Prompt-based learning을 알아보다가, prompt-based learning의 한계점을 극복할 Parameter-Efficient Learning methods를 알아보았고, 그 중 LoRA라는 논문을 중점적으로 정리해보았다.
reference : https://lightning.ai/pages/community/article/understanding-llama-adapters/
Paper : LoRA: Low-Rank Adaptation of Large Language Models
Language Model Adaptation
Transformer를 기반으로 BERT와 GPT계열의 모델이 등장했고, 두 언어모델 모두 거대한 규모의 텍스트를 기반으로 학습한다. 일반적인 도메인의 데이터에 대해 거대한 규모로 사전학습을 진행한 후, 태스크 특화 데이터에 대해 파인튜닝을 진행하면 뛰어난 성능 향상을 보인다.
Adaptation Methods
1. Fine-Tuning
일반적인 도메인에 대해 사전학습한 모델을 특정한 태스크(downstream task)에 대해 재학습하는 방법으로, 모델의 모든 파라미터를 gradient updates 한다. 단순한 변형으로는 다른 Layer는 고정시키고 일부 layer에 대해서만 update시키기도 한다.
2. Prefix-embedding tuning
GPT-3가 오직 몇 개의 추가적인 학습예시를 갖고도 adaptation이 가능하다는 것이 보였으며, 결과는 input prompt에 크게 의존적이라는 사실이 밝혀졌다.
input token에 학습가능한 word embedding을 가진 특별한 token을 추가한다. 해당 토큰을 어느 위치에 놓을 것이냐가 성능에 영향을 미치는데, prompt의 앞쪽에 토큰을 붙인다면 Prefixing이라고 한다.
3. Adapter Tuning
트랜스포머 블록마다 2개의 adapter layer를 추가하거나, 블록 당 하나의 adapter layer와 LayerNorm을 추가하는 등의 방식
문제점 및 한계
Fine-Tuning의 한계
- 최근 거대한 하나의 사전학습 모델을 이용하여 여러 개의 downstream task를 수행하는 방법이 일반적이나, 기존의 finetuning은 기존 모델만큼 많은 수의 파라미터를 가지는 한계 존재 (not parameter efficient)
Adapter의 한계
- adapter가 적은 수의 파라미터를 가지고 있지만, 거대한 NN은 latency를 낮추기 위해 하드웨어 병렬화가 필요하고, adapter layer는 순차적으로 처리되어야 한다.
병렬화 없이 단일 GPU에서 inference가 수행될 시 adapter 사용했을 때 latency 증가
Prompt Tuning의 한계
- Prefix tuning은 최적화하기 어려우며, 학습가능한 파라미터들에 대해 비단조적으로(non-monotonically) 변화한다.
- adaptation을 위해 sequence length 일부를 사용하는 방식으로 downstream task를 위한 sequence length를 감소시켜 성능에 영향을 준다.
이러한 한계점을 극복하기 위해 LoRA를 제안한다.
LoRA (Low-Rank Adaptation)
- GPT-3 같은 거대한 모델을 fine-tuning하면 그 엄청난 parameter들을 다 재학습시켜야 함 → 이는 계산량도 많고 시간도 꽤 걸리는 부담스러운 작업이다.
- 이를 줄이기 위해 원래 parameter는 freeze시키고, Transformer architecture의 각 layer마다 학습가능한 rank decomposition matrices를 추가하는 방식을 도입하였다 (Low-Rank Adaptation).
- 결과적으로 메모리는 3배, 파라미터는 10,000배 정도 줄일 수 있었고
RoBERTA, DeBERTa, GPT-2, GPT-3같은 모델에서 비슷하거나 더 높은 fine-tuning 성능을 보였다.
Method
- 가정 : 가중치에 대한 update도 adaptation 중 intrinsic rank가 낮다고 가정 (기존의 over-parameter model이 intrinsic rank가 낮다고 주장하는 paper에서 영감을 받음)
- Pre-trained weight matrix W0에 대해 이 행렬에 대한 update를 low-rank decomposition을 통해 아래와 같이 표현
- Gradient의 변화량 ΔW을 BA로 approximate 하겠다는 것
- W0는 frozen (gradient update를 수행 X)
- r 차원으로 줄였다가, 원래의 output feature의 dimension인 d로 늘린다. 그리고 merge 해준다.
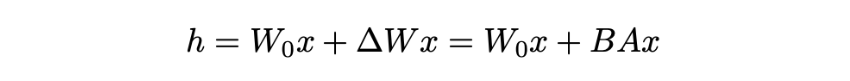
- 위 방법을 통해 Additional inference latency가 발생하지 않도록 함.
- Downstream task의 weight인 A, B 값을 더해줌으로서 merged weight가 fine-tuning된 weight가 되는 원리
- Inference 시에 그냥 이 layer를 통과시켜 주기만 하면 됨.
- Original weight 값으로 되돌리고 싶으면 위에서 merge한 weight를 그냥 빼주면 됨.
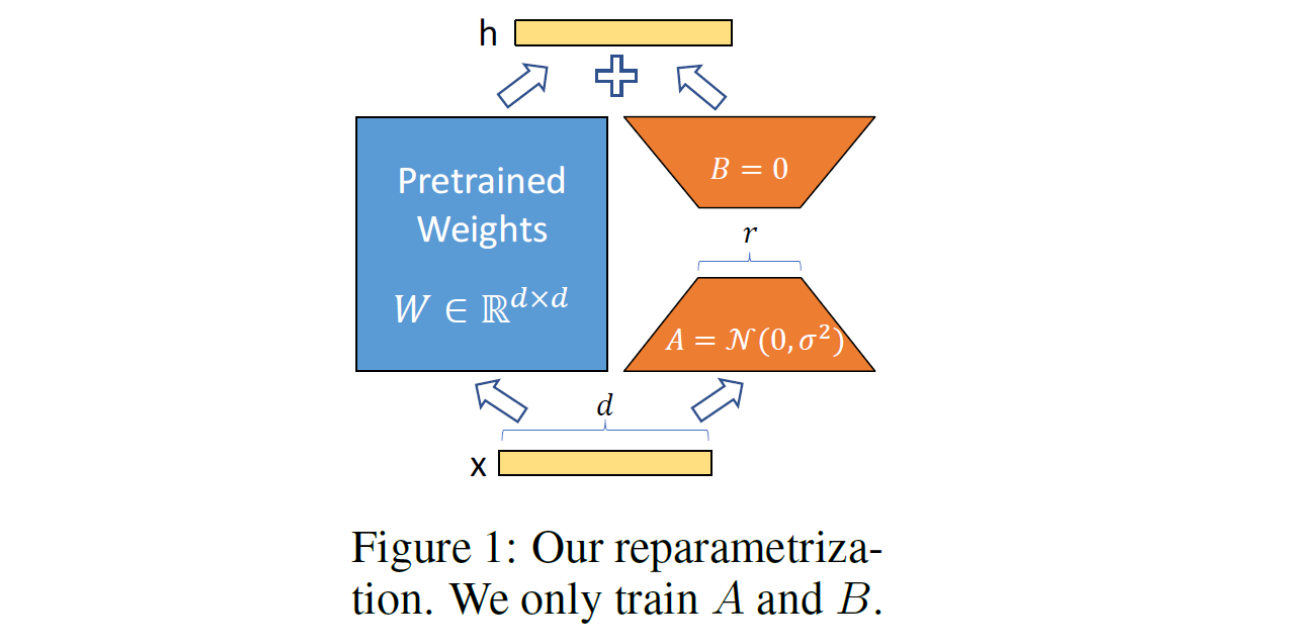
1. Low-Rank-Parametrized update matrices
학습시 low rank 행렬 A와 B를 업데이트하고, pretrained model의 initialized weight인 W0는 freeze 하고 gradient update를 하지 않는다.
2. Applying LoRA to Transformer
- 학습 가능한 매개변수의 수를 줄이기 위해 신경망에서 어떤 가중치 행렬의 부분집합에 적용이 가능할지 고민하다, 저자는 parameter-efficiency를 위해 downstream task에 대해서 attention weight만 adapting하고 MLP는 freeze한다.
Experiment
MLP는 행렬 곱 연산을 하는 많은 layer로 구성되어 있다. 이 layer들은 보통 full-rank인데, pre-trained LM의 경우 full-rank가 아닌 낮은 'instrisic dimension'을 가지고 있어 더 낮은 차원으로 project 할 수 있다고 한다. 논문 저자들은 이에 착안하여 MLP layer들도 domain adaptaion시 낮은 'instrisic dimension'을 가지고 있다고 가정하여 실험을 진행하였다.
- Models: RoBERTa, DeBERTa, GPT-2, GPT-3 175B
- Tasks: GLUE benchmark, WikiSQL, SAMSum, ...
어떤 가중치 행렬에 LoRA를 적용해야 하는가?
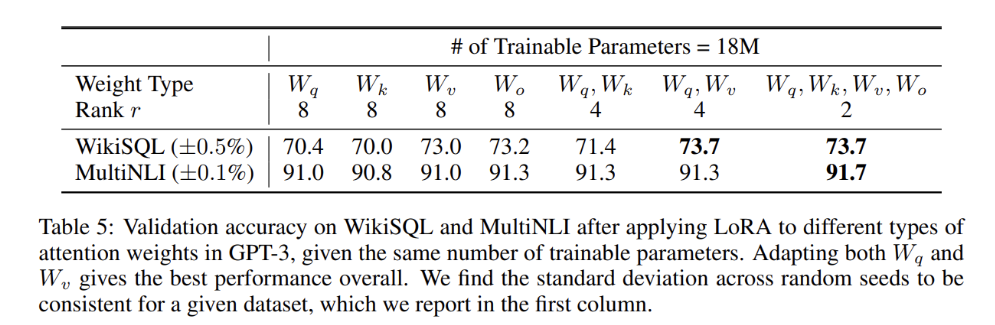
- 모든 파라미터에 적용하는 것 보다 W_q와 W_v에만 적용하는 것이 가장 좋은 성능을 보임
- rank = 4인 경우에도 ∆W에서 충분한 정보를 캡처하므로 rank가 더 큰 단일 유형의 가중치를 적용하는 것보다 더 많은 가중치 매트릭스를 적용하는 것이 바람직하다는 것을 의미한다.
adaptation 행렬과 기존 가중치 행렬의 관계

- low rank adaptation 행렬은 학습된 특정 downstream task에 대한 중요 피쳐를 강화하지만 일반적인 사전 학습 모델에서는 강화되지 않는다.
- 또한 GPT3 전체를 fine-tuning하는 것 보다 더 좋은 성능이 나온다고 한다.
future work
LoRA의 장점은
- 사전학습된 모델을 그대로 공유하면서 작은 LoRA 모듈을 여럿 만들 수 있다. 모델을 공유하면서 새로 학습시키는 부분(위 그림의 오른쪽에 있는 A, B)만 쉽게 바꿔끼울 수 있다.
- layer에 추가한 작은 matrices만 학습시키고 효율적으로 메모리를 사용할 수 있다.
- inference 과정에서 추가적인 latency 없이 사용할 수 있다.
- 기존의 많은 방법들과도 동시 사용 가능하다.
Limitation & Future work
- LoRA에 적용할 weight matrix를 선택할 때 heuristics에 의존한다.
- 다른 효율적인 adaptation 방법과 결합하여 성능 개선을 생각해볼 수 있다.
