
인공 신경망으로 복잡한 함수 모델링
단일층 신경망 요약
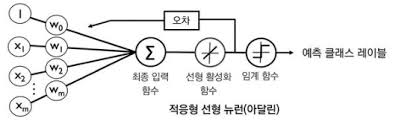
아달린은 다음과 같이 이진 분류를 수행하는 알고리즘이다. 이때 가중치 w를 업데이트 하기 위한 공식은 다음과 같다.
즉, 전체 훈련 데이터셋에 대해 gradient를 계산하고 gradient의 반대 방향으로 진행하도록 모델 가중치를 업데이트 한다.
모델의 학습을 가속시키기 위해 확률적 경사 하강법이 존재한다. 확률적 경사하강법은 하나의 훈련 샘플(온라인 학습) 또는 적은 수의 훈련 샘플(미니 배치 학습)을 사용해 비용을 근사한다
다층 신경망 구조
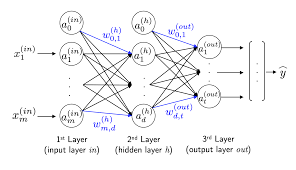
다음과 같이 세개의 층으로 구성된 다층 퍼셉트론(MLP)가 존재한다.
위는 입력층 하나, 은닉층 하나, 출력층 하나로 구성된다. 이처럼 하나 이상의 은닉층을 가진 네트워크를 심층 인공 신경망이라고 한다.
이때 과, 은 절편을 위해 추가한 특성으로 1이 된다. 수식으로 표현하면 다음과 같다.
정방향 계산으로 신경망 활성화 출력 계산
MLP 모델의 출력을 계산하기 위해 정방향 계산(forward propagation) 과정이 있다.
1. 입력층에서 정방향으로 훈련 데이터의 패턴을 네트워크에 전파하여 출력을 만듦
2. 네트워크의 출력을 기반으로 비용 함수를 이용해 최소화해야 할 오차를 계산함
3. 네트워크에 있는 모든 가중치에 대한 도함수를 찾아 오차을 역전파 하고 모델을 업데이트함
이 단계들을 에포크동안 반복하여 가중치를 업데이트 한다. 은닉층에 있는 모든 유닉은 입력층에 있는 모든 유닛과 연결되어 있기 때문에 은닉층 의 활성화 출력을 계산한다.
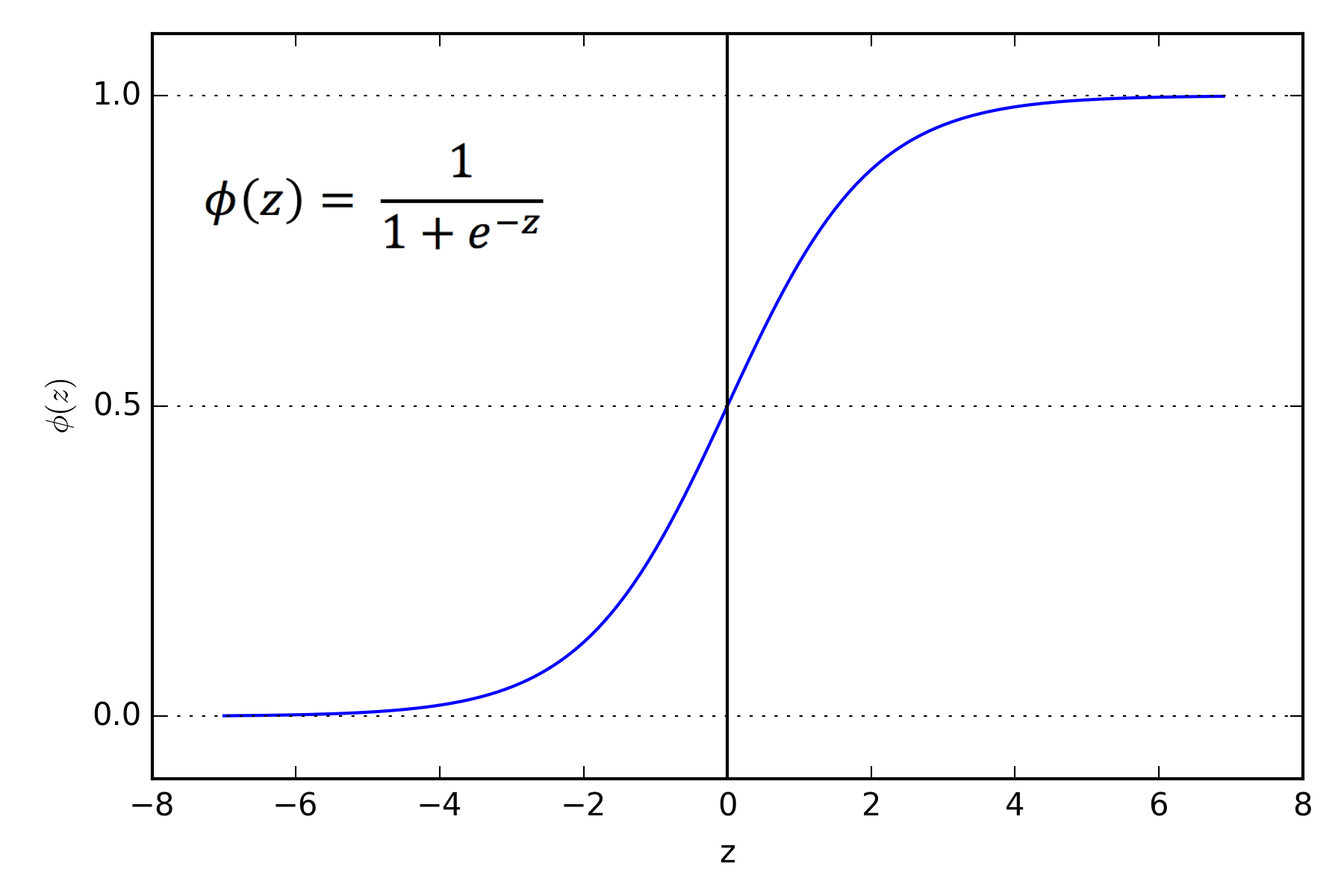
이때, 이미지 분류와 같은 복잡한 문제를 해결하기 위해선 시그모이드 활성화 함수와 같이 비선형 활성화 함수를 사용해야 한다.
시그모이드 함수
이를 그래프로 그려보면 다음과 같다.
손글씨 숫자 분류
해당 코드는 다음 사이트에 올라와 있다.
https://github.com/hyeonsoo0625/review-machinelearning-textbooks/tree/main/ch12/
인공 신경망 훈련
로지스틱 비용 함수 계산
로지스틱 비용 함수는 다음과 같다.
와 같이 나타낸다. 이때 과대적합의 정도를 줄여 주는 규제항을 추가하면 된다. L2 규제 항은 다음과 같다.
이를 로지스틱 비용 함수에 추가하면 다음과 같다.
역전파 알고리즘 이해
역전파 알고리즘을 다층 신경망에서 복잡한 비용 함수의 편미분을 효율적으로 계산하기 위한 방법으로 생각할 수 있다.
컴퓨터 대수학에서는 chain rules를 효율적으로 풀기 위해 자동미분이 존재한다. 자동 미분은 정방향과 역방향 2가지가 있다.
신경망의 수렴
온라인 학습에서는 한번에 하나의 훈련 샘플(k=1)에 대해 gradient를 계산하여 가중치를 업데이트 한다. 이는 기본 경사하강법에 비해 훨씬 빠르게 수렴한다.
미니 배치 학습은 n개의 훈련 샘플 중 k개의 부분집합에서 gradient를 계산한다. 이는 계산 효율성을 극대화 할 수 있다.
