강의복습 내용
4. CNN
-
Number of parameters
(kernel_width x kernel_height) x input_channel x output_channel -
Dense Layer(Fully Connected Layer)
Parameter sharing이 발생해서 parameter 개수가 많음
점점 Fully Connected Layer를 줄여 나가는 추세 ( parameter 수가 많아지기 때문에) -
1x1 Convolution
Dimension reduction
Reduce the number of parameters while increasing the depth
5. Modern CNN
-
AlexNet
ReLU activation - overcome vanishing gradient
GPU Implementations (2 GPUs)
Data augmentation
Dropout -
VGGNet
Increasing depth with 3x3 convolution filters
3x3 convolution filter 2개를 적용한 것과 5x5 convolution filter를 하나 적용한 것은 receptive field 크기가 같지만 3x3 convolution filter의 parameter 수가 더 적다.
ex) 128 channel - 3x3 filter 2개: receptive field 5x5, parameter 수: 3x3x128x128x2 = 294912개
128 channel - 5x5 filter 1개: receptive field 5x5, parameter 수: 5x5x128x128 = 409600개 -
GoogLeNet
Inception block
Feature을 효율적으로 추출하기 위해서 1x1,3x3,5x5 convolution layer를 따로 계산해서 sparse한 network를 만든다. 하지만 그렇게 되면 연산량이 많아져서 1x1 convolution을 이용해서 dimension reduction을 한다. 결과적으로 parameter 개수가 줄어든다.
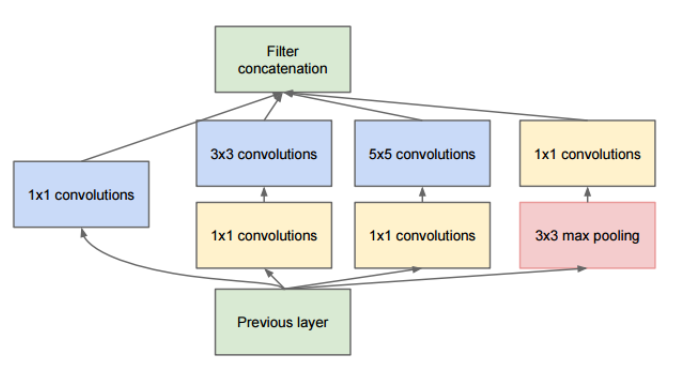
- ResNet
skip connection:
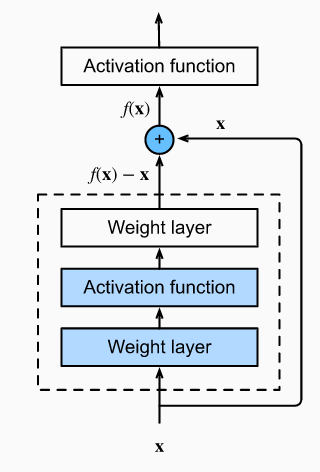
기존에 overfitting 문제로 layer가 더 깊은 network가 더 성능이 안 좋았는데, residual 구조로 인해서 layer를 더 많이 쌓았을 때 test 성능이 증가하게 되었다.
Bottleneck architecture
1x1 convolution layer를 앞 뒤로 붙여서 channel만 조절함
- DenseNet
ResNet에서 addition 부분을 concatenation으로 바꾼 모델
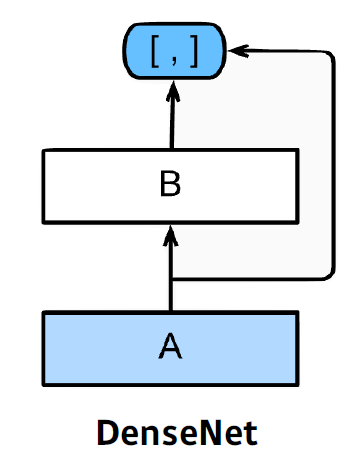
6. Computer Vision Applications
Semantic segmentation
- Fully Convolution Network
Dense Layer에서 진행하는 flat과 dense 과정을 convolution으로 바꾼 네트워크 - Deconvolution
Detection
- R-CNN
- SPPNet
- Fast R-CNN
- Faster R-CNN
Fast R-CNN + Region Proposal Network - YOLO
Extremely fast object detection
Simultaneously predicts multiple boundng boxes class probabilities
과제 수행과정 / 정리
피어세션 정리
추창한 : 강의 리뷰 및 배운점 발표
한진 : Resnet과 ensemble의 상관관계 간단히 리뷰
각자 BoostCamp에서 NLP와 CV 선택한 이유
서울대 AI 여름학교 링크 공유
알고리즘이 취업에 미치는 영향
학습 회고
전에는 그냥 network 이름과 특징들만 알아뒀었는데 왜 그런 구조를 가지게 되었는지 알게 되어서 어떤 요소가 모델의 성능을 더 향상시켰는지 말할 수 있을 것 같다.
