: 여성의 Review Rating과 남성의 Review Rating에는 차이가 있다.')
male_cond = df['Gender'] == 'Male' # 2652명
female_cond = df['Gender'] == 'Female' # 1248명
male_review = df.loc[male_cond, 'Review Rating']
female_review = df.loc[female_cond, 'Review Rating']
# 등분산 검정
from scipy.stats import levene
# 귀무가설: 여성의 Review Rating의 분산과 남성의 Review Rating의 분산은 같다(등분산이다).
# 대립가설: 여성의 Review Rating의 분산과 남성의 Review Rating의 분산은 다르다(등분산이 아니다).
var_statistic, var_p_value = levene(female_review, male_review)
print(f'등분산 검정의 p-value: {var_p_value.round(3)}\n따라서 두 데이터는 등분산이다.') # 0.648
# p-value > 0.05 이므로 귀무가설이 채택되어 두 데이터는 등분산이다.
# 독립표본 t-test
t_stat, p_value = ttest_ind(female_review, male_review, equal_var=True)
print(f'독립표본 t 검정 통계량: {t_stat}\np-value: {p_value.round(3)}') # 0.61
print('해석: p-value가 0.05보다 크기 때문에 귀무가설이 채택되어 여성과 남성의 Review Rating에는 차이가 없다.')결과:

문제 3. 통계적 가설검정 2
- Color, Season 컬럼에 대한 카이제곱 검정을 진행해주세요.
- 귀무가설과 대립가설을 작성해주세요.
- 두 범주형 자료의 빈도표를 만들어주세요. 이를 코드로 작성하여 기재해주세요.
- 카이제곱통계량, P-value 를 구해주세요.
- 그리고 이에 대한 귀무가설 채택/기각 여부와 그렇게 생각한 이유를 간략하게 설명해주세요.
- 결과 제출형태
- 귀무가설, 대립가설
- 코드와 결과값
- 해석(채택여부 및 이유)
풀이
# 빈도표 만들기
pivot = df.pivot_table(index = 'Color',
columns = 'Season',
values = 'Customer ID',
aggfunc = 'count')
display(pivot)
# 카이제곱 검정 - 독립성 검정
print('귀무가설: Color과 Season은 독립적이다.')
print('대립가설: Color과 Season은 독립적이지 않다.')
chi2_stat, p_val, dof, expected = stats.chi2_contingency(pivot, correction=True)
print(f'chi2 : {chi2_stat.round(3)}, p-value : {p_val.round(3)}') # p-value = 0.719
print('해석: p-value가 0.05보다 크므로 귀무가설이 채택되어 Color과 Season은 서로 독립적이다.')결과:

문제 4. 머신러닝 1
- 아래와 같은 데이터가 있다고 가정하겠습니다.데이터를 바탕으로 선형 회귀 모델을 훈련시키고, 회귀식을 작성해주세요.
- 독립 변수(X): 광고예산 (단위: 만원)
- 종속 변수(Y): 일일 매출 (단위: 만원)
- X=[10, 20, 30, 40, 60, 100]
- Y=[50, 60, 70, 80, 90, 120]
- 회귀식을통해, 새로운 광고예산이 1,000만원일 경우의 매출을 예측(계산)해주세요. 그리고 이에 대한 해석을 간략하게 설명해주세요.
- 결과 제출형태
- 회귀식
- 코드와 결과값
- 해석
풀이
from sklearn.linear_model import LinearRegression
model_lr = LinearRegression()
ad_df = pd.DataFrame({'budget' : [10, 20, 30, 40, 60, 100],
'sales' : [50, 60, 70, 80, 90, 120]})
X = ad_df[['budget']]
Y = ad_df[['sales']]
model_lr.fit(X = X, y = Y)
coef = model_lr.coef_[0][0]
intercept = model_lr.intercept_[0]
new_pred = 1000 * coef + intercept
print(f'회귀식: y = {coef.round(3)}x + {intercept.round(3)}')
print(f'해석: 광고 예산이 1만원 늘어날 때, 일일 매출은 {coef.round(2)}만원, 즉 약 {int(coef.round(2) * 10000)}원 증가할 것으로 예측된다. 광고 예산이 없을 때에도 일일 매출은 {intercept.round(2)}만원일 것으로 예측된다.')
print(f'새로운 광고 예산이 1000만원일 경우의 예상 일일 매출: {new_pred.round(2)} 만원')
print(f'해석: 회귀식의 x 자리에 1000을 대입하면 {new_pred.round(2)}가 도출된다.')결과:

문제 5. 머신러닝 2
- Review Rating, Age, Previous Purchases 컬럼을 활용하여, 고객이 할인(Discount Applied)을 받을지 예측하는 RandomForest모델을 학습시켜 주세요. 그리고 모델 정확도를 계산해주세요.
- y(종속변수)는 Yes/No 로 기재된 이진형 데이터입니다. 따라서, 인코딩 작업이 필요합니다. 구현을 위해 LabelEncoder를 사용해주세요.
- 머신러닝시, 전체 데이터셋을 Train set과 Test set 으로 나눠주세요. 해당 문제에서는Test set비중을 30%로 설정해주세요. random_state는 42로 설정해주세요.
- Train Set: 모델을 학습하는데 사용하는 데이터셋
- Test Set: 적합된 모델의 성능을 평가하는데 사용하는 데이터셋
- RandomForestClassifier 를 활용하여 모델 학습을 진행해주세요. random_state는 42로 설정해주세요.
- 그리고 이에 대한 해석을 간략하게 설명해주세요.
- 결과 제출형태
- 코드와 결과값(정확도)
- 해석
풀이
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import LabelEncoder
from sklearn.metrics import accuracy_score
# 인코딩
le = LabelEncoder()
le.fit(df['Discount Applied'])
df['Discount Applied encoded'] = le.transform(df['Discount Applied'])
# 데이터셋 나누기
X_train, X_test, y_train, y_test = train_test_split(df[['Review Rating', 'Age', 'Previous Purchases']],
df['Discount Applied encoded'],
test_size = 0.3, shuffle= True,
random_state = 42,
stratify = df[['Discount Applied encoded']])
# 학습시키기
model_rf = RandomForestClassifier(random_state=42)
model_rf.fit(X_train, y_train)
# 학습 데이터 평가
y_train_pred = model_rf.predict(X_train)
print('train 정확도:', accuracy_score(y_train, y_train_pred).round(3))
# 테스트 데이터
rf_accuracy = model_rf.score(X_test, y_test)
y_test_pred = model_rf.predict(X_test)
print('test 정확도:', accuracy_score(y_test, y_test_pred).round(3))
print(f'Random Forest의 정확도: {rf_accuracy.round(3)}')
print(f'해석: 데이터셋의 70%로 학습시킨 랜덤 포레스트 모델은 나머지 30%의 테스트 데이터의 "Discount Applied" 중 {(rf_accuracy * 100).round(2)}%를 올바르게 예측하였다.')결과:

문제 6. 머신러닝 3
- Subscription Status 컬럼을 종속변수로 사용하여 고객의 이탈 여부를 예측하는 로지스틱 회귀 모델 학습을 진행해주세요. Age, Purchase Amount, Review Rating을 활용하여 모델을 훈련한 후, 연령 30세, 구매 금액 50 USD, 리뷰 평점 4.0인 고객의 이탈 확률을 계산해주세요.
- y(종속변수)는 Yes/No 로 기재된 이진형 데이터입니다. 따라서, 인코딩 작업이 필요합니다. 구현을 위해 LabelEncoder를 사용해주세요. 종속변수가 Yes 이면 0으로, No이면 1로 적용해주세요.
- 머신러닝시, 전체 데이터셋을 Train set과 Test set 으로 나눠주세요. 해당 문제에서는Test set비중을 30%로 설정해주세요. random_state는 42로 설정해주세요.
- Train Set: 모델을 학습하는데 사용하는 데이터셋
- Test Set: 적합된 모델의 성능을 평가하는데 사용하는 데이터셋
- 연령 30세, 구매 금액 50 USD, 리뷰 평점 4.0 인 고객을 new_customer 라는 변수에 지정해주세요. 1차원이 아닌 이중 대괄호
[[...]]로 지정해주세요. (모델 입력 형식은 2차원 배열이어야 하므로)- model.predict_proba 를 사용하여 이탈 확률을 구해주세요.
- predict_proba의 반환값: 로지스틱 회귀 모델의 예측 결과를 확률 값으로 제공해주며, 모델이 각 클래스에 속할 확률을 계산합니다. 결과는 다음과 같은 배열로 반환됩니다.
- [[P(클래스 0), P(클래스 1)]]
- 클래스 0: 원상태 유지
- 클래스 1: 원상태 변경
- 참고: 클래스는 0과 1로 이루어질 필요는 없지만, 이진 분류 문제에서는 관례적으로 0과 1을 사용합니다.
- P(클래스 0): 이 고객이 이탈하지 않을 확률.
- P(클래스 1): 이 고객이 이탈할 확률.
- 그리고 이에 대한 해석을 간략하게 설명해주세요.
- 결과 제출형태
- 코드와 결과값(이탈확률)
- 해석
풀이
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import LabelEncoder
# 인코딩
le2 = LabelEncoder()
le2.fit(df['Subscription Status'])
df['Subscription Status encoded'] = le2.transform(df['Subscription Status'])
df['Subscription Status encoded'] = df['Subscription Status encoded'].apply(lambda x: 0 if x == 1 else 1) # Yes: 0, No: 1
# 데이터셋 나누기
X_train, X_test, y_train, y_test = train_test_split(df[['Age', 'Purchase Amount (USD)', 'Review Rating']],
df['Subscription Status encoded'],
test_size = 0.3, shuffle= True,
random_state = 42,
stratify = df[['Subscription Status encoded']])
# 학습시키기
model_log = LogisticRegression()
model_log.fit(X_train, y_train)
# train 평가하기
y_train_pred = model_log.predict(X_train)
train_acc = accuracy_score(y_train, y_train_pred)
print(f'train 데이터 정확도: {train_acc.round(5)}')
# test data 평가하기
y_test_pred = model_log.predict(X_test)
test_acc = accuracy_score(y_test, y_test_pred)
print(f'test 데이터 정확도: {test_acc.round(5)}')
# 예측하기
new_customer = [[30, 50, 4.0]]
log_pred = model_log.predict_proba(new_customer)
no_churn = log_pred[0][0] # Subscription Status = 0(Yes) 일 확률. 이탈X
churn = log_pred[0][1] # Subscriptoin Status = 1(No) 일 확률. 이탈O.
print(log_pred)
print(f'{no_churn.round(3)}: 고객이 이탈하지 않을 확률입니다.\n{churn.round(3)}: 고객이 이탈할 확률입니다.')
print(f'구매금액이 50 USD이고 리뷰 평점이 4.0인 30세 고객이 이탈할 확률은 {(churn * 100).round(2)}%, 이탈하지 않을 확률은 {(no_churn * 100).round(2)}% 입니다.')결과:


To Dare is To Do