
머신러닝의 분류
머신러닝은 학습하려는 문제 유형에 따라 크게 다음과 같은 세 가지로 분류할 수 있습니다.
- 지도 학습 (Supervised Learning)
- 비지도 학습 (Unsupervised Learning)
- 강화 학습 (Reinforcement Learning)
지도학습 (Supervised Learning)
정답을 알려주고 학습시키는 머신러닝의 학습 방법이다.
입력과 출력 데이터(훈련 데이터)가 있고 이를 모델화하여 새로운 데이터에 대해 정확한 출력을 예측하는 것
지도 학습에는 데이터에 대해 여러 개의 값 중 하나의 답을 도출해내는 분류(classification)와 데이터 분석을 통해 특징으로 답을 도출해내는 회귀(regression)의 방법이 있다.
먼저, 분류(classification)의 방법에서 문제와 정답을 학습한 기계는 데이터의 군집화를 통해 데이터가 속해있는 군집을 찾고 분류하여 해결한다.
회귀(regression)의 방법은 수치나 통계학적 방법으로 답을 도출해내는 방법이다.
1. 분류 (Classification)

-
예측하고자 하는 타겟값이 범주형 변수인 경우 이다.
-
예측 결과가 연속값이 아닌 이산값을 가지고 있다.
- 여기서 이산값이란, 0과1로 처리할 수 있는 값으로써 연속적이 아닌 단속적인 값을 뜻한다. -
부도 여부(yes/no), 여신 승인 여부, 동물 분류(dog/cat) 등을 예측할 수 있다. - 분류의 종류에는 이진분류와 다중분류가 있다.
-
즉, 예측 결과값이 이산값을 지니고 있는 경우 분류문제라고 할 수 있다.
예시
-
이진 분류
Q: 이 글은 스팸이야?
A: True / False 결과 -
다중 분류
Q: 이 동물은 뭐야?
A: 고양이 또는 사자 또는 강아지 등으로 분류된 결과
2. 회귀 (Regression)
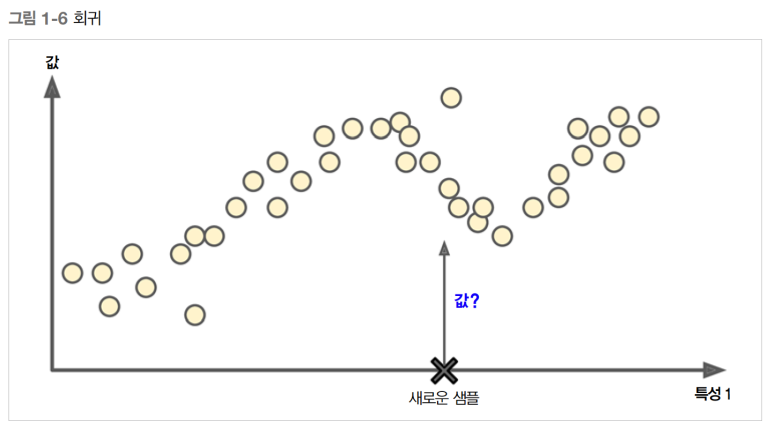
-
어떤 데이터들의 특징(feature)을 토대로 값을 예측하는 것.
-
종속변수가 수치형이다. (float 형태)
-
회귀를 통해 손해액, 매출량,거래량, 파산할 확률 등을 예측
-
즉, 예측 결괏값에 연속성이 있는 경우 회귀문제라고 할 수 있다.
예시
Q: 어디 동네에 어떤 평수 아파트면 집 값이 어느정도야?
A: 어디 동네에 24평이면 얼마, 어디 동네에 32평이면 얼마, 어디 동네에 45평이면 얼마입니다.
3. 분류와 회귀 구분하기
< text가 욕설인지 아닌지 예측하는 문제 >
분류
욕설 데이터와 욕설이 아닌 데이터를 수집하여 모델링하고, 각각의 class에 대한 확률을 예측
-- 이런 개xx xx하고 있네 - 욕설
-- 댓글 좀 달아주세요 - 정상
회귀 - 잘못된 모델링
- 욕설에 대한 데이터만을 수집하고, 입력이 욕설일 확률을 계산 (출력이 확률이므로 회귀라고 착각)
이것은 학습데이터에서 관측된 feature이들 입력 text에서 발견되면 score를 높여가는(실제로는 확률도 아니다) scoring 방법이다.
이 경우, 최종 score가 일정 범위 안으로 정규화 되기 힘들다.
- 입력의 다양성에 의해 최종 score가 얼마인지 알 수 없다 : 최대 최소 정규화(min-max normalization)를 할 수 없다
- 즉, 0~1 사이로 정규화할 수 없다
- 그런데 꾸역꾸역 여기에 sigmoid나, relu를 붙여 정규화를 했다 치자. (relu, sigmoid의 역할이 아닌데도..)
결국 score가 얼마 이상일 때, 이것을 욕설로 예측한다라는 한계점을 결정해야하는 문제가 남는다. (relu나 sigmoid에게 맡기려해도 최대값을 모르므로 어느정도가 1을 넘는지 알수 없다)
그리고 임의로 0.7점 이상이라면 욕설로 볼 수 있다라는 지극히 주관적이고 정성적인 판단을 한다. 여기에 평가셋을 붙여 90%이상의 정확도라고 말한다. 이렇게 "분류"를 한다고 말한다...
그러다가 학습데이터가 갑자기 늘어났다. 이제 0.7이라는 한계점 더 이상 사용할 수 없다.
회귀는 확률을 예측하는 것이 아니다.
회귀는 출력에 연속성이 있고, 그 연속성 중에 어디에 점을 찍을지 결정하는 문제이다.
확률은 사건들의 연속, 독립, 반복 등의 시행(trial) 따라 표본공간(sample space, 일어날 수 있는 모든 경우의 수) 속에서 사건(event)이 발생할 경우의 수를 구하는 문제이다.
해결해야할 문제를 정확히 인지하고, 어떤 데이터들을 수집하여, 어떻게 정제하야하는지 판단하고, 어떤 방법론(알고리즘)을 사용할지 선택하는 것이 Machine Learning을 하는 사람의 능력이다. 어려운 용어, 수학식을 들먹이며 이것으로 하자, 저것이 나으려나 고민하는 것이 Machine Learning을 하는 사람이 아니다.
참고 사이트
http://www.tcpschool.com
https://bangu4.tistory.com/96?category=904392
https://www.davincilabs.ai/wiki/?q=YToxOntzOjEyOiJrZXl3b3JkX3R5cGUiO3M6MzoiYWxsIjt9&bmode=view&idx=7709711&t=board
https://nexablue.tistory.com/29
