분산 데이터 저장 기술
- 분산 파일 시스템 ✅
- 데이터베이스 클러스터
- NoSQL
분산 파일 시스템
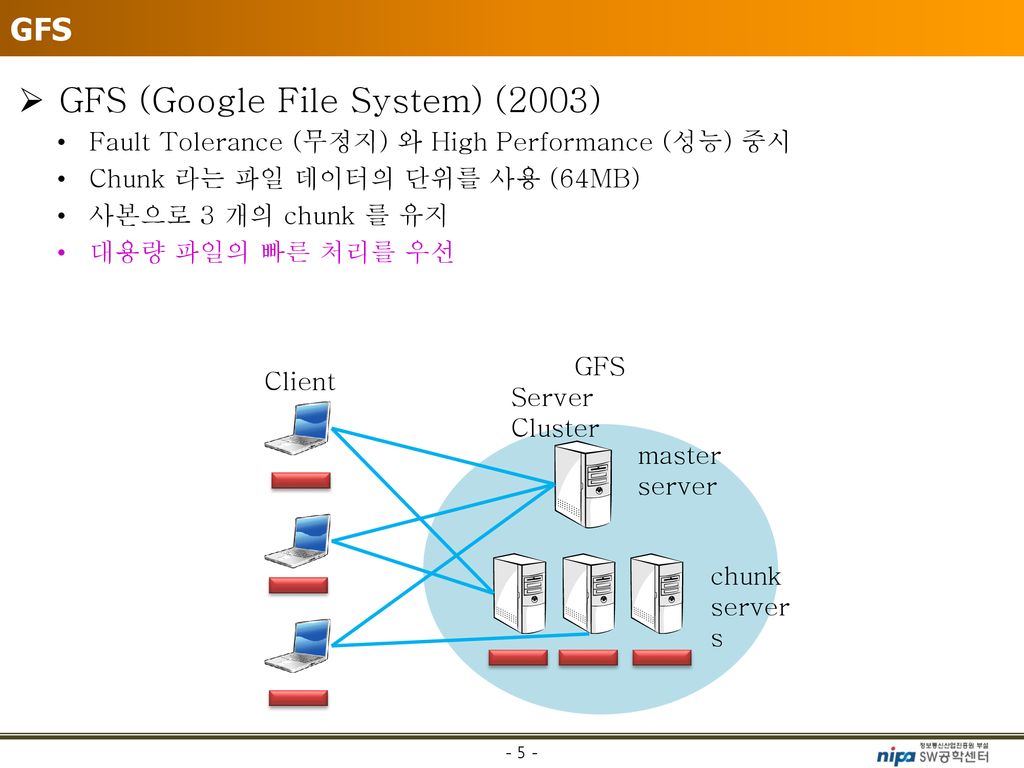
구글 파일 시스템(GFS)
- 구글의 대규모 클러스터의 기반이 된다.
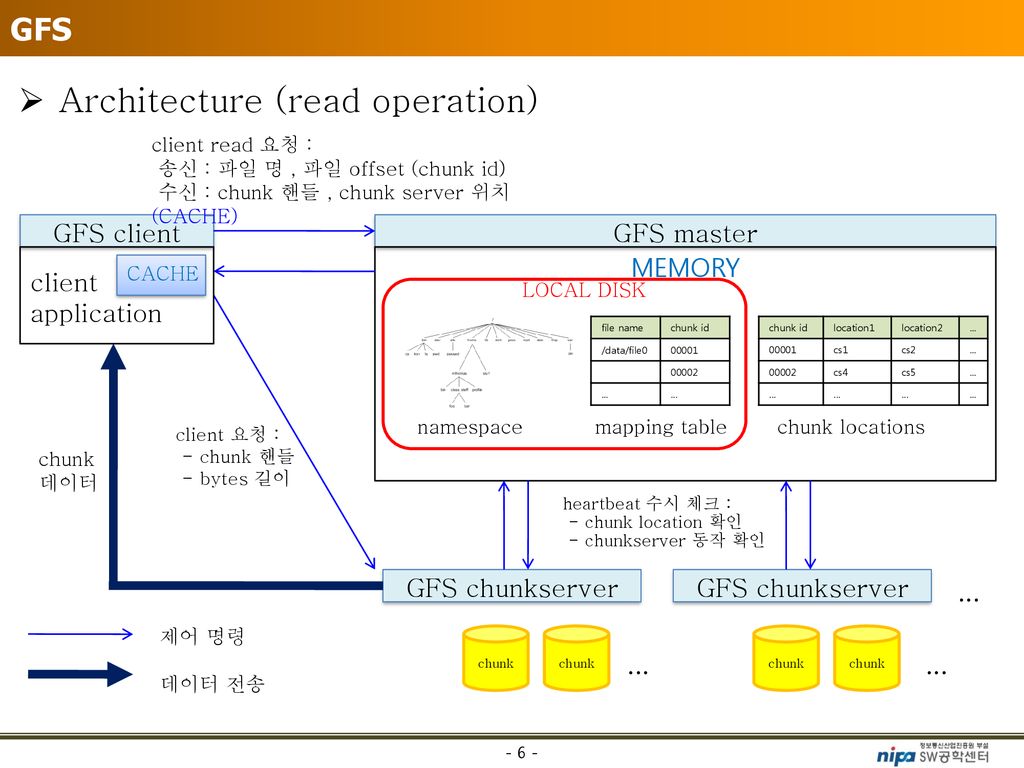
- 해시 테이블 구조를 사용해 메타데이터의 처리를 지원
- 대부분의 파일은 대용량으로 가정했는데 그 이유는?
구글의 핵심 데이터 스토리지와 구글 검색 엔진을 위해 최적화된 시스템이기 때문이다. - 서버의 고장이 빈번히 발생할 수 있다고 가정
- 가격이 저렴한 서버에서도 사용되도록 설계되었기 때문에 하드웨어 안정성이나 자료들의 유실에 대해서 고려하여 설계되었다.
- 사용자와 시스템 간의 상호작용이 아닌 시스템과 시스템간 상호작용한다.
- 빅파일에서 수정된 시스템
빅파일이란
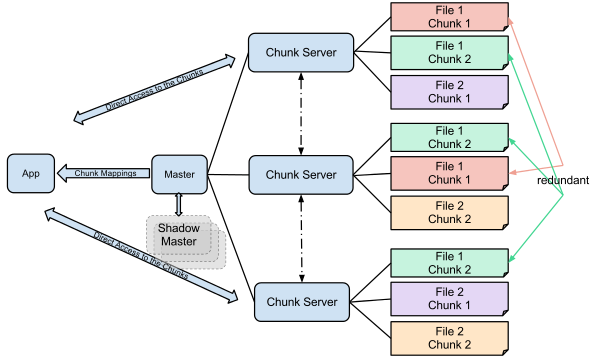
빅 파일은 서버 클러스터의 컴퓨터 중 하나에서 사용 가능한 디스크 공간 청크를 찾아 해당 컴퓨터에 저장할 파일을 제공하는 동시에 어떤 파일이 어떤 컴퓨터에 저장되어 있는지 추적합니다.
- chunk서버들은 데이터를 자동으로 복제한다.
- 구성도
하둡 분산 파일 시스템 (HDFS)
- GFS를 클로닝한 프로젝트이기 때문에 비슷한 점이 많다.
- 다른 점은 한 번 쓰이면 변경되지 않는다고 가정한다는 것.(GFS는 갱신이 드물게 일어난다고 가정한다.)
- 하둡 분산 파일 시스템은 다음과 같은 시스템에서 잘 동작하는 것을 목표로 하고 있다.
- 하드웨어 오동작:하드웨어 수가 많아지면 그중에 일부 하드웨어가 오동작하는 것은 예외 상황이 아니라 항상 발생하는 일이다. 따라서 이런 상황에서 빨리 자동으로 복구하는 것은 HDFS의 중요한 목표다.
- 스트리밍 자료 접근: 범용 파일 시스템과 달리 반응 속도보다는 시간당 처리량에 최적화되어 있다.
- 큰 자료 집합: 한 파일이 기가바이트나 테라바이트 정도의 크기를 갖는 것을 목적으로 설계되었다. 자료 대역폭 총량이 높고, 하나의 클러스터에 수 백개의 노드를 둘 수 있다. 하나의 인스턴스에서 수천만여 파일을 지원한다.
간단한 결합 모델: 한번 쓰고 여러번 읽는 모델에 적합한 구조이다. 파일이 한번 작성되고 닫히면 바뀔 필요가 없는 경우를 위한 것이다. 이렇게 함으로써 처리량을 극대화할 수 있다. - 자료를 옮기는 것보다 계산 작업을 옮기는 것이 비용이 적게 든다: 자료를 많이 옮기면 대역폭이 많이 들기 때문에 네트워크 혼잡으로 인하여 전체 처리량이 감소한다. 가까운 곳에 있는 자료를 처리하게 계산 작업을 옮기면 전체적인 처리량이 더 높아진다.
- 다른 종류의 하드웨어와 소프트웨어 플랫폼과의 호환성: 서로 다른 하드웨어와 소프트웨어 플랫폼들을 묶어 놓아도 잘 동작한다.
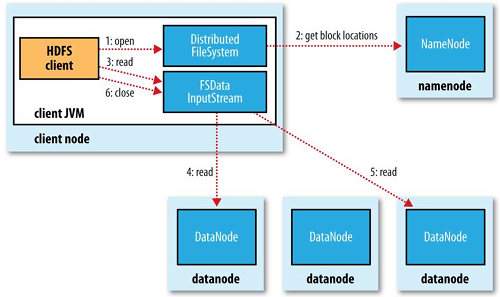
HDFS 저장 및 읽기 과정
저장
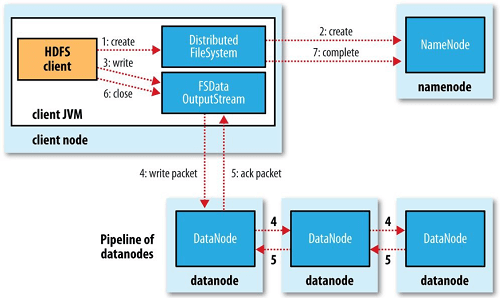
읽기
⭐️ GFS와 HDFS의 비교
| GFS | HDFS | |
|---|---|---|
| 단위 | 64MB의 청크로 나눈다. | 블럭 단위로 나눈다. |
| 부하 | 연속적으로 데이터를 많이 읽는 연산이나 임의의 영역에서 적은 데이터를 읽는 연산에서 부하 발생. | 자료를 많이 옮기는 것은 처리량이 감소한다. 가까운 곳에 있는 자료를 처리하게 계산 작업을 옮기면 전체적인 처리량이 더 높아진다. |
| 연산 | 쓰기 연산은 순차적으로 이루어진다. | 순차적 스트리밍 방식으로 파일 저장 또는 조회한다. |
| 중요점 | 낮은 응답 지연시간보다 높은 처리율이 더 중요하다. | 낮은 데이터 접근 지연 시간보다 높은 데이터 처리량에 중점을 둔다. |
| 구성요소1 | 마스터 : 단일 마스터 구조. 모든 메타데이터를 메모리 상에서 관리. chunk의 상태(하트비트)를 받아 회복 동작을 수행. 마스터에 대한 장애가 생겼을 때 chunk의 매핑 변경 연산을 로깅, 마스터의 상태를 여러 섀도 마스터에 복제. (메타데이터는 해시테이블 구조 이용해 관리) | 네임노드 : HDFS상 모든 메타데이터 관리. 시스템 전반적인 상태 모니터링. 데이터노드로부터 하트비트를 받아 상태 체크. |
| 구성요소2 | 청크서버 : 클라이언트로부터 요청받은 chunk 입출력 수행. 하트비트를 마스터에게 주기적으로 전송. | 데이터노드 : 슬레이브 노드. 클라이언트로부터 요청받은 데이터 입출력 수행. 블록을 3중 복제해 저장. 블록 저장 시 체크섬 별도로 저장. 하트비트를 네임노드에 주기적으로 전송. |
| 구성요소3 | 섀도우 마스터: 마스터 상태가 복제된 마스터 | 보조네임노드 : HDFS 상태 모니터링을 보조. 네임 노드의 스냅샷 생성. |
🤔 보조네임노드란?
- 보조 네임노드가 필요한 이유
네임노드는 HDFS의 메타데이터를 관리하기 위해 에디트로그(EditLog)와 파일시스템이미지(FsImage) 파일을 사용한다.
- 에디트로그 : HDFS의 메타데이터에 대한 모든 변화를 기록하는 로그 파일. HDFS에 새 파일을 저장, 기존 파일 삭제, 파일 위치 변경 등 모든 파일의 상태를 기록. 용량 제한이 없이 파일 크기가 증가 할 수 있으며 네임노드 서버 로컬에 위치한다.
- 파일시스템이미지 파일 : 파일 시스템의 네임 스페이스(디렉터리명, 파일명, 상태정보)와 파일에 대한 블록 매핑 정보를 저장하는 네임노드의 로컬에 위치한다.
네임노드는 위의 두 파일을 사용하여 메타데이터를 관리 한다. 파일 시스템의 네임스페이스와 파일의 블록 매핑 정보를 메모리에서 유지하며 네임노드가 구동될 때 파일 시스템 이미지 파일과 에디트로그를 사용한다.
에디트로그 파일의 사이즈가 너무 크다면 메모리에 적재하는데 오랜 시간이 걸리며 상황에 따라 메모리에 로딩하지 못할 수도 있다. 이러한 문제를 해결하기 위해 HDFS는 보조 네임노드를 사용하여 주기적으로 네임노드의 파일시스템이미지 파일을 갱신하도록 한다.
이러한 작업을 체크포인트(checkpoint)라고 하며 보조 네임노드를 체크포인팅 서버라고 부르기도 한다. 체크포인팅이 완료되면 파일 시스템 이미지 파일은 최신으로 갱신되며 에디트로드 파일의 사이즈는 축소된다. 체크포인팅의 기본 값은 1시간이며 하둡 설정 파일(fs.checkpoint.period)에서 변경이 가능하다.
참고 페이지
보조 네임 노드는 충분한 CPU와 네임 노드 만큼의 메모리가 필요하므로 별도의 물리머신이 필요하다.
참고 페이지
뒤에서 맵리듀스가 나오는데 하둡에서 맵리듀스 레이어와 HDFS레이터가 따로 있다.
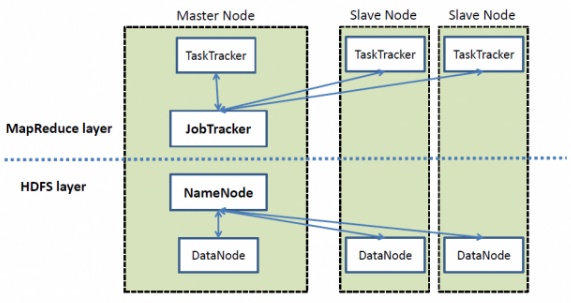
위 이미지 참고 사이트
러스터(Luster)
객체 기반의 클러스터 파일 시스템
구성요소
| 클라이언트파일 시스템 | - 리눅스 VFS(Virtual File System)에서 설치할 수 있는 파일 시스템 - 메타데이터 서버와 객체 저장 서버들과 통신하면서 클라이언트 어플리케이션에 파일 시스템 인터페이스 제공 |
| 메타데이터 서버 | - 파일 시스템의 이름 공간과 파일에 대한 메타데이터 관리 |
| 객체 저장 서버 | - 파일 데이터를 저장, 클라이언트로부터 객체 입출력 요청을 처리 |
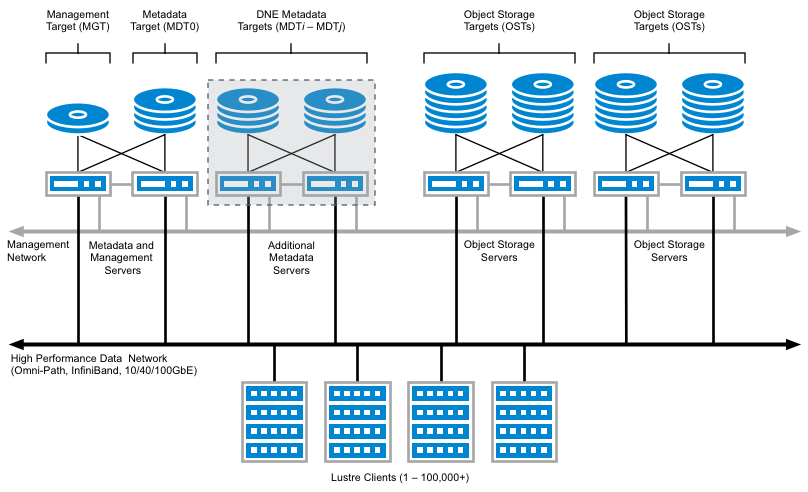
구동방식
- 유닉스 시맨틱(POSIX)를 제공, 메타 데이터에 대해서는 라이트백 캐시를 지원. -> 클라이언트에서 메타 데이버 변경에 대한 갱신 레코드를 생성하고 나중에 메타데이터 서버에 전달
라이트백 캐시 : 캐시에만 저장하고 캐시영역에서 밀려나는 경우에만 하위 저장소에 저장하는 방식
- 메타데이터 서버는 전달된 갱신 레코드를 재수행해 변경된 메타데이터 반영
- 메타데이터에 대한 동시 접근이 적으면 클라이언트 캐시 이용한 라이트백 캐시를 사용
- 메타데이터에 대한 동시 접근이 많으면 메타데이터 서버에서 메타데이터를 처리하는 방식을 적용한다.
- 메타데이터와 파일 데이터에 대한 동시성 제어를 위해 별도의 잠금을 사용.
- 메타데이터 접근 방법 : 메타데이터 서버의 잠금 서버로부터 잠금을 획득
- 파일 데이터 접근 방법 : 해당 데이터가 저장된 객체 저장 서버의 잠금 서버로부터 잠금 획득
- 메타데이터에 대한 잠금 요청 시 접근 의도를 같이 전달하는 인텐트 기반 잠금 프로토콜 사용.
