머신러닝 알고리즘 나이브 베이즈 (Naive Bayes)를 사용하기 위해서는 일단 베이즈 정리(Bayes' Theorem)라는 걸 먼저 이해해야 한다. 본 포스팅에서는 베이즈 정리의 개념만 최대한 쉽고 단순하게 설명해본다.
베이즈 정리(Bayes' Theorem)는 새로운 사건의 확률을 계산하기 전에 이미 일어난 사건을 고려하는 것을 전제로 하는 베이즈(혹은 베이지안) 통계의 근간이라 할 수 있다.
뭔가 말이 어렵긴 한데 그냥 고등학교 때 배웠던 독립 사건과 조건부 확률을 떠올리면 된다. 아래 공식이 뭔가 익숙하지 않은가
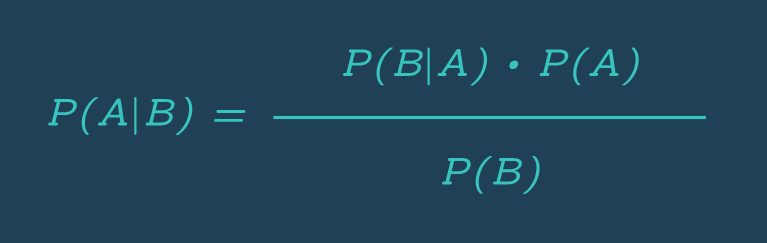
영국의 수학자 앨런 튜링(Alan Turing)은 이 베이즈 정리를 활용해서 2차 세계대전 독일의 애니그마(Enigma) 암호를 풀어냈다고 한다.
아무튼 베이즈 정리는 머신러닝, 통계적 모델링, A/B 테스트, 로보틱스(로봇공학) 등에서 널리 사용되고 있으니 이번 기회에 반드시 이해하고 넘어가는 게 좋겠다.
우선 베이즈 정리를 이해하기 위한 개념들을 하나씩 살펴보자.
독립 사건(Independent Events)
두 사건이 독립적인지 결정하는 건 통계에서 매우 중요하다.
사건이 독립적이라는 건 어떤 사건이 발생하더라도 그게 다른 사건의 발생 확률에 영향을 미치지 않는다는 뜻이다.
예를 들면 동전 던지기 같은 거. 한 번 던져서 앞면이 나왔다고 해서 다시 던질 때 앞면이 나올 확률이 줄어드는 게 아니기 때문이다.
조건부 확률(Conditional Probability)
조건부 확률(conditional probability)은 어떤 사건 B가 발생했을 때 사건 A가 발생할 확률을 의미한다.
만약 두 사건이 서로 독립적이라면 그냥 각각의 사건이 발생할 확률을 곱하면 끝이다. 이렇게
P(A∩B) = P(A) × P(B)
여기서 P는 확률, ∩ 기호는 'and'의 의미다
만약 주사위 2개를 던져 모두 6이 나올 확률을 구하면.. 각각의 주사위에서 6이 나올 확률은 1/6이고 서로 아무런 영향을 주고 받지 않으니까 그냥 1/6 × 1/6 으로 구하면 된다. 그런데 이건 지극히 빈도주의적(Frequentist) 관점에서의 확률 계산이다. 주사위를 던져 6이 나올 확률을 구할 때 애초에 6번 던지면 1번 꼴로 나오니까.. 그걸 보고 확률을 구한 거다.
그러나 아예 다르게 접근할 수도 있다. 이전에 다른 사건이 발생했다는 전제 하에 확률을 계산하는 베이지안(Bayesian) 관점으로.
예를 들어보자.
희귀병
만약 어떤 환자가 10만명 중 1명 꼴로 발생하는 희귀병이 의심되어서, 진단 정확도 99%의 검사를 받았고, 그 결과 희귀병으로 진단이 내려졌다고 하자. 이 때 그 환자가 정말로 희귀병일 확률은 어떻게 될까?
빈도주의적 관점에서는 일반적인 희귀병 발병률이 10만분의 1이고 검사의 정확도는 99%니까 1/100000 × 0.99로 계산해서 이 환자가 정말 희귀병을 가지고 있을 확률이 0.0000099라고 결론을 내린다.
그러나 베이지안 관점에서는 조건부 확률로 계산해야 한다. 희귀병 검사 결과가 양성인데, 정말 그러한지 확인하는 관점이다.
P(A|B) = ( P(B|A) × P(A) ) / P(B)
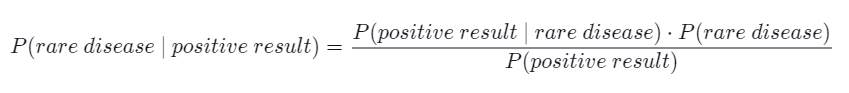
여기서 분모는 '검사 결과가 양성'인 경우니까, 두 가지 경우를 생각해서 그 확률을 더해야 한다.
- 환자가 희귀병을 가지고 있고, 검사 결과가 양성인 경우 : (1/100000) * 0.99 = 0.0000099
- 환자가 희귀병을 가지고 있지 않은데, 검사 결과가 양성인 경우 : (99999/100000) * 0.01 = 0.0099999
0.0000099 + 0.0099999 = 0.0100098가 나온다.
분자는 희귀병 환자에 대한 검사 정확도(0.99)와 희귀병 발병률(1/100000)을 곱해주면 된다.
아무튼 이렇게 구한 값은 약 0.0009890으로, 단순히 검사 정확도와 발병률을 곱한 값인 0.0000099보다 높다.
다른 예시도 보자.
스팸 필터
이번엔 "OO"이라는 단어가 메일에 포함되어 있을 때, 그 메일이 spam일 확률을 구하는 거다 (spam의 반대는 ham)
-
"OO"이라는 단어는 ham에서 0.1% 정도 등장한다.
-
"OO"이라는 단어는 spam에서 5% 정도 등장한다.
-
전체 메일의 20%는 spam이다. (80%는 ham이다.)
내가 받은 메일에서 "OO"이라는 단어를 발견했다. 이 메일이 spam일 확률은?
그러면 여기서 분모는 "OO"이 포함된 메일을 받을 확률이다. 아래 두 경우를 더해주어야겠지.
-
spam에서 "OO"이 등장할 확률 : 0.2 * 0.05
-
ham에서 "OO"이 등장하라 확률 : 0.8 * 0.001
그리고 분자는 spam에서 "OO"이 등장할 확률(0.05)과 spam을 받을 확률(0.2)를 곱해주면 된다.
구해보니 92.6% 정도 된다.
이제 이걸 응용하면 머신러닝에서 널리 쓰이는 나이브 베이즈 분류기를 만들어볼 수 있다.
