강의내용 복습
3. Optimization
Loss function의 값을 작게 만드는 hyperparameter를 구하는 과정이다.
Optimization
- Generalization
Training data를 통해 학습한 모델이 다른 외부 데이터에 대해서도 잘 동작하게 하는 것을 generalization이라고 한다. - Underfitting, Overfitting
- Cross-validation
- Bias-variance trade off
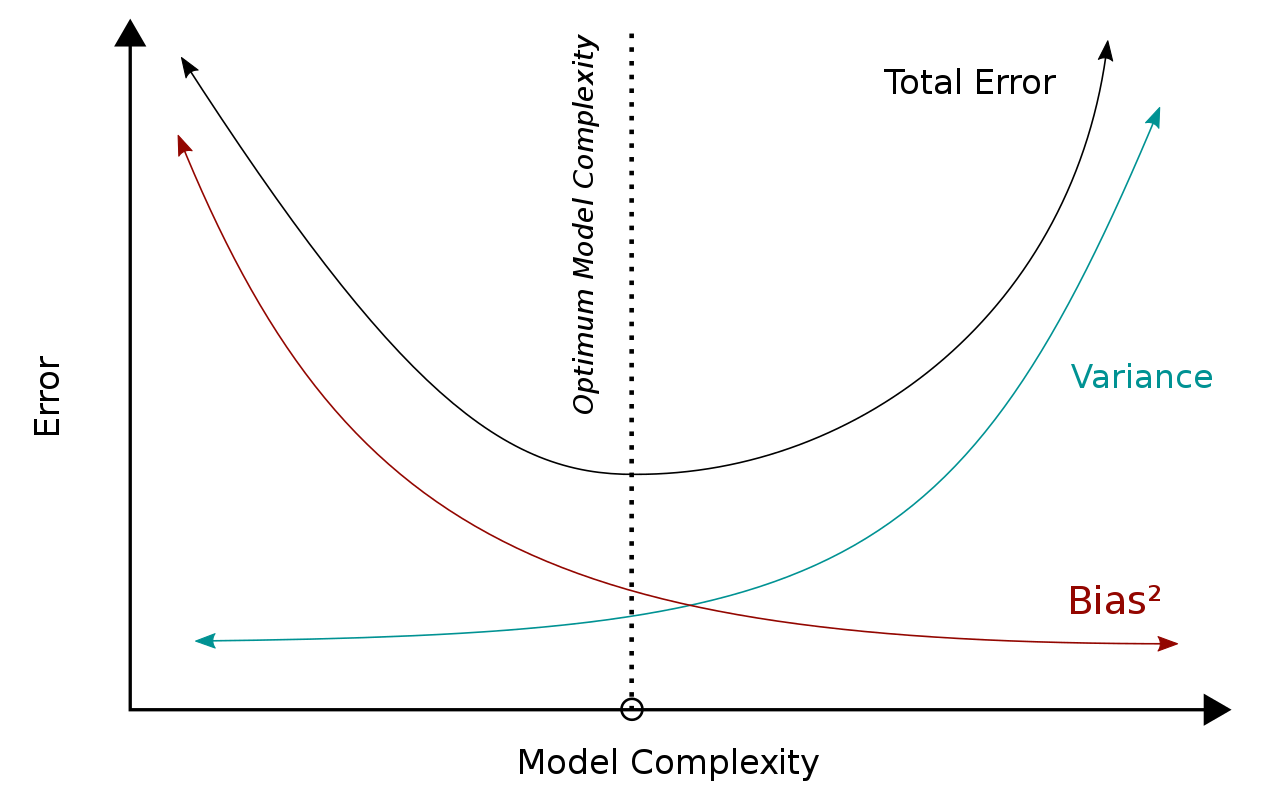
모델의 bias와 variance를 동시에 낮출 수 없어서 두 개의 합을 최대한 낮출 수 있는 지점을 찾는 것이 최선이다.
- Bootstraping
통계학에서의 bootstrap
가설 검증을 하거나 metric을 계산하기 전에 중복을 허용하여 random sampling을 적용하는 방법
ex) 전체의 80%만 random sampling을 적용해서 여러 번 반복한 후 평균을 구하는 것
ML에서의 bootstrap
traindata 내의 dataset 분포가 고르지 않을 때 사용한다. bootstrap을 통해서 적은 data의 수를 늘린다. bootstrap을 통해서 overfitting을 줄이는 작업을 bagging이라고 한다.
- Bagging and boosting
Bagging과 boosting 모두 ensemble 기법에 속한다. Ensemble 기법은 동일한 학습 알고리즘을 가지고 여러 모델들을 학습시키는 것이다. Weak learner 여러 개를 결합시킨 것이 single learner 하나보다 좋은 성능을 보인다는 원리이다.
Bagging(Bootstrapping aggregating): 샘플을 여러 번 뽑아 각 모델을 학습시켜 결과를 집계하는 방법이다. Bagging을 통해서 높은 bias로 인한 underfitting과 높은 variance로 인한 overfitting을 최소화할 수 있다.
Boosting: Bagging과 같이 중복 랜덤 샘플링을 시행하지만 가중치를 부여한다는 차이점이 있다. 오답에 대해 높은 가중치를 부여하고 정답인 것에 낮은 가중치를 부여해서 높은 가중치를 가진 답을 맞춘 모델을 선택한다. 오답을 잘 맞출 수 있다는 장점이 있지만 overfitting에는 취약한 모습을 보인다. 예시로 AdaBoost, XGBoost, GradientBoost가 있다.
Gradient Descent Methods
- Stochastic gradient descent
- Momentum
GD의 단점은 local minima를 잘 벗어나지 못한다는 것과 훈련이 느리다는 점이다. 이에 관성을 적용해서 원래 가던 방향에 속도를 더해주는 방법이다. 원하는 방향으로 이동 시 속도가 더해져서 더 빠른 학습이 가능해지고 관성 때문에 local minima를 벗어나기 쉬워진다.
- Nesterov accelerated gradient
- Adagrad (Adaptive gradient)
변수들을 update할 때 각각의 변수마다 step size를 다르게 설정해서 이동하는 방식이다. 자주 등장하거나 변화가 컸던 변수들의 step size를 작게 설정하고 변화가 적었던 변수들의 step size를 크게해서 loss값을 빠르게 줄이는 게 목표이다.
ex) Word2vec이나 GloVe와 같이 word representation을 학습시킬 경우 단어의 등장 확률이나 variable 사용 비율이 확연히 차이나기 때문에 Adagrad을 사용하면 효과적이다.
- Adadelta
- RMSprop
Adagrad에서 를 sum of gradient squares로 계산한 것이 아닌 gradient squares의 지수평균(EMA) 대체해서 가 무한정으로 커지지 않으면서 최근 변화량의 변수 간 상대적인 크기 차이는 유지할 수 있다.
- Adam
Momentum + RMSprop
Momentum과 유사하게 지금까지 계산해온 기울기의 지수평균을 저장하고 RMSprop과 유사하게 기울기의 제곱의 지수평균을 저장한다.
m과 v가 0으로 초기화되어 있어서 unbiased 해주는 작업을 추가한다.
Regularization
- Early Stopping
- Parameter norm penalty
- Data augmentation
- Noise robustness
- Label smoothing
- Drop out
- Batch normalization
과제 수행과정/ 결과정리
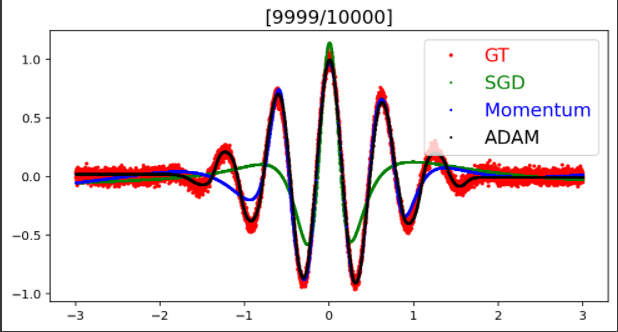
Adam optimizer의 성능이 10000 iteration에서 가장 좋았고 가장 빨리 optimizing 되었다. 그 다음으로는 Momentum의 최적화 성능이 좋았고 그 뒤를 SGD가 따랐다. Adam optimizer는 필요에 따라 학습률을 바꾸는 방법을 사용해서 가장 좋은 성능을 보였고 무엇을 사용해야할지 모르면 adam optimizer를 먼저 사용하는 것을 추천한다.
피어세션 정리
10일
모더레이터 : 김대웅
회의록: 한진
발표: 추창한, 한진
추창한 : 강의 리뷰 및 배운점 발표
한진 : Resnet과 ensemble의 상관관계 간단히 리뷰
각자 BoostCamp에서 NLP와 CV 선택한 이유
서울대 AI 여름학교 링크 공유
알고리즘이 취업에 미치는 영향
학습 회고
내용을 모르고 무작정 썼던 코드들에 대해서 더 잘 알게 되어서 좋았고 당연히 여기는 것 없이 모든 것들에 궁금증을 가져야겠다는 생각이 들었다.
