비지도 학습(Unsupervised Learning)
정답을 따로 알려주지 않고(label이 없다), 비슷한 데이터들을 군집화 하는 것. 일종의 그룹핑 알고리즘.
라벨링 되어있지 않은 데이터로부터 패턴이나 형태를 찾아야 하기 때문에 지도학습보다는 조금 더 난이도가 있다.
실제로 지도 학습에서 적절한 피처를 찾아내기 위한 전처리 방법으로 비지도 학습을 이용하기도 한다.
대표적인 종류로는 클러스터링(Clustering), Dimentionality Reduction, Hidden Markov Model 등을 사용한다.

1. 군집화(clustering)
- 비지도 학습의 대표적인 기술로 x에 대한 레이블이 지정되어있지 않은 데이터를 그룹핑하는 분석 알고리즘
- 데이터들의 특성을 고려해 데이터 집단(클러스터)을 정의하고 데이터 집단의 대표할 수 있는 중심점을 찾는 것으로, 데이터 마이닝의 한 방법이다.
- 클러스터란 비슷한 특성을 가진 데이터들의 집단이다.
- 반대로 데이터의 특성이 다르면 다른 클러스터에 속해야 한다.
2. 군집(cluster)의 타당성 평가
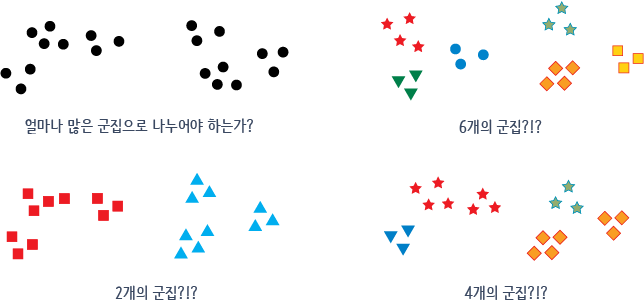
비지도 학습에 사용되는 데이터에는 레이블(label)이 없으므로, 지도 학습처럼 단순정확도(accuracy)를 지표로 그 정확도를 평가할 수는 없습니다.
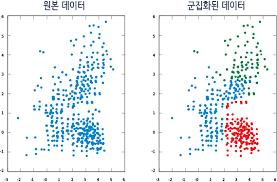
즉, 다음 그림과 같이 레이블이 없는 데이터 집합 내에서 최적의 군집 모양과 개수를 파악하기란 굉장히 어렵습니다.
군집을 만든 결과가 얼마만큼 타당한지는 군집간의 거리, 군집의 지름, 군집의 분산도 등을 종합적으로 고려하여 평가할 수 있습니다.
따라서 일반적으로 군집 간 분산(inter-cluster variance)이 최대가 되고 군집 내 분산(inner-cluster variance)이 최소가 될 때 최적의 군집 모양과 개수라고 판단하고 있습니다.
3. 군집화의 활용
- 의학 분야
- 특정 질병에 대한 공간 군집 분석을 통해 질병의 분포 면적과 확산 경로 등을 파악하는 역학 조사
- 홍보 분야
- 고객을 세분화할 때 군집화를 활용
- 통계 분야
- 분석하고자 하는 데이터에 다양한 군집화 알고리즘과 방법론을 사용하여 데이터 분석에 활용
출처
http://www.tcpschool.com
https://bangu4.tistory.com/96?category=904392
https://bangu4.tistory.com/98?category=904392

:]