
1. Introduction
가. Neural Network?
인공 신경망(Artificial Neural Network)은 사람의 감각 기관에서 받아들인 정보가 다수의 뉴런을 단계적으로 통과하여 뇌로 전달되고, 뇌가 이를 처리하여 명령을 내리는 과정을 모방한 알고리즘 또는 구조이다.
일반적으로 여러 개의 층(layer)으로 구성되며, 입력층(input layer) → 은닉층(hidden layer) → 출력층(output layer) 순으로 신호가 전달된다.
나. 학습(Training) vs. 추론(Inference)
① 학습(Training)
-
입력층에 학습 데이터를 인가하고, 네트워크가 계산한 출력값과 주어진 레이블(label)의 차이를 손실 함수(loss function)로 계산한다.
-
이 손실 값을 바탕으로, 경사 하강법 등을 통해 가중치(weight)와 편향(bias) 등의 매개변수를 업데이트하는 과정을 학습이라 한다.
② 추론(Inference)
-
학습이 완료된 네트워크에 시험(test) 데이터를 입력하면, 출력값을 계산하여 주어진 레이블과 비교하지 않고 오직 예측 결과만을 확인한다.
-
보통 실서비스 환경에서는 레이블 없이 순전파 결과만을 활용하여 분류나 예측을 수행하며, 이를 추론 과정이라고 한다.
2. MNIST 데이터셋(Remind)
가. 데이터 구성: 이미지 및 레이블
-
MNIST 데이터셋은 손으로 쓴 숫자 이미지와 그에 대응하는 레이블(label)로 구성
-
각 이미지는 28×28 픽셀(총 784 개)의 흑백으로 표현되며, 픽셀당 밝기값은 0에서 255 사이 정수로 저장됨
-
레이블은 0부터 9까지 총 10 개의 숫자 클래스 중 하나를 나타냄
나. 학습용 Vs. 테스트용 분리
-
전체 데이터 중 60,000 개는 학습용(training)으로 사용되고, 10,000 개는 모델 성능 평가를 위한 테스트용(test)으로 분리되어 있음
-
학습용 데이터로 가중치와 편향을 최적화한 뒤, 테스트용 데이터로 과적합 여부 및 일반화 성능 확인
3. 신경망 구조 및 주요 파라미터
가. 입력층과 출력층의 노드 수
-
입력 노드 수: 해결하려는 머신러닝 문제의 입력 특징(feature) 차원에 따라 자동 결정
-
출력 노드 수: 분류하려는 클래스(class) 수에 따라 자동 결정
-
예시 (MNIST 숫자 인식)
- 입력층 노드 수: 28×28 = 784
- 출력층 노드 수: 10 (0–9 숫자 클래스)
나. 은닉층(Hidden Layer) 수 및 노드 수 결정
-
은닉층의 수 및 각 은닉층 내 노드 수는 정형화된 공식 없이 주로 경험적(heuristic) 방식으로 결정
-
고려 사항
- 모델 용량과 과적합(overfitting) 방지 사이의 균형
- 데이터 복잡도 및 학습 시간
- 교차 검증(cross-validation)을 통한 구조 탐색
-
예시: MNIST 숫자 인식 3층 신경망
- 은닉층 수: 2
- 은닉층1 노드 수: 50
- 은닉층2 노드 수: 100
4. 활성화 함수(Activation Function)
가. Sigmoid 함수
-
주로 이진 분류(binary classification)에서 사용
-
입력값 를 과 사이의 값으로 매핑
-
수식:
-
미분(역전파) 시 간소화된 표현:
나. Softmax 함수
-
다중 클래스 분류(multi-class classification)에서 사용
-
각 클래스 에 대한 점수 를 확률 분포로 변환
-
수식:
-
출력값의 합이 1이 되어, 각 클래스에 대한 확률로 해석 가능
다. Sigmoid vs. Softmax 비교
① 차원성
- Sigmoid: 입력 하나당 하나의 출력 확률, 독립적으로 동작
- Softmax: 여러 클래스 점수를 한꺼번에 처리, 상호 배타적인 확률 분포 생성
② 용도
- Sigmoid: 이진 분류 또는 다중 이진 분류(one-vs-all)
- Softmax: 단일 다중 클래스 분류(single-label multi-class)
③ 출력 해석
- Sigmoid: 각 출력이 개별적인 확률(동시에 여러 클래스가 선택될 수 있음)
- Softmax: 전체 출력값이 1로 정규화된 확률 분포(가장 높은 값 하나를 선택)
5. 순전파(Forward Propagation)
가. 연산 흐름
- 주어진 입력값을 입력층에 대입하고, 왼쪽에서 오른쪽 방향으로 계산을 진행하여 최종 출력값을 계산하는 과정
나. Affine 계층(Linear Layer)
- affine(linear) 계층은 를 계산하는 계층을 의미
- 각 층의 선형 변환을 담당하며, 그 뒤에 활성화 함수를 적용해 비선형성 부여
6. 손실 함수(Loss Function)
가. Mean Squared Error(MSE)
-
네트워크 출력 와 정답 레이블 간 오차 제곱의 평균을 구하는 손실 함수
-
수식:
-
주로 회귀(regression) 문제에서 사용하며, 분류 문제에서는 오차가 크게 벌어질 때 페널티가 커지는 특성이 있음
나. Cross Entropy Loss(CEL)
-
예측 확률 분포 와 실제 분포(레이블의 one-hot 벡터) 사이의 거리(정보량)를 계산하는 손실 함수
-
수식:
-
다중 클래스 분류(multi-class classification)에서 softmax 출력과 함께 사용
-
레이블은 one-hot 인코딩 방식으로 표현(예: 숫자 레이블 → )
다. One-hot Encoding
-
범주형 클래스 레이블을 벡터 형태로 표현하는 방법
-
정답 클래스 위치에만 을, 나머지에는 을 할당
-
예: 실제 레이블이 ‘’일 때
-
다중 클래스 분류에서 Cross Entropy Loss 계산을 위해 필수적
라. Binary Cross Entropy Loss(BCEL)
-
이진 분류(binary classification)문제에서 사용되는 손실 함수
-
예측 확률 와 실제 레이블 사이의 차이를 계산
-
수식:
-
Sigmoid 출력과 함께 사용하며, 각 샘플별 손실 값을 평균을 내어 전체 손실을 구함
7. 최적화 기법(Optimization)
가. 경사 하강법(Gradient Descent)
① 개념
손실 함수(loss function)가 작아지는 방향으로 파라미터(가중치 )를 업데이트하는 가장 기본적인 최적화 방법
② 업데이트 수식
여기서 는 학습률(learning rate), 는 손실 함수에 대한 가중치의 기울기(편미분)이다.
나. 확률적 경사 하강법(Stochastic Gradient Descent, SGD)
① 개념
전체 학습 데이터가 아니라 각 샘플(또는 미니배치) 별로 기울기를 계산하여 파라미터를 더 자주(샘플 단위로) 업데이트함으로써 계산 효율을 높인 방법
② 변형
-
미니배치 경사 하강법(Mini-Batch GD): 배치 크기 인 경우
-
배치 경사 하강법(Batch GD): 배치 크기 인 경우
-
SGD: 배치 크기 인 경우
다. 학습률(Learning Rate)
① 정의
가중치 업데이트 시 한 번에 움직이는 보폭(step size)을 결정하는 하이퍼파라미터
② 특성
- 너무 작으면, 손실 함수 최저점으로 수렴하는 속도가 느려지고, 국소적 최저점에 갇힐 위험 有
- 너무 크면, 발산하여 최저점에 수렴하지 못할 가능성 高
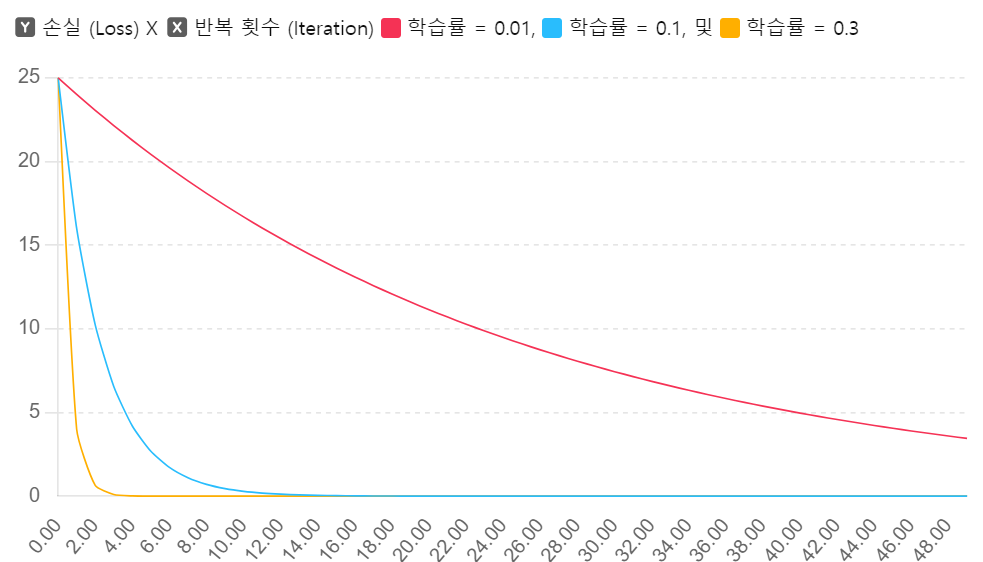
③ 설정 방법
교차 검증(cross‐validation)이나 스케줄링(learning rate decay), 적응형 기법(예: Adam, RMSProp) 등을 활용해 최적값을 찾는다.
8. Back Propagation
가. Vs. Numerical Differentiation
① Numerical Differentiation
-
매개 변수 하나하나에 대하여
와 같이 편미분을 계산
-
매개 변수 개수가 수백~수조 개에 이르는 대형 신경망에서 모든 파라미터에 대해 이 연산을 수행하면 연산량이 기하급수적으로 증가하여 매우 비효율적
② Back Propagation
-
계산 그래프를 따라 한 번의 순전파 결과와 국소적 미분 값(local gradient)만으로, 모든 파라미터에 대한 기울기를 한 번에 효율적으로 계산
-
chain rule을 활용하여 상류(upstream)에서 내려온 오차 신호에 국소 미분값을 곱하는 방식으로, 전체 네트워크의 기울기를 빠르게 구할 수 있음
나. 계산 그래프(Computational Graph)
① 정의
-
계산 과정을 노드(node)와 에지(edge)로 표현한 방향성 그래프
-
노드: 연산(, , 활성화 등) 표시
-
에지: 데이터(변수 값, 파라미터) 흐름 표시
-
역전파 과정: 순전파와 반대 방향으로 그래프를 탐색하며, 각 노드에서 상류로부터 전달된 오차 신호에 노드의 국소 미분을 곱해 기울기를 전파
다. 역전파 예제
① 곱셈 노드
-
순전파:
-
역전파:
② 덧셈/곱셈 노드
-
덧셈 연산
- 순전파:
- 역전파:
- 순전파:
-
곱셈 연산
- 순전파:
- 역전파:
- 순전파:
③ 복합 계산 그래프
-
예:
- 순전파
- 역전파
- 순전파
-
단계별로 체인 룰을 적용하여 한번의 그래프 역방향 탐색으로 모든 기울기를 구함
9. Activation Layer 별 역전파
가. ReLU Layer
- 순전파
- 역전파
나. Sigmoid Layer
- 순전파
- 역전파
10. Softmax + Cross Entropy 구현
가. 순전파 구현
- 입력 벡터 에 대해 각 클래스 출력 를 확률로 변환
(수치 안정화를 위해 보통 를 빼고 계산)
- 이후 정답 레이블의 one-hot 벡터 을 이용해 손실 을 계산
나. 역전파 구현
-
Cross Entropy Loss를 취한 후 softmax 출력에 대한 기울기 은
-
즉, 출력층에서의 오차 신호 를 바로 다음 은닉층으로 전파하면 됨
다. 간소화 버전
-
순전파에서 Softmax 계산과 Cross Entropy Loss 계산을 따로 나누지 않고 한 번에 처리하도록 만든 계층
-
순전파:
① 입력 에 대해 Softmax로 확률 계산
② 바로 그 결과로 Cross Entropy Loss 계산 -
역전파:
여기서
- : Softmax 출력 확률
- : 정답의 one-hot 레이블 (0 또는 1)
- : 한 번에 처리한 배치(batch) 크기
이 한 줄의 식이 의미하는 바는, Softmax 출력 와 레이블 의 차이 를 배치 전체의 평균으로 구하기 위해 으로 나눈다는 것이다.
배치 크기로 나누는 이유는, mini-batch 학습 시, 각 샘플에 대한 기울기를 모두 합산한 뒤, 다시 평균을 내서 학습률과 무관하게 안정적으로 업데이트하도록 하기 위함이다.
11. 배치 처리(Batch Processing)
가. 배치 크기(Batch Size)와 효율성
-
배치 처리는 여러 개의 입력 데이터를 묶어서 한꺼번에 연산하는 방식이다.
-
대부분의 수치 계산 라이브러리들은 작은 배열을 하나씩 여러 번 처리하는 것보다, 여러 개의 배열을 한꺼번에 처리할 때 훨씬 효율적으로 동작하도록 최적화되어 있다.
-
배치 크기(BS)
- 한 번의 순전파·역전파에 사용되는 샘플 수
- 일반적으로 형태(예: , , 등)로 설정
- 너무 작으면 연산 오버헤드가 커지고, 너무 크면 메모리 부족 및 일반화 성능 저하 우려
나. Epoch 개념
-
전체 학습 데이터 수를 이라 할 때, 배치 수는 가 된다.
-
Epoch는 “전체 학습 데이터를 한 번 모두 사용”한 단위를 의미한다.
- 예: , 이라면 한 Epoch당 100 번의 배치 업데이트 성립
-
일반적으로 여러 Epoch에 걸쳐 반복 학습을 수행하며, Epoch 수가 지나치게 많으면 과적합(overfitting) 위험이 있다.
12. 3층 신경망 예제 리뷰
가. 네트워크 구조 예시
-
입력층 노드 수: 784 (28×28 픽셀)
-
은닉층1 노드 수: 50
-
은닉층2 노드 수: 100
-
출력층 노드 수: 10 (0–9 숫자 클래스)
나. 순전파·역전파 흐름 정리
1) Forward Propagation
① 1차 은닉층
② 2차 은닉층
③ 출력층
④ 손실 계산
2) Back Propagation
① 출력층 오차
② 출력층 기울기
③ 2차 은닉층 오차
④ 2차 은닉층 기울기
⑤ 1차 은닉층 오차
⑥ 1차 은닉층 기울기
⑦ 파라미터 업데이트
계산된 기울기를 사용해 경사 하강법으로 , 업데이트 수행
<참고 자료>
유성욱 교수님, 지능형 영상처리, 중앙대학교 전자전기공학부, 2024
