reference : lg aimers, 논문, youtube
1. Transformer
자세한 구조는
https://velog.io/@hyeda/transformerbert 에 정리
2. Transformer의 시계열 데이터 적용
- Transformer를 다변량 시계열 데이터에 최초로 적용한 논문이다.
A Transformer-based Framework for Multivariate Time Series Representation Learning (KDD 2021)
본 논문에서는 최초로 다변량 시계열 데이터의 unsupervised 표현학습에 Transformer를 접목한 Time Series Transformer (TST)를 제안한다.
연구배경
- 트랜스포머의 멀티헤드어텐션은 여러 개의 head를 사용함
-> 다양한 측면에서 word token의 context를 기반으로 representation 학습할 수 있다.
-> 이는 시계열 데이터에도 적합! (시계열 데이터의 multiple periodicities 특징에도 적합)
논문 주요 내용
-
Transformer의 Encoder 구조만 사용
-
Pre-training 위해 연속적인 길이의 Input Masking 사용
-
Layer Normalization 대신 Batch Normalization 사용
-
Fine-tuning 단계에서 구조를 어떻게 설계하느냐에 따라 Classification, Regression, Forecasting, Missing Value Imputation 등 다양한 Task에 적용 가능
Time-Series Transformer (TST) 작동 원리
1) Pre-training task
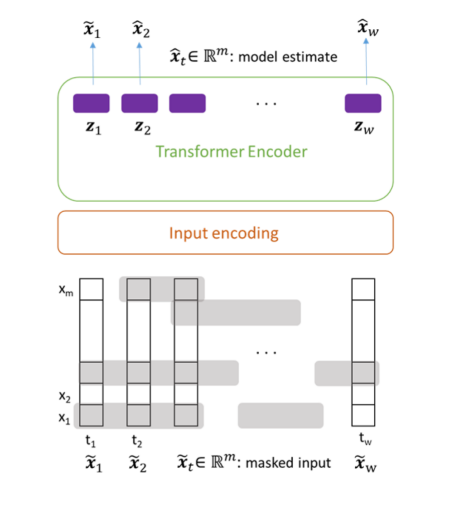
- Transformer의 사전 학습 목적은 Masking 된 부분을 정확하게 예측하는 것
- Masking의 길이가 평균 lm만큼이 되는 기하분포를 따르도록 Markov Chain을 적용하여 Masking 여부를 결정하고 마스킹을 한다.
Markov Chain 적용 이유?
- 각 Cell에 대한 Masking 여부를 독립적으로 결정하게 되면 Trivial Solution으로도 문제를 잘 맞추는 상황이 발생하게 됨
- Trivial Solution : Masking된 Cell의 이전 시점 혹은 이후 시점 값을 그대로 사용하거나 양쪽 Cell의 평균값을 사용하는 것
- Masking된 부분의 실제 값과 예측 값의 mean squared error (MSE)
를 기반으로 모델을 학습한다. (Pre-training)
2) Self-Attention in Transformer Encoder Block
- 총 3개의 Encoder 블록을 사용
- NLP에서의 Transformer와 마찬가지로 TST에서도 입력 데이터에 포지션 인코딩을 더해서 Transformer 인코더의 입력 값으로 사용
- NLP에서의 Transformer와 다르게 Layer Normalization 대신 Batch Normalization을 사용
* 이유 *
▪시계열 데이터에는 NLP Word Embedding에는 없는 이상치(Outlier)가 존재함
▪ 시계열 데이터는 각 관측치의 길이 변화가 NLP의 문장 길이의 변화보다 작음
▪ 이러한 상황에서는 실험적으로 Batch Normalization이 Layer Normalization보다 성능이 우수한 것으로 입증됨
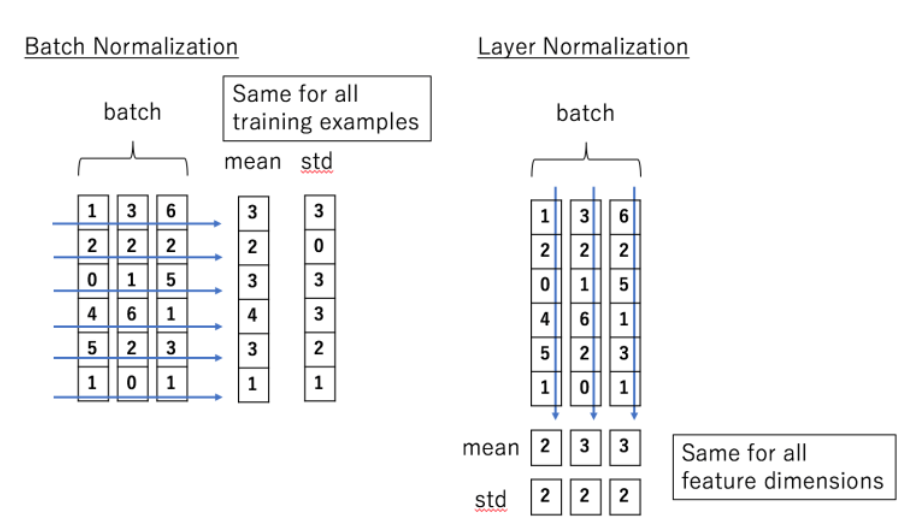
Layer Normalization vs Batch Normalization ?
- LN은 각 input의 feature들에 대한 평균과 분산을 구해서 batch에 있는 input을 정규화
- BN은 각 feature의 평균과 분산을 구해서 batch에 있는 feature 를 정규화
3) Fine-tuning
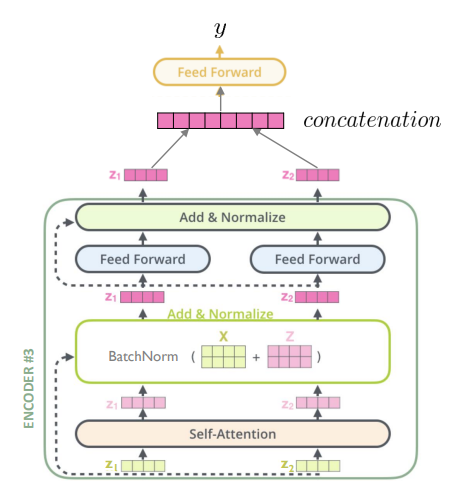
1단계)
Masking를 적용하지 않은 Input Time Window를 Input encoding과 Transformer Encoder에 순차적으로 넣어 Representation을 도출한다.
2단계)
도출된 모든 시점의 Representation을 Concatenation 한 것을 Output Linear Layer에 Input으로 넣어 Regression 또는 Classification의 정답을 예측한다.
3단계)
Task의 실제 정답과 TST가 예측한 값의 차이를 통해 Output Linear Layer를 Fine-funing
-
세부적으로 z를 새로운 linear output layer에 input으로 넣어 regression 및 classification을 수행하며, 해당 layer만 task에 맞는 loss를 통해 학습한다.
-
논문에서는 fine-tuning task를 수행하기 위한 output layer를 제외한 pre-trained model은 freezing하고 fine-tuning을 진행
Experiments
- 평가지표 : RMSE, 모든 모델의 평균 Root MSE 대비 각 모델의 Root MSE 감소/증가 비율
- fully supervised TST도 학습하여 pre-training 사용 여부에 따른 모델의 학습 시간 및 성능을 비교함
Results - Regression

- TST가 총 6개의 데이터셋 중 4개에서 가장 좋은 성능을 도출했다.
- 6개의 데이터셋 중 3개에서 TST(pretrained)가 TST(sup. only)보다 높은 성능을 도출했다.
-> 동일한 training set을 unsupervised/supervised way로 중복 사용하여 모델을 학습하는 것이 효과가 있다는 것을 확인할 수 있다.
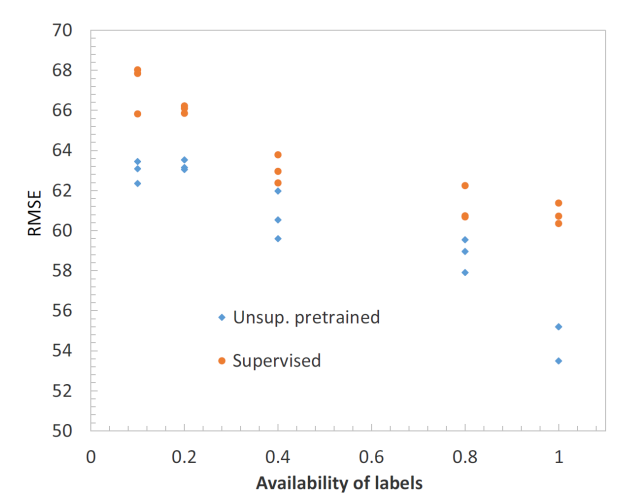
-
Supervised learning에 사용되는 label의 비율 증가에 따른 TST(pretrained)와 TST(sup. only)의 성능 변화?
- 두 모델 모두 사용 가능한 label의 비율이 증가할수록 성능이 향상됨
- TST(pretrained)가 TST(sup. only) 보다 모든 비율에서 높은 성능을 달성했따 --> 동일한 training set을 중복해서 사용하여 학습했을 때의 효과를 입증
정리
-
트랜스포머의 포지셔널 인코딩, 멀티헤드어텐션은 sequence data를 처리에 특화됨. 실제로 좋은 성능을 달성
-
TST의 Pre-training~Fine tuning 방식은 일반적인 LLM 학습 방식과도 유사하다.
-
같은 sequence data여도 text 데이터와 시계열 데이터 특성에 따라 더 적합한 학습 방식이 존재하므로 이를 고려할 필요가 있다. (시계열 데이터 -> 이상치가 존재하고, 길이 변화가 text data에 비해 적음)

좋은 글 잘 읽었습니다, 감사합니다.