RAG 란 AI 가 외부 지식을 검색하고 접근할 수 있도록 문서를 불러오고 그걸 기반으로 답변을 생성하는 방식을 말한다.
RAG 왜 쓰나 ?
만약, A 라는 기업에 다니고 있다고 가정해 보자.
A라는 기업에서 제공하고 있는 상품에 대해서 사용자에게 답변을 해주어야 하는데, A의 경쟁사인 B 기업이 제공하는 상품도 추천해 준다면 목적에 맞지 않는다.
그래서 A라는 기업에서 제공하는 정보를 기반으로 (예를 들어 문서나, 스크래핑 해서 긁어온 정보 등) AI에게 프롬프트를 던지는 방식이다.
RAG는 다음의 과정을 따른다.
- 인덱싱
- 데이터 로딩 -> 청크단위로 나누기 -> 임베딩
- 검색 & 생성
간단한 txt 파일로 불러와서 예제를 만들어 보겠다.
1. 인덱싱
데이터 로딩 우선 파일을 불러온다.
from langchain.document_loaders import TextLoader
loader = TextLoader('.\\data.txt', encoding='utf-8')
documents = loader.load()
데이터 파일은 다음과 같다.
프랑스의 수도는 파리이다. 파리는 유럽에서 가장 인기 있는 관광 도시 중 하나로, 에펠탑과 루브르 박물관이 유명하다.
독일의 수도는 베를린이다. 베를린은 역사적으로 중요한 도시이며, 베를린 장벽으로 유명하다.
일본의 수도는 도쿄이다. 도쿄는 기술과 문화의 중심지로, 애니메이션과 음식 문화가 발달해 있다.청크 단위 분리
from langchain.text_splitter import CharacterTextSplitter
text_splitter = CharacterTextSplitter(chunk_size=100, chunk_overlap=50)
docs = text_splitter.split_documents(documents)embedding 단계
LLM이 질문과 문서가 비슷한 의미를 가지는지 판단해야 하기 때문에, 숫자 벡터로 변환해서 수치화 한다.
Vector 데이터는 숫자들의 그룹이기 때문에 나중에 유사도를 비교할 수도 있고, 이를 통해서 비슷한 것들을 빠르게 찾아줄 수 있다.
또한, 비정형 데이터들을 컴퓨터가 이해할 수 있도록 해주는 역할도 한다.
다음과 같은 경우에 활용할 수 있다.
- 사용자의 행동 데이터를 벡터로 변환해서 유사한 사용자나 아이템을 추천해줄 때
- 이미지 검색, 자연어 처리, 생물정보학 등
from langchain_openai import OpenAIEmbeddings
embedding_model = OpenAIEmbeddings(openai_api_key=apikey)
doc_texts=[doc.page_content for doc in docs]
vector = embedding_model.embed_documents(doc_texts)
DB 저장단계
이전에 텍스트를 불러와서 청크로 나누고 -> 청크를 벡터로 변환하는 임베딩 단계를 거쳤다. 이제 이 벡터 데이터를 DB에 저장을 해야한다.
Vector DB 로는 FAISS , Pinecone 등 이 있는데, 우선 Chroma 를 사용해 보겠다.
큰 데이터를 처리하는 경우가 아니라 가벼운 정도라면 Chroma 를 활용하면 빠르게 처리할 수 있다.
예제 코드
from langchain.vectorstores import Chroma
vectorstore = Chroma.from_documents(
documents=docs,
embedding=embedding_model,
persist_directory=".\\chroma_db"
)
vectorstore.persist()하나씩 살펴 보자
documents는 이전에 데이터 나누는 단계에서 청크 단위로 분리 했던 데이터 파일을 말한다.
embedding은 어떤 모델을 사용할지에 대한 얘기다. 나는 embedding_model = OpenAIEmbeddings(openai_api_key=apikey) 을 사용했다.
persist_directory 는 벡터 DB를 저장할 디렉토리 경로이다.
이렇게 만든 store를 persist() 해주면 디스크에 벡터DB가 저장이 된다.
Retriever & LLM 생성
이제 저장된 vectorDB 를 기반으로 리 Retriver 와 LLM을 생성한다.
Retriever 란 질문에 대해 의미적으로 유사한 청크를 벡터 DB에서 찾아주는 도구이다.
리트리버를 생성하는 코드는 다음과 같다.
retriever = vectorstore.as_retriever()LLM을 생성하는 코드는 너무 많이 했다 !
llm = ChatOpenAI(api_key=apikey, model_name=default_model)+ 왜 리트리버가 있나 ?
LLM은 오직 입력받은 텍스트에 대해서 답변만 하기 때문에, 문서에서 검색을 해주는 retriever 가 필요 !
어떻게 사용하는지는 예제를 통해서
이제 vectorDB에 저장하고, 리트리버와 LLM을 만들었다.
그 다음 LAG chain을 만드는 과정을 예제를 통해서 살펴보자.
from langchain.chains import RetrievalQA
qa_chain = RetrievalQA.from_chain_type(
llm = llm,
retriever=retriever,
return_source_documents=False
)
리트리버QA 체인을 구성하는 코드는 위와 같다. 다른 부분은 이해할 수 있을 거다
return_source_documents 는 답변과 함께 검색된 문서 를 함께 반환할지에 대한 여부이다.
쿼리를 주고 응답을 받아오는 코드는 다음과 같다
query = "프랑스의 수도는 어디인가요 ?"
result = qa_chain.run(query)
print(result)프랑스의 수도는 파리입니다.다음과 같이 data.txt 안에서 내용을 잘 찾아온다.
그럼, txt 파일에 없는 내용을 물으면 어떻게 될까?
query = "영국의 수도는 어디인가요 ?"
result = qa_chain.run(query)
print(result)영국의 수도는 런던입니다.이상하다. 분명 리트리버가 벡터데이터에서 유사한 정보를 찾고 그거를 기반으로 LLM 이 응답을 준다고 했는데, data.txt 파일에 없는 영국에 대한 질문을 했는데 답변을 잘 해준다.
리트리버가 잘못한 것일까 ?
-> 아니다
리트리버가 context 문서를 검색을 하고, data.txt에 영국과 관련된 내용이 없으면 빈 context를 반환을 하는데,
LLM이 context + question을 바탕으로 답변을 하기 때문에, 이미 훈련된 사전 지식을 바탕으로 추론해서 답을 한다.
그래서 직전 포스트에서 다뤘던 템플릿 이 필요하다.
custom_prompt = PromptTemplate(
input_variables=["context", "question"],
template="""
너는 주어진 context(문서)에서만 답변해야 해. 만약 context가 비어 있거나,
context에 답이 없으면 반드시 "그런 내용 없습니다."라고 답해.
Context: {context}
Question: {question}
답변:"""
)
qa_chain = RetrievalQA.from_chain_type(
llm = llm,
retriever=retriever,
chain_type_kwargs={"prompt": custom_prompt},
return_source_documents=False
)
위와 같이 템플릿을 만들어서 chain_type_kwargs 에 넘겨주면 된다.
context 는 리트리버가 문서에서 찾은 context 가 주입 되고, qustion 에는 우리가 qa_chain.run(query) 넘긴 쿼리가 자동으로 매핑된다.
그럼 다시 영국에 대해서 질문해 보자.
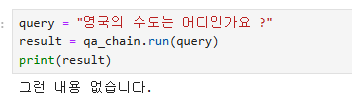
이제 context에 없던 내용은 잘 필터링 되는 것을 알 수 있다.
FAISS
위에서 Chroma DB를 활용한 예제를 봤는데, 이번에는 FAISS DB를 활용한 예제를 보겠다.
FAISS는 대규모 임베딩 데이터에서 유사한 항목을 빠르게 찾는 데 사용할 수 있다.
우선 패키지를 설치하자
pip install faiss-cpu
pip install pypdf
pip install sentence_transformers이번에도파일을 읽어와서 임베딩을 한 후 벡터 값을 저장한다.
pdf 읽는 방식은PyPDFLoader를 활용한다.
파일 읽기
from langchain.document_loaders import PyPDFLoader
loader = PyPDFLoader(".\\The_Adventures_of_Tom_Sawyer.pdf")
documents = loader.load()청크 단위 분할
text_splitter = CharacterTextSplitter(chunk_size=500, chunk_overlap=100)
docs = text_splitter.split_documents(documents)파일 저장
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import FAISS
embeddings = OpenAIEmbeddings(api_key=apikey)
db = FAISS.from_documents(docs, embeddings)template 생성
custom_prompt = PromptTemplate(
input_variables=["context", "question"],
template="""
너는 주어진 context에서만 답변해야 해.
만약 context에 관련 정보가 없거나 query와 무관하면 반드시 "그런 내용 없습니다."라고 답해.
Context: {context}
Question: {question}
답변:"""
)Retriever & LLM 생성 및 쿼리 요청
llm = ChatOpenAI(model_name=chain_model, api_key=apikey)
retriever = db.as_retriever()
qa_chain = RetrievalQA.from_chain_type(
llm=llm,
retriever=retriever,
chain_type="stuff",
chain_type_kwargs={"prompt": custom_prompt},
return_source_documents=False
)
query = "마을 무덤에 있던 남자를 죽인 사람은 누구니?"
result = qa_chain.run(query)
Injun Joe입니다.잘 나온다 !
LAG 방식을 잘 활용해서 맞춤 서비스 추천이나 여러 부분에서 활용할 수 있을 것 같다.
오류
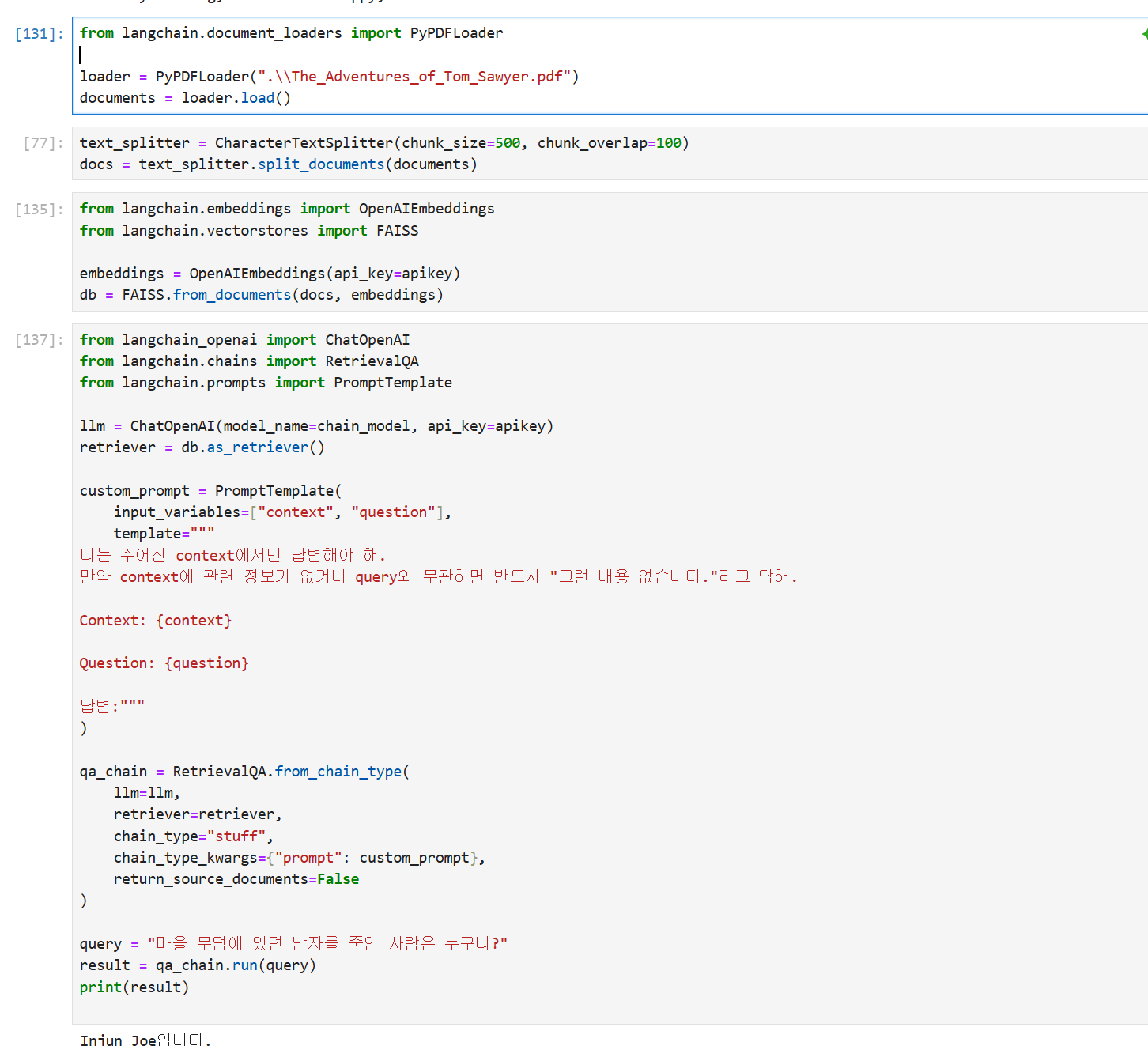
나오다가 안 나오다가 한다... 이유가 뭘까 ?
4개의 셀을 순서대로 하면 안 나오고, 순서대로 했다가 2번 셀 실행 후 4번 셀을 실행하면 잘 된다... 뭐지 ?
해결
다시 셀을 처음부터 다시 실행해 보니 잘 된다.
노트북에서 계속 셀을 왔다갔다 반복해서 하다보니 db 에 저장하는 부분에서 꼬인 것 같다.
