머신러닝 알고리즘은 문자열 데이터 속성을 입력받지 않으며 모든 데이터는 숫자형으로 표현되어야 한다.따라서 문자형 카테고리형 속성은 모두 숫자 값으로 변환/인코딩 되어야 한다.
scikit-learn을 사용한 변환 방식에는 대표적으로 2가지가 있다.
-
레이블 인코딩 (Label Encoding)
-
원-핫 인코딩(One-Hot Encoding)
이 두 가지의 차이점을 한눈에 살펴보면 다음과 같다.
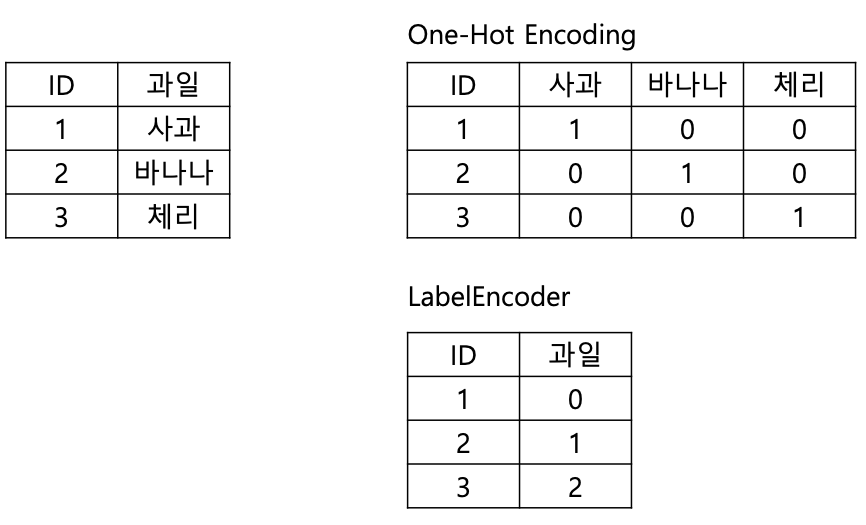
이제 자세히 하나씩 살펴보자.
레이블 인코딩 (Label Encoding)
Label Encoding은 feature의 유형에 따라 숫자를 부여한다.
수행 방법
from sklearn.preprocessing import LabelEncoder
items=['트와이스','BTS','레드벨벳','신화','GOD','GOD']
# LabelEncoder를 객체로 생성 -> fit() -> transform()
encoder = LabelEncoder()
encoder.fit(items)
labels = encoder.transform(items)
print('인코딩 변환값:',labels)결과값
[4, 0, 2, 3, 1, 1]레이블 인코딩의 문제점
-
일괄적인 숫자 값으로 변환되면서 예측 성능이 떨어질 수 있다.
-> 숫자의 크고 작음에 대한 특성이 작용 -
선형 회귀와 같은 ML 알고리즘에는 적용하지 않아야 함 (트리 계열의 ML알고리즘은 숫자의 이러한 특성을 반영하지 않으므로 괜찮음)
원-핫 인코딩 (One-Hot Encoding)
원-핫 인코딩은 feature의 유형에 따라 새로운 피처를 추가해 고유 값에 해당하는 칼럼에만 1을 표시하고 나머지 칼럼에는 0을 표시하는 방법이다.
scikit-learn에서 하는 방법과 pandas에서 하는 방법 두가지가 있다.
1. sklearn을 이용한 원-핫 인코딩
원-핫 인코딩을 하기 전에 레이블 인코딩을 먼저 해야한다.
from sklearn.preprocessing import OneHotEncoder
import numpy as np
items=['트와이스','BTS','레드벨벳','신화','GOD','GOD']
# 먼저 LabelEncoder로 변환
encoder = LabelEncoder()
encoder.fit(items)
labels = encoder.transform(items)
# 2차원 데이터로 변환
labels = labels.reshape(-1,1)
# 원-핫 인코딩을 적용
oh_encoder = OneHotEncoder()
oh_encoder.fit(labels)
oh_labels = oh_encoder.transform(labels)2. pd.get_dummies()
import pandas as pd
df = pd.DataFrame({'item':['트와이스','BTS','레드벨벳','신화','GOD','GOD'] })
# 원핫인코딩 실행
pd.get_dummies(df)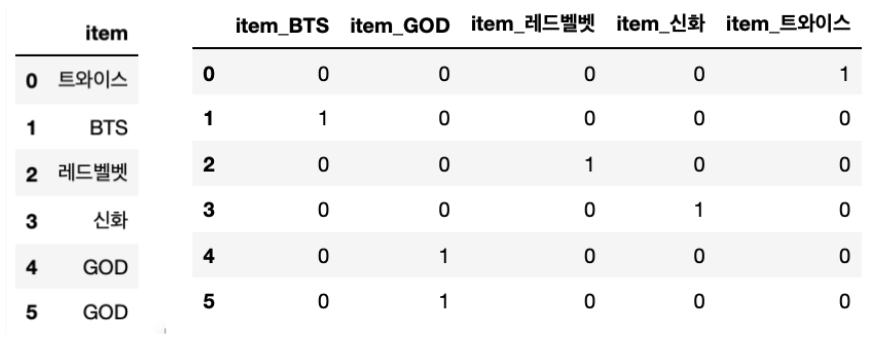

:]