나이브 베이즈 분류기(Naive Bayes Classifier)는 '베이즈 정리'를 활용하여 분류를 수행하는 머신러닝 지도학습 알고리즘이다. 특히 텍스트(문서)의 분류에 많이 사용되는데, 실제로 어떤 계산을 통해 분류하게 되는지 그 과정을 최대한 쉽게 소개해본다.
베이즈 정리
'베이즈 정리'에 대해서는 이 포스팅을 보자.
공식을 다시 살펴보자.

B라는 조건이 주어졌을 때 A의 확률을 구하는 거다.
그런데 여기서 만약 B를 데이터라고 생각하고, A를 레이블이라고 생각하면 일종의 분류기가 되는 셈이다.
B라는 데이터가 주어졌을 때 A라는 레이블로 분류될 확률을 계산하는 거니까.
본 포스팅에서는 어떤 쇼핑몰에 새로 작성된 리뷰를 읽고, 그게 긍정 리뷰인지 부정 리뷰인지 분류하는 예를 살펴보자. (텍스트를 분류하는 것이기 때문에 조금 생소할 수도 있다.)
"침대가 정말 부드럽다"라는 텍스트가 positive 리뷰인지 분류하려면 베이즈 정리를 바탕으로 계산한다.

이 식을 구성하는 것들을 하나씩 계산해보자.

P(positive)는 전체 리뷰 문서 중 긍정 리뷰의 비율이다. 간단하다.

P(review | positive)는 "침대가 정말 부드럽다"라는 review가 있을 때 이 텍스트를 구성하는 각 단어들이 positive 리뷰에서 등장할 확률을 의미한다.
그런데 이걸 찾으려면 일단 "각 단어들이 등장할 확률은 독립적이다"라는 가정을 해야 한다. 한 단어가 등장하는 게 다른 단어가 나타날 확률에 영향을 미치지 않는 뜻이다.
물론 실제 상황에서는 이럴 가능성이 매우 적으니까 엄밀히 말하면 옳은 가정은 아니다. 그런데 이런 무리한 가정에도 불구하고 나이브 베이즈가 매우 좋은 성능을 보이기 때문에 그냥 쓰는 거다. 그래서 나이브(naive)라는 표현을 붙여 놓은 거다. 순진한.. 뭔가 좀 투박하거나 어설픈..?
아무튼 그래서 이렇게 계산하면 된다.
P("침대가 정말 부드럽다" | positive) = P("침대가" | positive) ⋅ P("정말" | positive) ⋅ P("부드럽다" | positive)
각 단어가 positive 리뷰에서 등장할 확률을 곱해주는 거다.
예를 들어 P("침대가" | positive)는 positive 리뷰 데이터 세트 전체 단어 개수 중 "침대가"라는 단어 개수의 비율이 될 거다.
스무딩 (smoothing)
그러나 만약 "침대가"라는 단어가 긍정 리뷰 데이터 세트에서 한 번도 등장하지 않은 단어라면 어떻게 될까?
이 경우 P("침대가" | positive) 값은 0이 되기 때문에 P("이 침대는 정말 부드럽다" | positive)까지 0이 되어 버린다. 아주 희귀한(?) 단어나 오타 같은 게 있을 때 특히 문제다.
그래서 이 문제를 해결하기 위해 스무딩(smoothing)이라는 기술을 사용해야 한다. 뭐 별 건 아니다. 분자에는 1을 더하고 분모에는 N을 더해서 부드럽게(?) 만들어주는 거다. 여기서 N은 데이터 세트에 등장하는 고유한 단어 개수다.
아무튼 여기까지 하면 분자는 다 구할 줄 아는 거다.

이제 분모를 살펴보자.
P(review)는 사실 위에서 구한 P(review | positive)랑 똑같이 생각하면 된다. 리뷰 텍스트가 positive라고 가정하지 않는다는 차이만 있을 뿐이니까.
그리고 어차피 여기서는 positive 아니면 negative로 분류될 거라서, 각각의 레이블로 분류될 확률을 계산하고 비교하게 될 텐데.. 아래 식을 보면 알겠지만
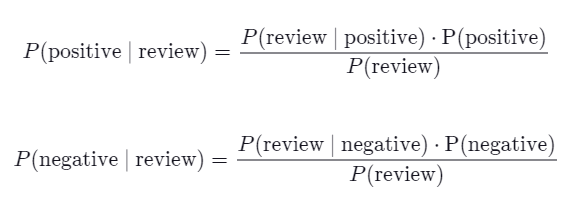

분모가 어차피 동일하다. 무시해도 된다는 얘기다
여기까지 계산 할 줄 알면 일단 원리는 다 이해한 셈이다.
출처
https://hleecaster.com/ml-naive-bayes-classifier-concept/
