- classification
- 고양이 사진이 있으면 고양이인지 판별해 주는 것 - classification + Localization
- 고양이가 어디에 있는지 boxing - Object Detection
- 여러개의 Object들을 찾아내는 것 - Instance Segmentation
- 동물의 형상들을 따는 것

Classification + Localization
Classification
- Input: Image
- Output: Class label
- Evaluation metric: Accuracy
Localization
- Input: Image
- Output 사진 안에 있는 box (x, y, w, h)
- Evaluation metric: Intersection over union
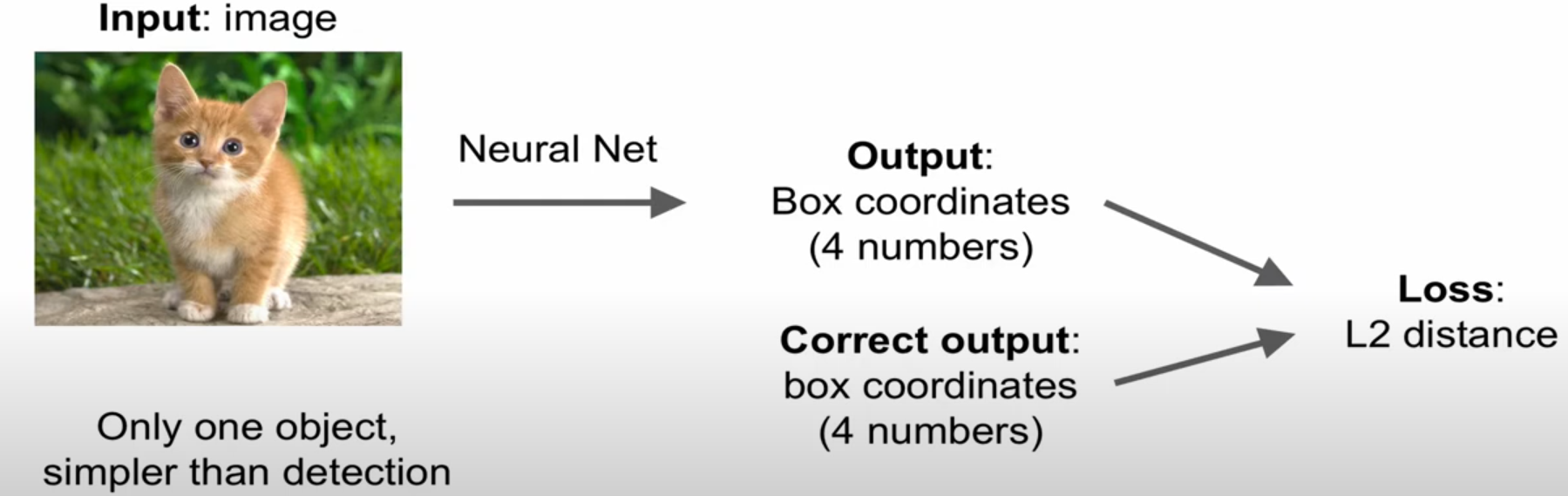
input으로 사진을 넣으면 output으로 4개의 좌표 숫자로 출력되고 correct output과 loss를 비교한 후 backward를 이용해 최적화 한다.
Overfeat
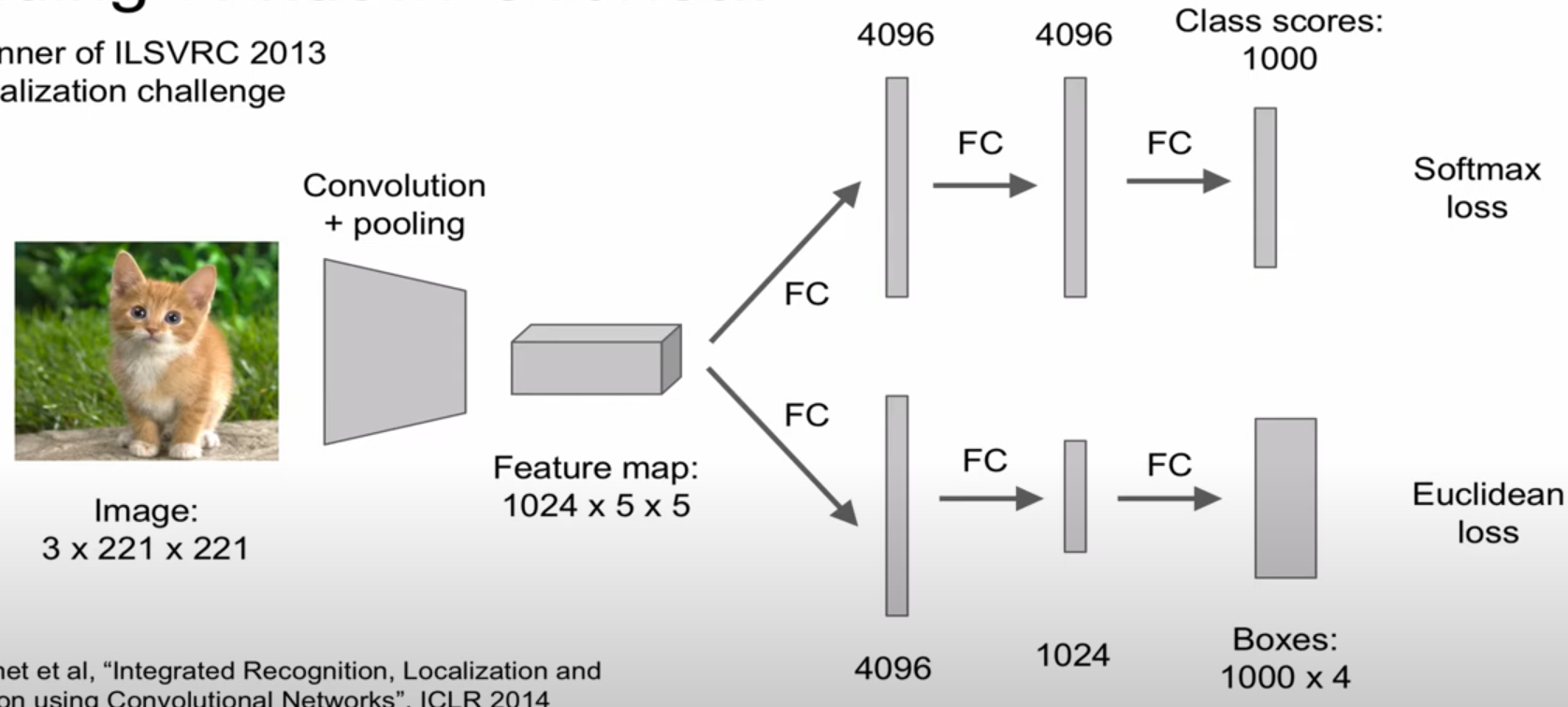
classifier head와 regression head로 구성
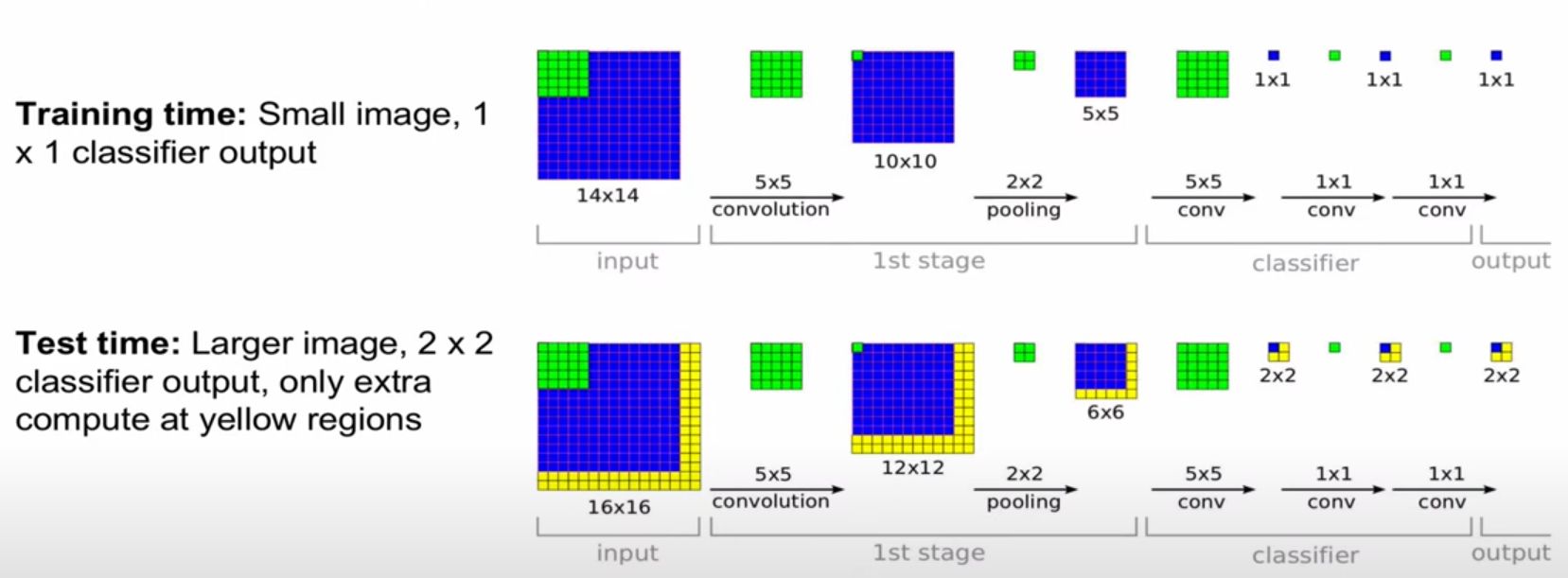
이는 bounding box를 이동 시키면서 결과를 출력한다.

수많이 돌리면 연산이 많아서 힘들어진다.
-> fully-connected layer을 convolution layer로 변환
Object Detection
이미지에 따라 output의 개수가 달라진다.
-> regression이 적당하지 않음
Classification 방식으로 Detection을 접근 할 당시 문제점
문제 1
다양한 크기의 window들을 이용해 많은 위치와 scales을 이용해야 한다.
해결
그럼에도 불구하고 그냥 해라
문제 2
CNN와 같은 무거운 classifier를 써야 할때 heavy한 연산이 된다.
해결
전 지역을 보지 말고 의심되는 지역만 보자
ex. Region Proposals
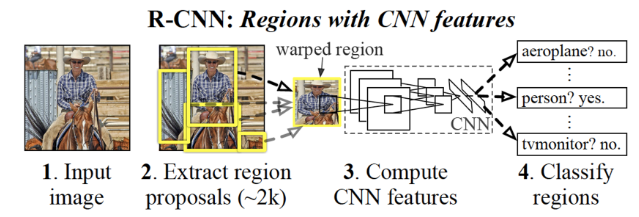
R-CNN
설정한 Region을 CNN의 입력값으로 활용해 Object Detection을 수행함
- Region Proposal
- (pre-trained) CNN
- SVM
- Bounding Box Regression
순으로 진행된다.
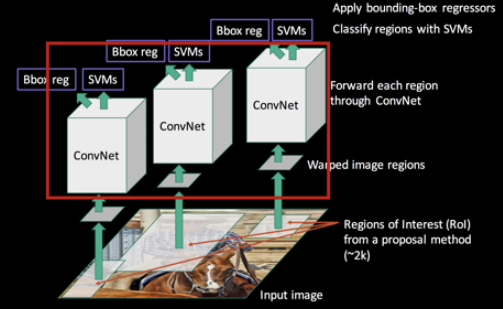
1. Region Proposal
R-CNN에서는 일반적으로 이미지 데이터를 주면 레이블러 정답 Bounding Box를 주게 된다.
R-CNN은 이미지 데이터를 입력 받아 물체를 인지하고 분류하는 Bounding Box를 잘 찾는것이 목익이 되는데, 이때 Selective Search 알고리즘을 이용해 임의의 Bounding Box를 설정한다.
2. CNN
CNN은 input 값의 크기가 고정되어 있기 때문에 이들을 모두 CNN에 넣기 위해 여러 사이즈로 나온 Bounding Box들을 같은 사이즈로 통일 시키는 작업을 거친다.
3. SVM
CNN 모델로부터 feature가 추출이 되고 Training label이 적용되고 나면 linear SVM을 이용해 classification을 진행한다.
4. Bounding Box Regression
Bounding Box Regression은 처음에 y로 줬던 label과, CNN을 통과해 나온 Bounding Box의 차이를 구해 차이를 줄이도록 저정하는 선형회귀 모델 절차이다.
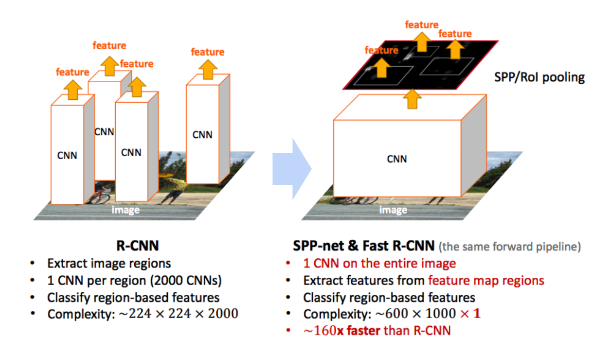
Fast R-CNN
기존 R-CNN 모델은 학습 시간잉 매우 오래 걸리고, detection 속도도 이미지 한 장당 47초 가량 걸려 매우 느린 속도를 나타냈다.
fast R-CNN은 이미지 1장의 입력을 받아 고정된 크기의 feacture vector를 fully connected layer에 전달한다.
Faster R-CNN
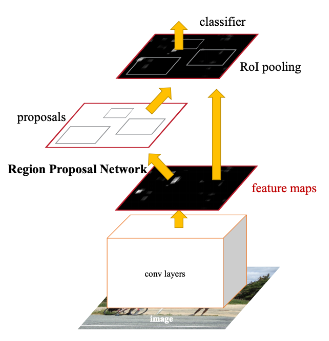
1. 원본 이미지를 pre-trained된 CNN 모델에 입력해 feature map을 얻는다.
2. feature map은 Region Proposal Network(RPN)에 전달해 적절한 region proposals을 산출한다.
3. 1과 2을 통해 얻느 feature map을 통해 Rol pooling을 수행해 고정된 크기의 feature map을 얻는다.
YOLO
fater R-CNN보단 빠른데, 정확도는 떨어진다.
YOLO의 특징은 다음과 같다.
1. 이미지 전체를 한번만 본다.
2. 통합된 모델을 사용해 간단하다.
3. 기존의 모델보다 빠른 성능으로 실시간 객체 검출이 가능하다.
