PPT: Pre-trained Prompt Tuning for Few-shot Learning 논문 리뷰를 통해
1) soft prompt에 해당하는 방법론을 간단히 정리하고,
2) 논문에서 제시한 prompt-tuning과, 연구 진행했던 'Clipcap' 모델의 아이디어인 prefix-tuning을 비교해보려고 한다.
1. Intro : What is Prompt-based Learning?
: Prompt-based learning이 무엇이며, 필요한 이유와, 대표적인 methods 비교
1-1. How to use Pre-train LM to Downstream task
언어모델을 downstream task에 활용하는 방법은 크게 두 가지 main stream으로 나누어볼 수 있다.
1) Task-oriented Fine-tuning
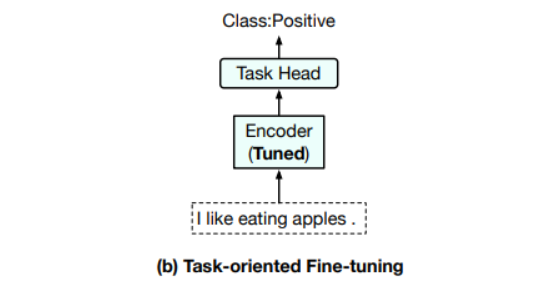
- 첫 번째는 task-oriented fine-tuning으로, PLM위에 task-specific head가 추가된 다음 해당 training data에서 task-specific 목표를 최적화하여 전체 모델을 fine-tuned한다.
- PLM에 task-specific head를 붙인 다음, downstream task에 맞는 data를 이용해서 PLM의 파라미터들과, Task Specific Head의 파라미터를 모두 업데이트한다. 그래서 이를 Full-model tuning이라고도 부른다.
- 단점 : downstream task 별 많은 양의 Labeled Data가 필요하다. 또한, task 별 PLM 파라미터+추가 파라미터를 필요로 한다. (많은 cost, parameters)
2) Using Prompt
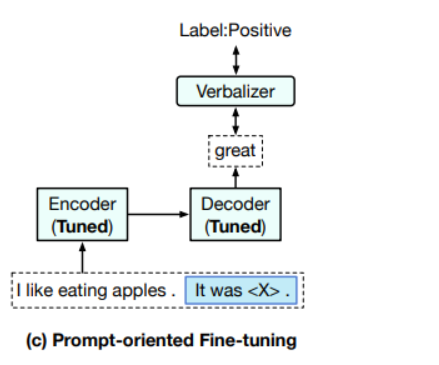
- 두 번째는 prompt-using method 이다.
- prompt를 사용한 경우, PLM에 추가 head를 붙이지 않고, 인풋에 변형을 주어 downstream task를 푼다.
- 위 그림과 같이 Prompt-oriented Fine-tuning을 수행할 경우,데이터 샘플은 prompt token을 포함하는 sequences로 변환되고, downstream tasks은 언어 모델링 문제로 형식을 갖춘다.
- "It was < X >" prompt를 문장에 추가하여, mask 위치에 "great" 또는 "terrible"를 예측하여 PLM으로 감정을 결정할 수 있다.
1-2. 언어 모델이 Fine-tuning을 하지 않고 task를 수행할 수 있는 이유
: "In context learning", 즉 Few-shot learning이 가능하기 때문이다.
예를 들어, GPT3의 text generation 과정에서는

다음과 같이 입력으로 task description, examples, prompt를 주면,
원하는 문장을 얻을 수 있다.
GPT는 Auto-regressive model로, 이전에 예측한 토큰들을 기반으로 다음 토큰을 예측하는 방식으로 학습을 진행한다. 또한 GPT3는 대량의 Unlabeled Corpus를 통해 pre-train 되었기 때문에, 이미 많은 지식을 담고 있다.
따라서 다음과 같이 예시와 prompt를 주었을 때, 추가적인 Fine-tuning 과정 없이 downstream task를 잘 수행할 수 있다.
즉, prompt를 이용하여 추가적인 파인튜닝 없이 PLM을 효율적으로 사용할 수 있다는 점이 In-Context Learning의 contribution이라고 볼 수 있다.
2. Fine-Tuning vs Prompt-Tuning
Prompt-Tuning은 두가지 이점이 있다.
- 첫 번째는 soft prompt는 hard prompt와 비교하여 end-to-end로 학습될 수 있다.
- 두 번째로, 대규모 PLM의 실용화를 위한 효율적이고 효과적인 paradigm으로, downstream data가 충분할 때 Fine-Tuning에 필적한다 .
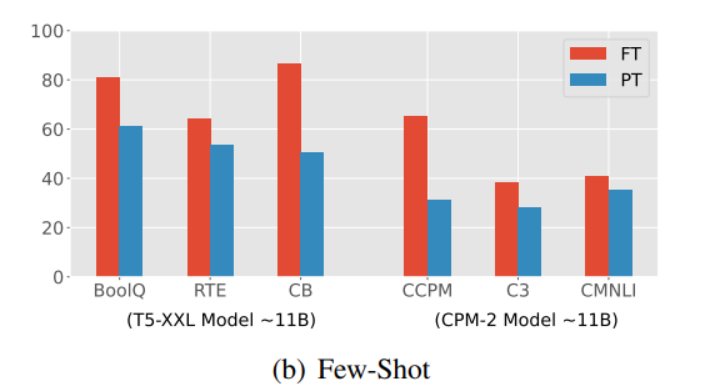
하지만, 위에서 볼 수 있득이, Prompt-Tuning (soft prompt) 단독으로는 few-shot setting에서 Fine-Tuning보다 훨씬 나쁜 성능을 보여, 다양한 low-resource scenarios에서 Prompt-Tuning의 적용을 방해할 수 있다는 것을 발견했다.
따라서, 본 논문에서는 soft prompt와 hard prompt를 결합한다.
3. Pre-trained Prompt Tuning (PPT)
MAIN IDEA
downstream task를 몇 가지 Group으로 묶은 후에, 각 그룹을 이용하여 prompt를 pre-train 한 다음, 이를 각 downstream task의 soft prompt의 초기값으로 사용하자!
Abstract
- pre-trained 언어 모델(PLM)에 대한 Prompt는 pre-training tasks와 다양한 downstream tasks간의 격차를 해소함으로써 놀라운 성능을 보여 주었다.
- 이러한 방법 중 PLM을 freeze하고 soft prompt만 tuning하는 prompt tuning은 대규모 PLM을 downstream task에 적응시키는 효율적이고 효과적인 솔루션을 제공.
- downstream data가 충분할 때 prompt tuning이 기존의 full-model tuning과 비슷한 성능을 보이지만, prompt tuning의 적용을 방해할 수 있는 few-shot learning 설정에서 훨씬 나빠졌다.
- 논문에서는 이 낮은 성능을 soft prompt를 초기화하는 방식 때문이라고 본다.
더 나은 초기화를 얻기 위해 pre-training 단계에 soft prompt를 추가하여 prompt를 pre-train할 것을 제안한다. (Pre-trained Prompt Tuning framework "PPT")
Related work
Prompt 사용 목적 : PLM이 가지고 있는 지식을 Prompt를 통해 효율적으로 활용하기 위함!
Prompt를 활용한 related works를 hard/soft prompt로 나누어서 확인해보자.
hard prompt vs soft prompt
hard prompt : 사람이 해석 가능한 토큰이 추가된 형태.
soft prompt : 사람이 해석 불가한 실수값, 연속적인 벡터값으로 이루어진 토큰이 추가된 형태.
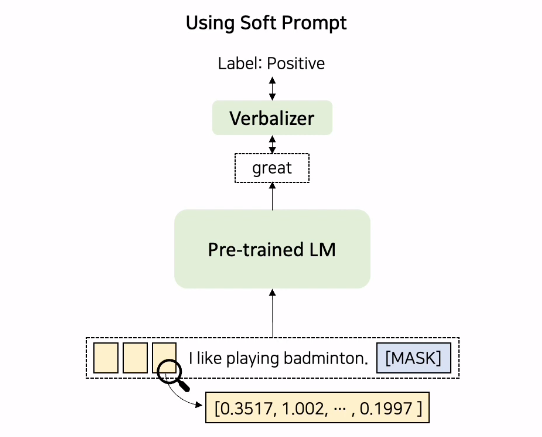
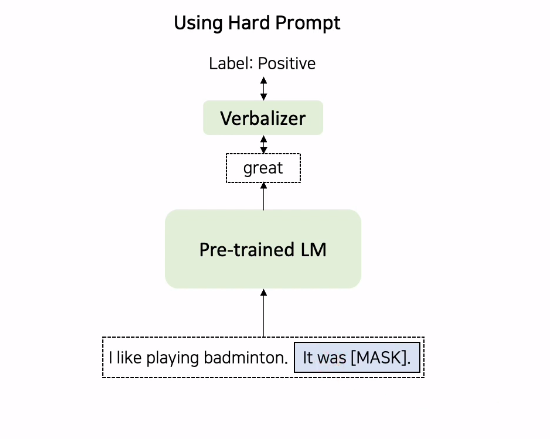
hard prompt ex) PET
Hard Prompt를 이용해서 Input을 MLM형식으로 변형한다.
이진 감성분류 task를 수행할 때, 위와 같이 positive로 labeled 된 data instance가 들어온다면, 이에 'It was __'라는 hard prompt를 추가하게 된다. 이 변형된 input을 PLM에 넣어서 masked token에 어떤 단어가 올 것인지 예측시킨다. PLM내의 vocab에서 이에 대한 logit값 반환하게 되는데, 이 중 great와 bad에 대한 logit 값만 softmax에 넣어서 확률값을 추출한다.
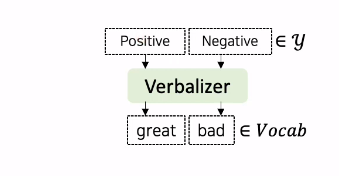
great와 bad에 대한 logit 값만 추출하는 이유?
위 그림과 같은 Verbalizer를 사용하기 때문이다. 기존의 y값으로 사용되는 logit값 0,1은 언어모델이 예측하기 힘들기 때문에 이 값들을 언어모델의 vocab 내의 특정 단어인 great, bad와 매핑해주는 작업이 필요하다.
great, bad 각각의 확률을 구한 다음, 원래 데이터셋의 class label인 Positive를 One-hot encoding하여 이 두 가지 벡터의 Cross Entropy Loss를 통해서 언어모델의 파라미터들을 업데이트 하는 것이다.
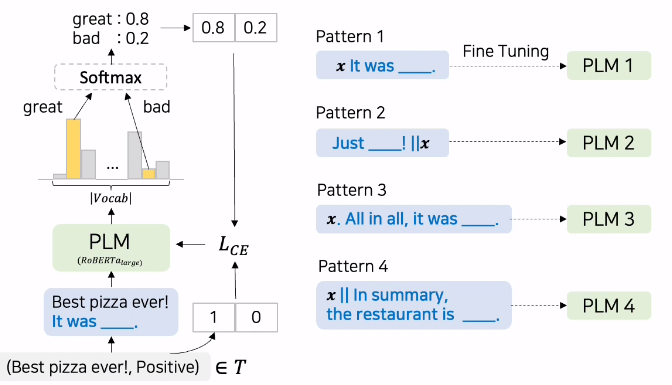
Labeled Training Set T에 PLM Ensemble을 통해 Unlabeled Dataset D에 soft labeling 한 후, Soft labeled dataset으로 Classifier 학습한다.
- 단점 1) Soft-labeled dataset을 만들기 위해 PLM을 Pattern의 개수만큼 Fine-tuning해야 함
- 단점 2) 최종 Classifier에는 PLM에 Task-Specific Head를 추가해 PLM과 Task-Specific Head의 파라미터를 모두 update 해야 함
- 단점 3) Hard prompt를 manual하게 만들어서 사용하기 때문에, 도메인지식이 필요하고 , 많은 Trial-and-Error를 수반한다.
무엇보다도, PET은 Full-Model Tuning을 사용하므로 PLM을 효율적으로 사용했다고 보기 어렵다.
Soft prompt 방법론 세 가지
1. Prefix-tuning
: 기존 Pre-trained LM의 파라미터는 고정시키고, Transformer layer 별로 Learnable Soft Prompt를 추가한다.
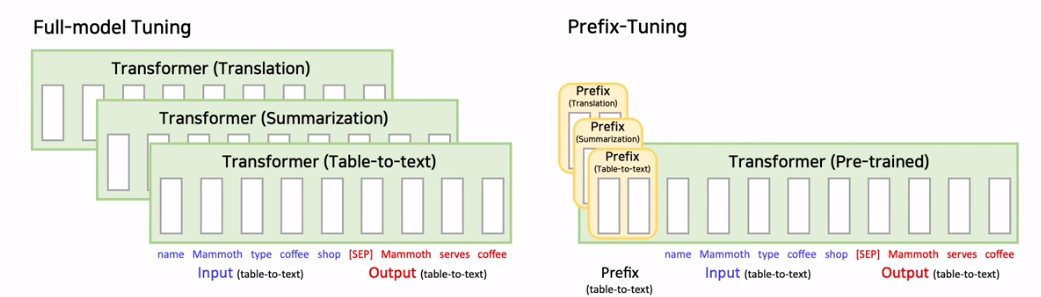
- Base Model : Text generation(GPT2, BART), Summarization(BART)
- 다운스트림 Task 적용 시, Full model tuning보다 parameter update 양이 매우 적다.
2. P-Tuning
: 기존 PLM 파라미터는 freeze하고, Soft Prompt인 hi만 업데이트(prompt encoder 추가)
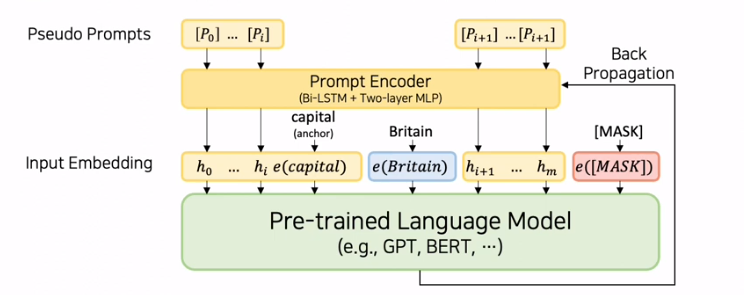
- prompt encoder를 통해 hard prompt에 해당하는 pseudo prompts를 soft prompt로 바꾸어준다.
- soft prompt들 사이에 anchor token을 넣어주어 함께 사용했을 시 성능이 올랐다.
- GPT 계열 모델은 NLU Task에 적합하지 않다는 고정관념을 P-tuning을 통해 극복!
3. Prompt Tuning (본 논문)
: 기존 PLM 파라미터는 freeze, Input text에 Learnable Soft Prompt 추가
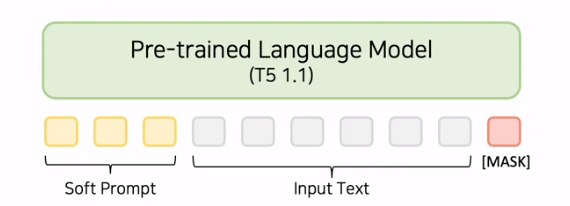
- Base model : T5 1.1
- Prompt Initialization : Classification task의 경우 Class label의 word embedding을 사용했을 시 가장 성능이 좋았다.
- Pre-train된 T5에 LM Objectives를 이용하여 추가 학습을 진행한다.
Prompt Tuning Overview
-
Few-shot learning에서 Prompt tuning의 성능을 높이기 위해 Soft Prompt를 pre-train 한다.
-
그 다음 Classification task들을 세 downstream task로 묶은 후, 각 그룹을 이용해 soft prompt를 pre-train 하고, 각 task의 soft prompt 초기값으로 사용한다.
위의 그림은 sentence pair tasks에서 사용되는 Prompt Tuning의 예시이다. P는 soft prompt를 나타낸다. -
본 논문에서는 다운스트림 Task 그룹을 세 개로 정의한다.
- Sentence Pair
- Multiple Choice
- Single Sentence Classification -
각 task 별 pre-train을 진행 한 다음, task format을 unifying한다.
이를 통해 pre-trained soft prompt를 임의의 도메인이나 훨씬 더 많은 label이 있는 Single-Text Classification Task에 사용이 가능하다.
Experiments
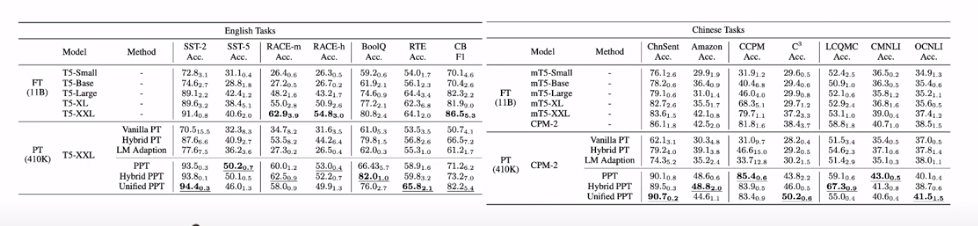
- pretrained-prompt tuning vs full-model tuning 결과
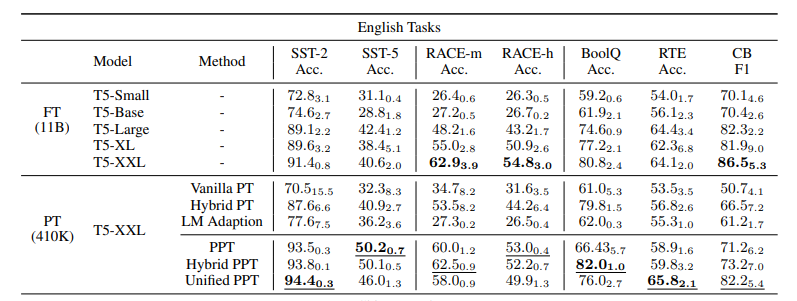
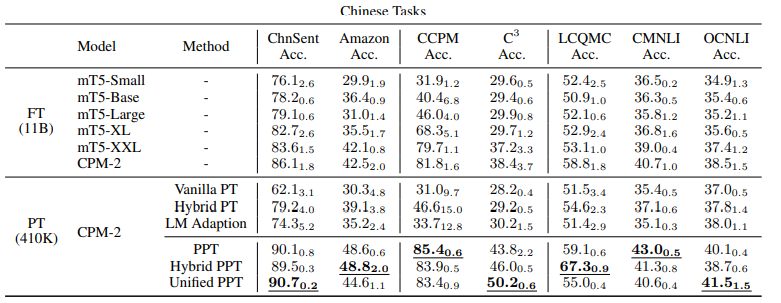
- Vanilla PT를 제외한 대부분의 경우 PPT가 full-model tuning 보다 나은 성능 보임.
- 또한 PPT는 Few-shot setting에서 낮은 variance를 보인다.
- full-model tuning 보다 훨씬 적은 파라미터로 준수한 성능을 보임
Prefix-tuning vs Prompt-tuning
- Prefix-tuning은 transformer layer마다 prefix를 추가한다. (구조를 약간 조작)
또한 MLP를 통해 Prefix-tuning을 진행하므로, training 파라미터 수가 증가할 수 밖에 없다.
- 이에 반해 Prompt tuning은 인풋 text 앞에 soft prompt를 추가하는 비교적 단순한 구조이다.
PLM을 구조적으로 조작하는 과정이 없어 효율적으로 PLM 사용 가능!
4. 결론 및 정리
-
PPT 논문에서는 pre-training 단계에 soft prompt를 추가하여 prompt를 pre-train 할 것을 제안
-
Few-shot learning에서 Prompt tuning의 성능을 높이기 위해 Soft Prompt를 pre-train
-
그 다음 Classification task들을 세 downstream task로 묶은 후, 각 그룹을 이용해 soft prompt를 pre-train 하고, 각 task의 soft prompt 초기값으로 사용하여 좋은 성능 달성
- NLP에서 Prompt를 사용한 방법 외에도, parameter를 효율적으로 학습시킬 수 있는 방법 --> LoRA, adapter 활용 methods..
