
본 논문은 2022년 arXiv에 등재된 이미지캡셔닝 관련 논문으로, 기존의 CLIP기반 이미지 캡셔닝 모델의 한계점인 paired data dependency를 극복할 새로운 decoding strategy를 활용한 모델을 제안한다.
Paper : Language Models Can See_ Plugging Visual Controls in Text Generation
1. Introduction
-
Pre-train Language Model
최근 거대 Pre-train 모델은 NLP task에서 좋은 성능을 달성했다. 예를 들어 GPT-2는 디코딩을 통해 next token 예측할 시, textual prompt를 사용하여 원하는 task에 맞는 output을 출력하도록 하여 높은 text generation 성능을 보임. -
Image-Text Embedding Model
CLIP, ALIGN과 같은 모델은 Visual representation을 학습하기 위해 대규모 Noisy Image-Text 쌍을 활용하여 contrastive embedding learning을 수행한다.
이에 따라 인상적인 zero-shot 성능 달성했지만, 이미지 기반 텍스트 생성 task로의 적용은 다른 task(image generation)에 비해 많이 연구되지 않았다.
이에 본 논문에서는 이미지 정보를 활용하여 decoding을 가이드 하는 Image Captioning 모델, MAGIC을 소개한다.
MAGIC (iMAge-Guided text generatIon with CLIP)
: CLIP기반의 "magic score"를 추가하여 새로운 decoding scheme을 적용한 Image-Text 모델
Main Contribution
- 기존 beam search, nucleus등 의 한계점을 극복한 "contrastive search"에 MAGIC Score만을 추가하여, 간단한 “plug-and-play” 원리로 zero-shot 이미지 캡셔닝을 수행했다. 여러 benchmarks에서 SOTA를 달성했다.
- Story generation task에서도 뛰어난 성능을 보였다.
- 불필요한 gradient update 과정이 없어 기존 zero-shot method인 ZeroCap보다 27배 빠른 속도를 보였다.
2. Background
기존의 image captioning 관련 연구는 Supervised / Weakly Supervised / Unsupervised Approach로 나누어 볼 수 있다.
Supervised approaches
- CNN - RNN based methods
: CNN based encoder로 visual features를 추출하고, RNN/LSTM based decoder로 sentence를 출력하는 방법
- Attention Mechanism 활용 methods
: visual - text의 관계를 잘 표현하여 더 풍부하고 적절한 캡션 생성 가능해짐 (ex. BUTD)
- Controllable image captioning
: 추가 annotation을 필요로 하는 control signal을 사용하여 task에 맞는 설명 캡션을 생성 (ex. Senticap)
- V-L pre-training methods
: 거대 dataset으로 pre-train된 모델을 사용하여 visual-textual 표현을 더 잘 학습할 수 있게 됨 (ex. Oscar, ClipCap, LEMON)
많은 발전이 있었지만, Supervised Approach는 여전히 image-text paired data에 의존적이라는 한계가 존재한다.
Weakly Supervised approaches
- paired data에 대한 의존도를 줄이기 위해, weakly supervised methods는 pseudo-captions를 활용한다.
- 그러나, pseudo-captions는 이미지와 관련 없는 단어들을 포함한다.
- 또한, pseudo-captions 생성을 위해서는 고정된 labeled data로 pre-train된 object detector가 필요하다.
Unsupervised approaches, ZeroCAP
최근 거대 pre-trained model 활용한 zero-shot 연구가 진행되어, training data 없이도 task 수행이 가능하게 되었다.
대표적인 zero-shot image captioning : Zerocap
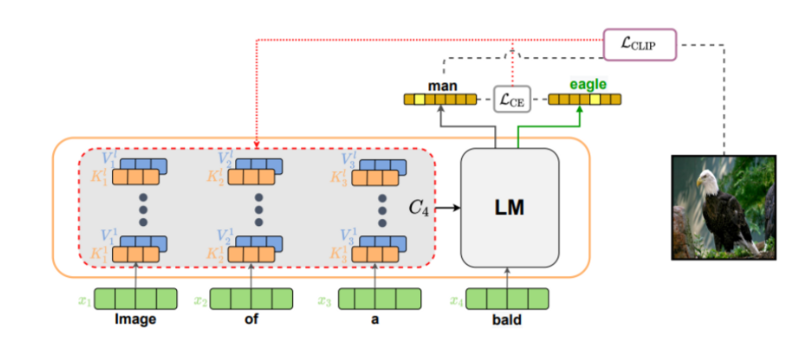
Zerocap은 CLIP으로부터 학습된 V-L knowledge를 활용하여 계산된 clip score로 image-text 매칭을 유도하고, GPT-2로부터 학습된 linguistic knowledge를 활용하여 자연스러운 캡션 생성하게끔 한다.
PROCESS 1 : LM모델을 통해 "Image of a"와 같은 초기 prompt의 다음에 올 단어를 추론
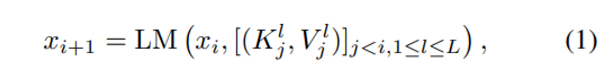
- xi = 생성된 문장의 i번째 단어
- Kjl,Vjl = j번째 토큰의 트랜스포머에서의 key, value값
- l 은 트랜스포머 레이어 인덱스
- Auto-regressive한 방식으로 다음에 올 단어를 추론!
- GPT-2모델을 이용하기 때문에 전체 레이어의 수는 L=24
- Kjl, Vjl 은 반복적으로 사용되기 때문에, 'context cache'에 저장되어 있어야 한다
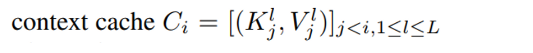
⇒ 두 모델의 재학습이나 fine-tuning 없이도 추론이 가능하다. (zero-shot)
PROCESS 2 : CLIP-Guided language modeling
-
LCLIP : LM이 주어진 image에 맞는 방향으로 단어를 생성
-
LCE : 다음에 올 토큰의 분포가 원래의 language모델의 분포와 유사하도록 유지하는 역할
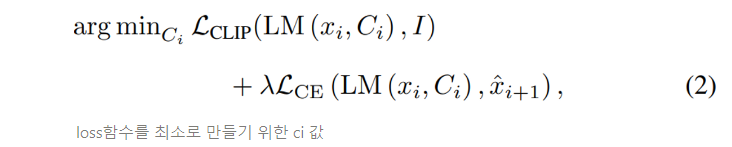
-
x^i+1 = 원래의 변동되지 않은 context cache를 이용한 토큰 분포
-
하이퍼파라미터 λ = 두 loss term간 균형을 맞추는 역할
⇒ 위의 optimization과정을 통해 context cache Ci를 매 타임 포인트마다 조정한다. Optimization은 Autoregression 과정 동안 이루어지며, 각 토큰마다 반복된다.
- 즉, 반복적인 gradient updating으로 추론에 많은 시간 소요된다.
MAGIC은 이러한 많은 연산을 피하기 위해, MAGIC Search를 활용하여 visual 정보를 decoding 과정에 directly하게 적용한다.
3. MAGIC (iMAge-Guided text generatIon with CLIP)
MAGIC의 전반적인 구조는 다음과 같다.
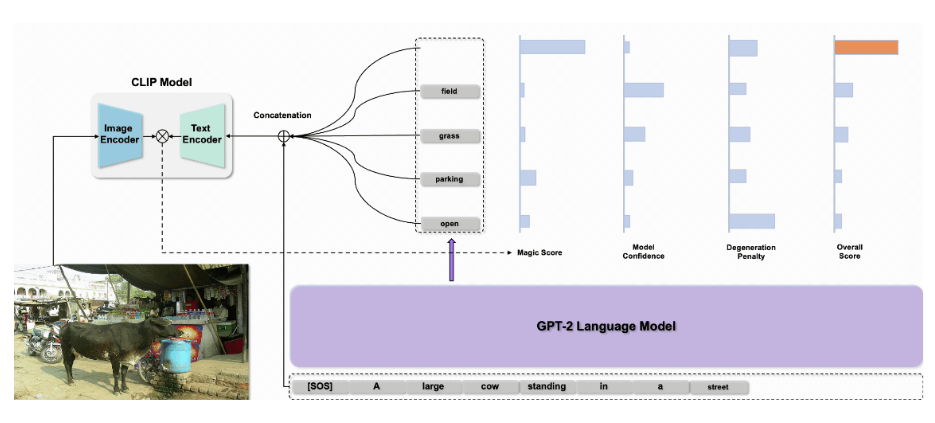
Methodology
Unsupervised Language Modelling
언어생성모델은(ex. GPT-2) 의미있는 text 생성 가능하지만, fine-tuning없이 text decoding 진행 시 특정 세부 task에 관한 text가 부자연스러운 경우가 존재한다.
따라서 본 논문에서는 decoding 하기 전, task 별 text corpus로 언어모델 fine tuning을 수행한다. (decoding 과정에서는 fine-tuning 된 GPT-2와 CLIP은 고정시키고 추가 학습 진행하지 않음)
언어모델의 파라미터 θ를 최적화하기 위한 목적함수는 다음과 같다.
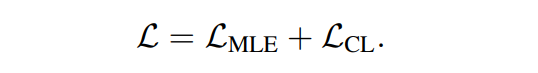
- 언어모델의 목적함수는 MLE Objective(L.MLE)와 Contrastive Objective(L.CL)로 나누어진다.
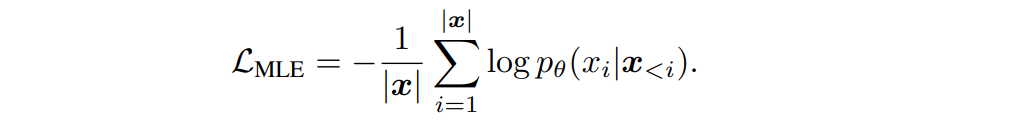
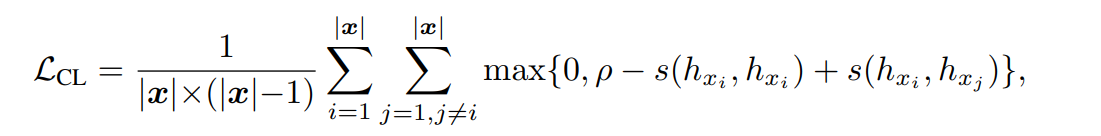
토큰끼리의 코사인 유사도를 반영한 Contrastive objective를 추가하여, Cosine similarity 통해 구별된 토큰의 분포가 더욱 discriminative 하도록 모델의 표현공간을 보정하도록 한다.
이는 모델의 Generality를 향상시키고, 다양한 task에 적용 가능하게 한다. (ex. Story Generation..)
MAGIC Search
논문에서 제안한 decoding strategy "MAGIC Search"는 visual 정보에 따라 decoding을 가이드한다. 매 time step t 마다 생성되는 output token xt는 다음과 같이 표현할 수 있다.
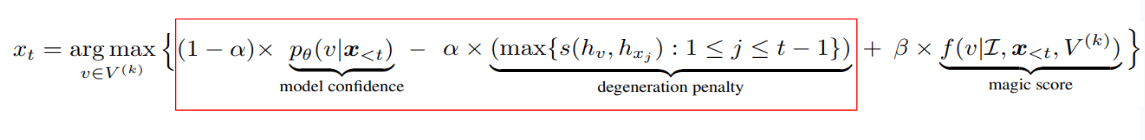
- 표시된 항은 top-k predictions 집합 Vk 에 속한 token에 대해 degeneration penalty를 반영한 예측 확률을 나타낸다.
- model confidence에 degeneration penalty를 추가한 것은 contrastive search 에서 소개한 decoding 방법이다.
- 코사인 유사도를 반영한 degeneration penalty를 적용하여 모델의 degeneration을 방지한다.
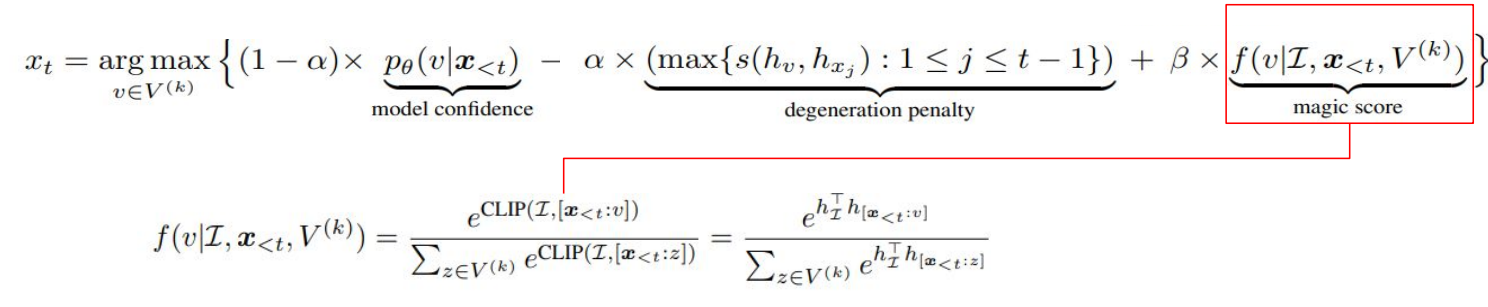
- 디코딩 과정에 visual control을 적용하기 위해, magic score를 추가한다.
- magic score 는 후보집합 Vk에 속한 토큰들에 대한 CLIP기반 image-text 유사도를 나타낸다. 이는 이미지 정보를 반영하여 의미적으로 관련된 next token을 예측할 수 있도록 한다.
( β = 0 일 때에는 visual control이 반영되지 않아 기본적인 contrastive search로 degenerate 됨 )
새롭게 정의한 LM의 목적함수와 MAGIC score를 추가한 디코딩 방법은 ( MAGIC Search ) 추가적인 지도 학습이나 gradient update 없이 visual control을 디코딩 과정에 directly plugging 할 수 있게 한다.
4. Experiments
4-1. Zero-Shot Image Captioning
먼저, Zero-Shot Image Captioning에 대한 실험을 진행했다.
실험을 위해 benchmark data set (MS-COCO, Flikckr30k) 으로 각각 GPT-2 fine-tuning을 진행한다.
- MS-COCO : k, α, and β = 45, 0.1, 2.0
- Flikckr30k : k, α, and β = 25, 0.1, 2.0
=> validation set 성능에 근거한 MAGIC Search 파라미터 - Optimizer : Adam (learning rate : 2e-5), epoch : 3, contrastive loss margin ρ : 0.5
fine-tuning한 모델의 zero-shot captioning 성능을 기존 Baseline zero-shot methods의 성능과 비교한다.
- MAGIC과 비교 할 기존 방법들
1) 기존 decoding methods
- top-k sampling (k=40), nucleus sampling (p=0.95), contrastive search (α, β = magic search에 적용한 값과 동일)
(위 세 가지 methods는 디코딩 과정에서 image 정보를 고려하지 않음)
2) CLIPRe (= CLIP 유사도를 통해 가장 관련성이 높은 캡션을 검색하는 method)
3) ZeroCap
4) 기존 Supervised Methods
Results 1
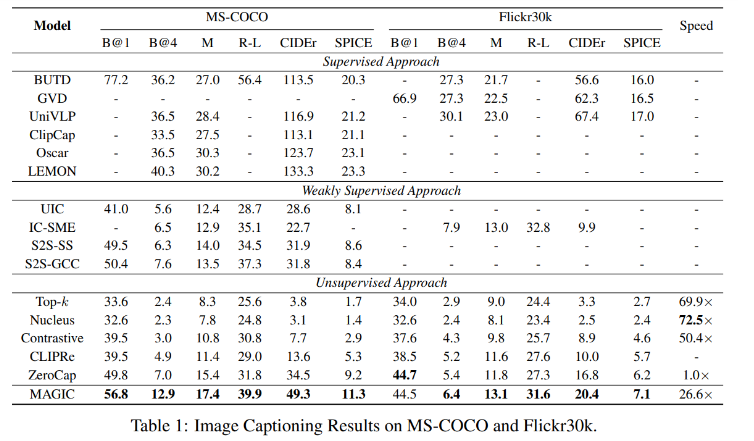
- image input 에 대한 조건 없이 language model 만 사용했을 시 (Top-k, Nucleus, Contrastive), 의미있는 캡션 생성이 어려운 것을 보여준다.
- CLIPRe : training 과 test sets의 데이터 불일치로 인한 격차로 인해 ZeroCap 보다 좋지 못한 성능을 보인다.
- 반면, MAGIC은 11개의 metrics에서 가장 높은 성능 달성했다.
Zerocap보다 27배 빠른 속도를 보인다. (실용적 사용 가능성 보임)
=> 반복적인 gradient updates 과정을 포함하지 않기 때문
Results 2
추가적으로, 모델의 일반화 성능을 측정하기 위해 Cross-Domain Experiment을 수행했다.
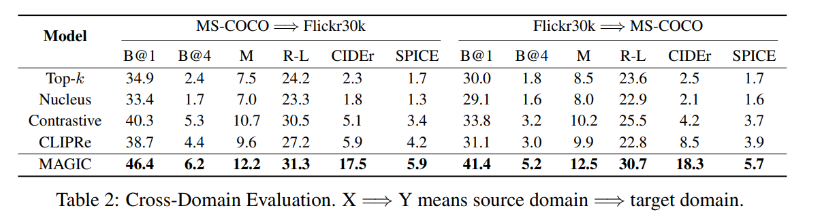
1) MS-COCO의 text corpus로 Fine-tuning 한 모델을 Flickr30k 데이터 셋으로 추론
2) Flickr30k의 text corpus로 Fine-tuning 한 모델을 MS-COCO 데이터 셋으로 추론
- 모든 methods가 In-domain results 보다 낮은 성능을 보였지만, MAGIC은 다른 methods에 비해 좋은 성능을 보인다. => Robustness & Generalization 성능 보여줌
Qualitative Evaluation
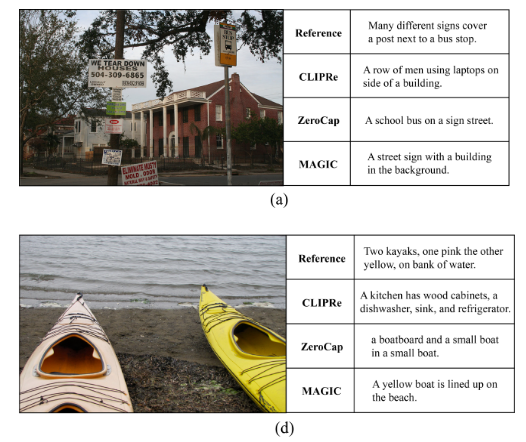
- CLIPRe와 Zerocap이 이미지와 관련없는 단어를 묘사하는 반면, MAGIC은 관련된 물체 표현하면서도, 문법적으로 자연스러운 문장을 생성한다.
4-2. Story Generation
모델의 범용성과 확장성을 확인하기 위해, Story Generation에 대한 실험도 진행하였다.
- Story Generation : story title (i.e., text prompt)을 주었을 때, 언어 모델이 관련된 스토리를 생성하게끔 한다.
- ROCStories benchmark로 Fine-tuning 된 GPT-based Language Model 사용
MAGIC은 visual-language model이기 때문에, Story Title로 text prompt 대신 image input을 사용한다.
1) CLIP으로 계산된 score 활용하여 Story title과 가장 관련있는 Image를 찾는다. (Conceptual Caption Dataset)
2) 찾은 이미지로부터 관련된 story text를 생성한다. (by using MAGIC Search, k = 5, α = 0.6, β = 0.15)
Results
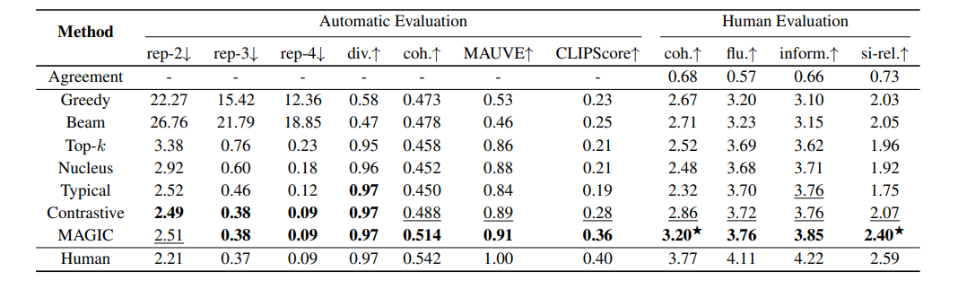
- MAGIC이 모든 Evaluate metrics에서 가장 좋은 성능 보임
=> MAGIC은 다양하면서도 human-written stories와 가장 유사한 stories를 생성한다. - 높은 semantic coherence 점수는 Story title로 찾은 이미지가 다양한 관련된 visual 특징을 포함하고 있는 것을 보여준다. MAGIC은 이러한 Visual 정보를 활용하여 더 많은 정보를 활용한 이미지 캡셔닝을 수행할 수 있다.
5. Conclusion
- MAGIC은 기존 image captioning 모델과 다르게, contrastive search 디코딩 방법에 CLIP기반 magic score만을 추가하여 "plug-and-play" 한 방법으로 이미지 정보를 텍스트 생성시 활용하였다. 이에 따라 불필요한 연산 없이 빠른 Image-Text task 수행이 가능해짐
- 모델 아키텍처에 구애받지 않는 decoding scheme 이므로 다른 task, modal로 확장이 가능한 method이다.
두 가지 이미지-텍스트 task 1)ImageCaptioning, 2)StoryGeneration 에서 기존 SOTA methods에 비해 좋은 성능을 달성했다.
언어모델 fine-tuning 과정이 text corpus만을 사용한 unsupervised한 방법으로 이루어졌다는 점에서 제로샷에 가까운 모델이라고 볼 수 있다. (image-text paired data를 fine-tuning에 사용하지 않음)
여러 tasks(Story generation..)에 적용 가능하여 generality가 높고, 기존 Zero-shot captioning 모델보다도 27배 빠르다는 점에서 실용성이 높은 모델이라고 생각함.
++ 언어 모델의 fine-tuning 과정 없이 온전한 zero-shot으로도 높은 성능을 달성한다면 더 좋을 것 같다는 생각을 했는데, 이를 ConZIC 논문에서 확인해볼 수 있었다!
