강의복습 내용
Cross-Entropy
손실함수
−n1∑i=1n∑c=1CLiclog(Pic)
n: 데이터 개수
C: 범주 개수
L: 실제 데이터값
P: 실제 데이터값의 확률값
Entropy
H(q)=−∑c=1Cq(yc)log(q(yc))
Entropy는 불확실성이 더 커질수록 커지며 9:1 비율의 분포보다 5:5의 분포에서 더 커진다.
Cross Entropy
Hp(q)=−∑c=1Cq(yc)log(p(yc))
실제 분포인 q를 모를 때 모델링을 통해 이미 알고 있는 p의 분포를 통해서 q를 예측하는 것이다. 식에 p와 q가 모두 들어가기 때문에 cross-entropy라는 이름이 붙여졌다. 실제값과 예측값이 비슷해질수록 값이 작아지고 달라질수록 값이 커져서 실제값과 예측값의 차이를 줄일 때 사용을 한다.
Likelihood for Bernoulli Distribution
파라미터 π를 따르는 어떤 확률 분포를 f(Y;π)라고 할 때 y에 대한 베르누이 분포는 다음 식과 같다.
f(Y=y;π)=πy(1−π)1−y,y∈{0,1}
y를 고정 시키고 π에 대한 함수로 나타내면 가능도 함수가 된다.
L(π∣y)=∏i=1nf(yi;π),yi∈{0,1},i=1…n
Log Likelihood for Bernoulli Distribution
l(π∣y)=log(L(π∣y))=log(i=1∏nf(yi;π))=i=1∑nlog(f(yi;π))=i=1∑nlog(πyi(1−π)1−yi)=i=1∑n(yilog(π)+(1−yi)log(1−π))
베르누이 분포의 가능도에 log를 취하면 음의 Cross-Entropy 식이 나오게 된다.
과제 수행과정/결과 정리
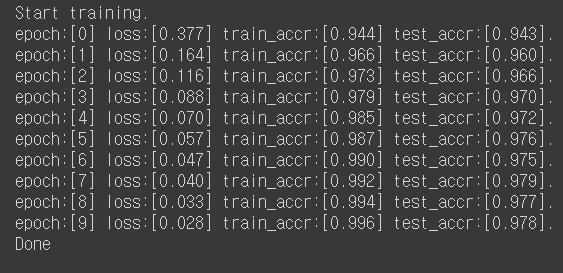
Accuracy가 강의와 비슷한 정도로 나왔고 과제에서 원하는대로 구현하였음을 알 수 있다.
피어세션 정리
○ 알고리즘
○ 2주차 강의 후기
엔트로피
강의 이해도 : 말로는 이해, 머리는 하얌
시각화 강의 : 양이 너무 많다.
선택과제가 너무 어려워 보인다.
https://github.com/KimDaeUng/PLM-Implementation
이 링크는 Transformer 기본 모델 코드로 선택과제의 Multi-head attention을 구현하는 부분은 비슷할 것이다.
강의에 자막이 있었으면 좋겠다.
→ 모바일로 들어가면된다?
타 프로그램과 부스트캠프의 차이
→ 부스트 캠프는 한국어 강의여서 매우 좋다.
학습회고
평소에 안다고 착각했던 내용들을 다시 한 번 짚어볼 수 있어서 좋았고, 시각화 강의가 조금 길긴했지만 기초적인 이론들을 배워서 좋았다.
