
1. Introduction
인공신경망(Artificial Neural Network)은 인간 뇌의 뉴런 연결 구조를 모방한 머신러닝 모델로, 입력층–은닉층–출력층으로 구성된다. 각 뉴런(node)은 이전 층에서 전달된 값에 가중치(weight)와 편향(bias)을 적용해 선형 결합한 뒤, 비선형 활성화 함수(activation function)를 통해 출력을 생성하고 다음 층으로 전달한다.
이렇게 다층 구조를 통해 입력 데이터의 복잡한 패턴을 점진적으로 추출하고 학습할 수 있으며, 학습 과정에서는 오차 역전파(backpropagation)와 경사 하강법(gradient descent)을 활용해 가중치를 최적화한다.
이러한 특성 덕분에 인공신경망은 이미지 분류, 자연어 처리, 음성 인식 등 다양한 분야에서 뛰어난 성능을 발휘하며, 충분한 은닉 유닛을 갖춘 경우 임의의 연속함수도 근사할 수 있는 universal approximator로 인정받고 있다.
2. MNIST Dataset

MNIST는 美 국립표준기술연구소(NIST)가 제공한 손글씨 숫자 데이터셋을 변형한 버전이다. 0부터 9까지로 구성된 10 개 클래스를 포함한 흑백 이미지로, 각 이미지는 28×28 픽셀(총 784 개)이며 픽셀 값은 0(흰색)에서 255(검은색) 사이의 정수로 표현된다.
전체 70,000 개 샘플로 구성되며, 이 중 60,000 개를 학습용(training set), 10,000개를 시험용(test set)으로 사용한다.
3. 퍼셉트론
가. 단층 퍼셉트론 구조
1957년 Frank Rosenblatt가 제안한 단순한 신경망 모델로, 입력층(input)과 출력층(output), 단 두 개의 계층으로만 구성된다.
각 뉴런은 입력 벡터 와 가중치 벡터 의 내적에 편향(bias) 를 더해
형태로 선형 결합을 수행한 뒤, 계단 함수(step function)
을 적용하여 이진 출력을 만든다.
나. 퍼셉트론 학습 알고리즘
주어진 입력에 대한 예측 와 목표값 의 오차에 학습률 를 곱해 가중치와 편향을 갱신한다.
이 과정을 全 학습 데이터에 반복 적용하면서 올바른 결정 경계(decision boundary)를 찾아간다.
※ Decision Boundary?
Decision Boundary란 분류 모델이 서로 다른 클래스로 예측을 나누는 경계를 말한다.
다. 논리 게이트 구현 예시
① AND 게이트 예시
② OR 게이트 예시
③ NAND 게이트 예시
라. 단층 퍼셉트론의 한계
다음은 XOR 게이트 예시이다.
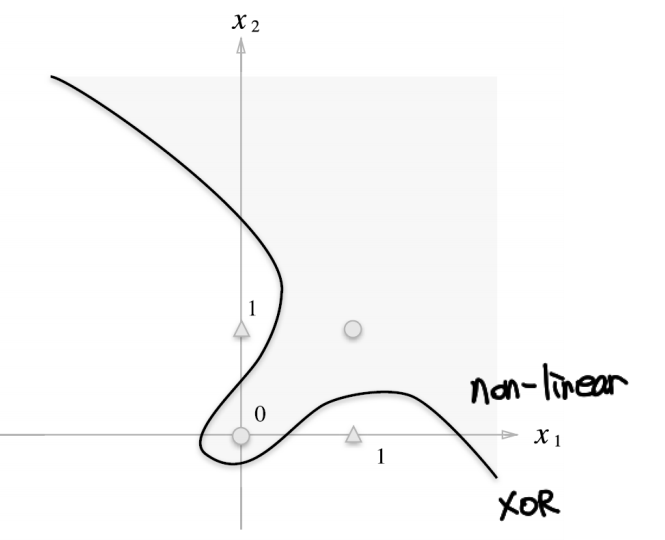
단층 퍼셉트론을 쓰면 XOR처럼 결정 경계가 곡선 또는 다중 곡면으로 나누어져야 하는 문제를 해결할 수 없다. 입력 공간을 하나의 초평면(hyperplane)으로만 분리하기 때문이다.
이러한 한계를 극복하기 위해 다층 퍼셉트론(MLP)가 도입되었다.
4. 다층 퍼셉트론(MLP)
가. 개념 및 구조
1) 정의 및 필요성
단층 퍼셉트론의 비선형 분리 한계를 극복하기 위해, 하나 이상의 은닉층(hidden layer)을 추가한 신경망 모델이다.
2) 구조
① 입력층(input layer): 원본 특성(feature) 벡터
② 은닉층(hidden layer):
각 은닉층 의 뉴런은 前 단계 출력
에 대해
형태로 선형 결합 후 비선형 활성화 함수 을 적용한다.
대표 활성화 함수로는 ReLU, Sigmoid, Tanh 등이 있다.
③ 출력층(output layer):
- 회귀: 항등 함수(identity)
- 이진 분류: Sigmoid
- 다중 클래스: Softmax
3) 학습(Backpropagation)
① 순전파(forward pass)로 출력 계산
② 손실 함수 로 오차 측정
③ 오차 역전파로 각 층의 가중치와 편향에 대한 그래디언트 계산
④ 경사 하강법 등으로
4) 장점
-
복잡한 비선형 함수 근사
-
특징을 단계적으로 추출하는 계층적 표현 학습
나. XOR 문제 해결하기
입력 에 대해 XOR은 , 만 로, 나머지는 으로 분류해야 한다. 2층의 MLP을 설계하면 다음과 같다.
- 은닉층: 2 개 뉴런, 활성화 함수 ReLU 또는 Sigmoid
- 출력층: 1 개 뉴런, Sigmoid
Sigmoid 사용 시, 가중치 예시는 다음과 같다.
- 은닉층
- 출력층
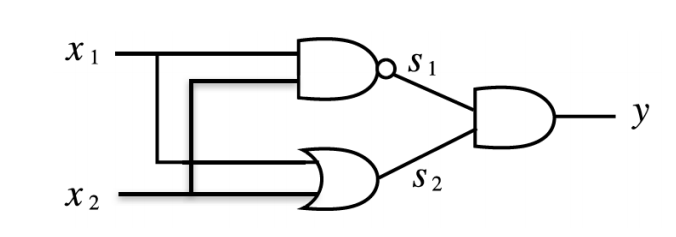
-
은닉 뉴런 1: , → OR 역할
-
은닉 뉴런 2: , → NAND 역할
-
출력층: , → 두 은닉 출력을 AND
5. 신경망 구성요소
가. 선형 계층(Linear Layer)
① 역할
입력 벡터에 대해 선형 변환(affine transform)을 수행하여 다음 계층에서 비선형 변환이 가능하도록 '기본 틀'을 제공한다.
② 구성 요소
-
입력:
-
가중치:
-
편향:
③ 수식
④ 특징
-
순수 선형 연산이므로 은닉층 없이 여러 개를 겹쳐도 표현력은 단일 계층과 동일하다.
-
비선형 활성화 함수와 결합되어야만 복잡한 패턴을 학습할 수 있다.
-
주로 입력 차원 변경, 특성 조합, 차원 축소/확장 등에 사용된다.
나. 활성화 계층(Activation Layer)
① 목적
선형 변환 후에 비선형성(non-linearity)을 추가하여, 네트워크가 복잡한 함수나 패턴을 학습할 수 있도록 한다.
② 대표 함수 및 수식
㉮ 계단 함수(Step function)
-
장점: 단순 이진 분류에 직관적
-
단점: 미분 不可 → 역전파 적용 不可
㉯ 시그모이드 함수(Sigmoid)
-
출력 범위:
-
장점: 확률 출력 해석 可
-
단점: 입력 절댓값 클 때 그래디언트 소실(vanishing gradient)
㉰ ReLU(Rectified Linear Unit)
-
장점: 계산 간단, 희소 활성화(sparse activation) 유도
-
단점: 음수 영역 뉴런이 영(死) 상태가 되는 “죽은 ReLU(Dead ReLU)” 문제
㉱ 쌍곡탄젠트 함수(Tanh)
-
출력 범위: (zero-centered)
-
장점: Sigmoid보다 빠른 수렴
-
단점: 여전히 큰 입력에 그래디언트 소실
다. 출력 계층 함수
① 이진 분류용 시그모이드(Sigmoid for Binary Classification)
-
출력:
-
해석: 출력값을 “클래스 1일 확률”로 볼 수 있다.
-
손실 함수(Binary Cross-Entropy):
② 다중 클래스용 소프트맥스(Softmax for Multi-class Classification)
- 출력: 개의 클래스 점수 벡터 에 대해
이때 는 클래스 일 확률이며 을 만족한다.
- 손실 함수(Categorical Cross-Entropy):여기서 는 one-hot 레이블 벡터이다.
6. 파라미터 결정 및 네트워크 설계
가. 입력층 및 출력층 노드 수 결정
① 입력층 노드 수: 주어진 입력 데이터의 특성 수에 따라 자동으로 결정
② 출력층 노드 수
-
회귀 문제: 예측하려는 값의 차원에 맞춰 결정 (예: 스칼라 회귀 → 1개 노드)
-
분류 문제: 클래스 수에 따라 결정 (예: 10개 클래스 → 10개 노드)
나. 은닉층 수와 노드 수 결정
① 문제 복잡도 대응
-
데이터의 패턴이 단순하면 은닉층 1 ~ 2 개, 복잡하면 3 개 이상 고려
-
과도한 깊이는 학습 시간 증가·그래디언트 소실 위험
② 노드 수(폭, width) 설정
-
각 은닉층 노드 수는 입력 차원 과 출력 차원 사이에서 결정
-
일반적 규칙:
-
경험적 가이드: 첫 은닉층은 입력 특성 수의 1~3 배로 시작해보고, 층이 깊어질수록 점차 노드 수를 줄이며 추상화 수준 높여보기
③ 과적합 Vs. 과소적합 균형
-
노드 수·층 수가 과하면 과적합 발생 → 검증 손실 상승
-
너무 적으면 모델 용량 부족 → 학습 손실·검증 손실 모두 높음
-
해결책: 교차검증(cross-validation), 학습 곡선 분석
④ 탐색 방법
-
그리드 탐색(Grid Search): 미리 정의한 후보 (depth, width) 조합 전수 시험
-
랜덤 탐색(Random Search): 설정 범위 내 무작위 샘플로 효율적 탐색
-
베이지안 최적화(Bayesian Optimization): 이전 평가 결과를 이용해 다음 후보 제안
-
AutoML 도구 활용
⑤ 계산 자원 고려
-
층·노드가 늘어날수록 파라미터 수 증가
-
GPU 메모리, 학습 속도, 배포 환경 제약 반영
다. 3층 신경망 설계 예제
① 아키텍처
-
입력층: 2개 노드
-
은닉층1: 3개 노드 (ReLU)
-
은닉층2: 2개 노드 (ReLU)
-
출력층: 2개 노드 (Softmax)
② 파라미터 수 계산
- 총 파라미터:
③ 순전파(forward pass) 흐름
- 은닉층1:
- 은닉층2:
- 출력층:
<참고 자료>
유성욱 교수님, 지능형 영상처리, 중앙대학교 전자전기공학부, 2024
