algorithm&data-structure
1.정렬 Sort (JAVA)
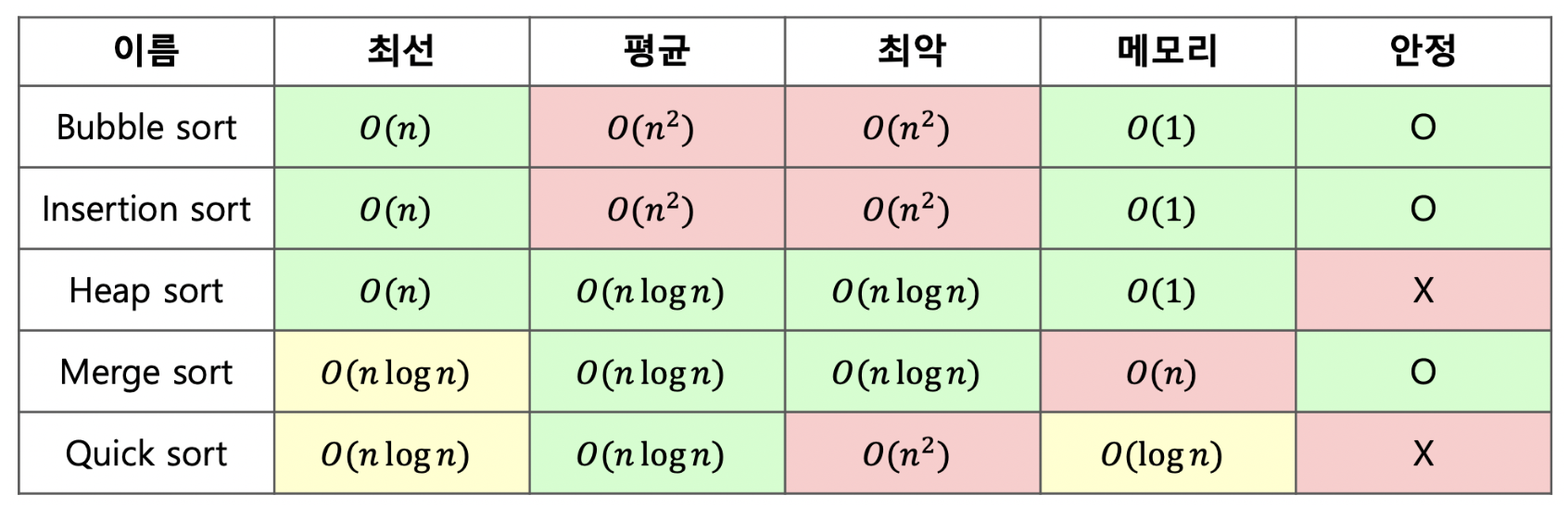
1. 버블 정렬 데이터의 인접 요소기리 비교하고, swap 연산을 수행하며 정렬하는 방식 시간 복잡도 : O(n2) 다른 정렬에 비해 느리다. 위와 같은 과정을 오름차순/내림차순으로 정렬될 때까지 반복한다. 2. 선택 정렬 대상에서 최대나 최소 데이터를 찾아가 선
2.시간복잡도 Time complexity

1. 시간 복잡도란 : 입력값의 변화에 따라 연산을 실행할 때, 연산 횟수에 비해 시간이 얼마만큼 걸리는지를 나타낸다. 수행시간은 1억번의 연산을 1초의 시간으로 간주하여 예측한다. (+) 시간복잡도 도출 기준 상수는 시간 복잡도 계산에서 제외한다. 가장 많이 중첩된
3.그리디 Greedy
📍그리디 알고리즘 : greedy란 '탐욕스러운'이라는 뜻으로, 현재 상황에서 가장 좋은 것만 고르는 방법을 의미한다. 매순간 가장 좋아보이는 것을 선택하면 현재의 선택이 나중에 미칠 영향을 고려하지 않는다. 장점 : 동적 계획법보다 구현하기 쉽고 시간 복잡도가 좋다. 단점 : 항상 최적의 해를 보장하지 못한다. 위와 같다면 그리디는 5 -> 11...
4.동적 계획법 DP
📍 동적 계획법 DP 이란? : Dynamic Programming으로, 하나의 큰 문제를 작은 문제로 나누어 해결하는 방식이다. 공간복잡도를 늘리는 대신, 시간복잡도는 줄이는 방식이다. 1. DP 문제 조건 최적 부분 구조(Optimal Substructure) : 상위 문제를 하위 문제로 나눌 수 있으며, 하위 문제의 답을 모아서 상위 문제를 해...
5.너비우선탐색 BFS (JAVA)
📍 BFS란? : Breadth-First Search(너비우선탐색)으로, 루트 노드(혹은 다른 임의의 노드)에서 시작해서 인접한 노드를 먼저 탐색한다. -> 두 노드 사이의 최단 경로 혹은 임의의 경로를 찾고 싶을 때 사용한다. 1. BFS vs DFS (1
6.깊이우선탐색 DFS (JAVA)
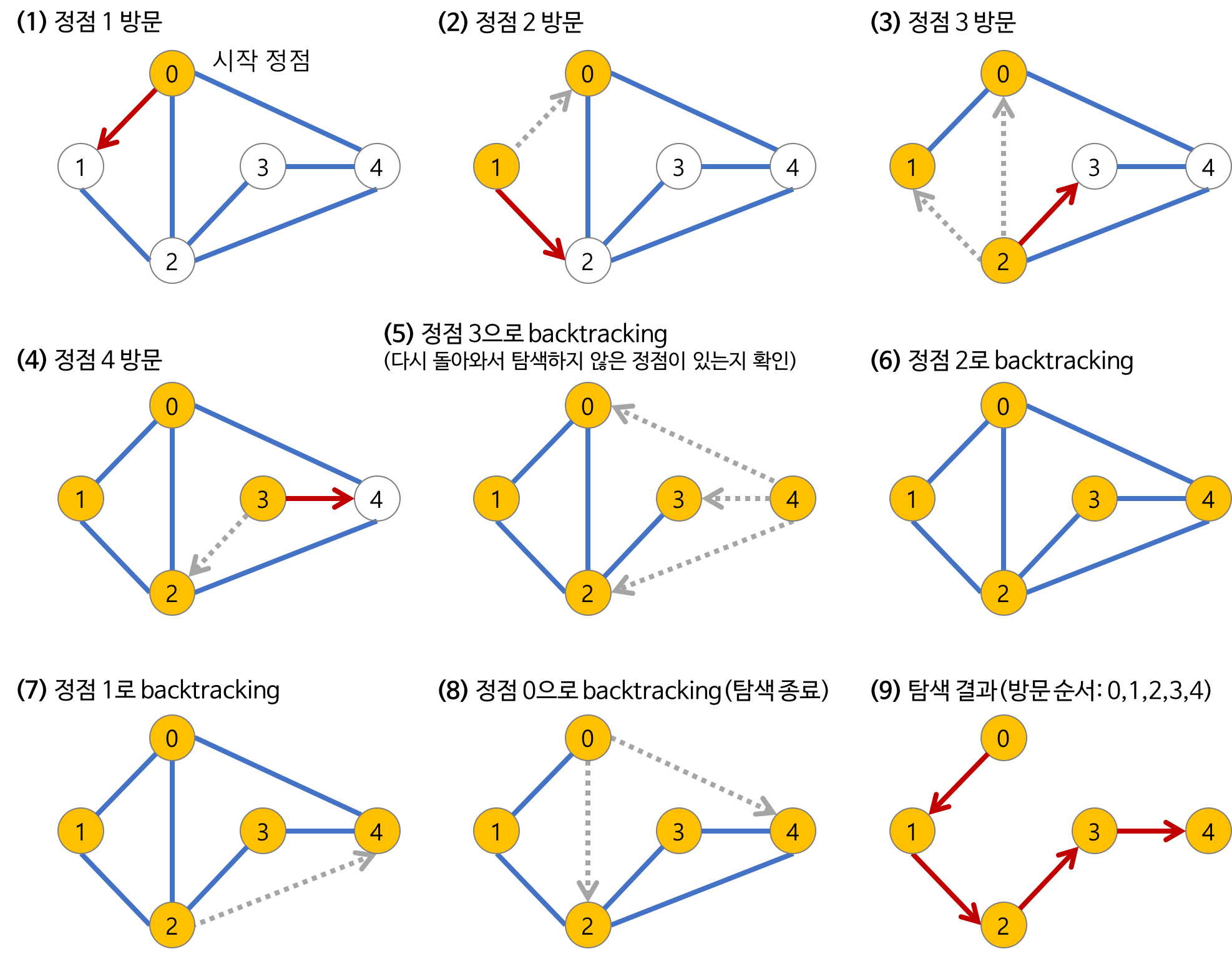
📍 DFS란? : Depth-First Search(깊이우선탐색)으로, 루트 노드(혹은 다른 임의의 노드)에서 시작해서 가능한 한 깊게 탐색한 후 더 이상 탐색할 수 없을 경우 이전 노드로 되돌아가서 다음 경로를 탐색한다. -> 모든 노드를 탐색할 때 사용한다.
7.분할정복을 이용한 거듭제곱 (JAVA)
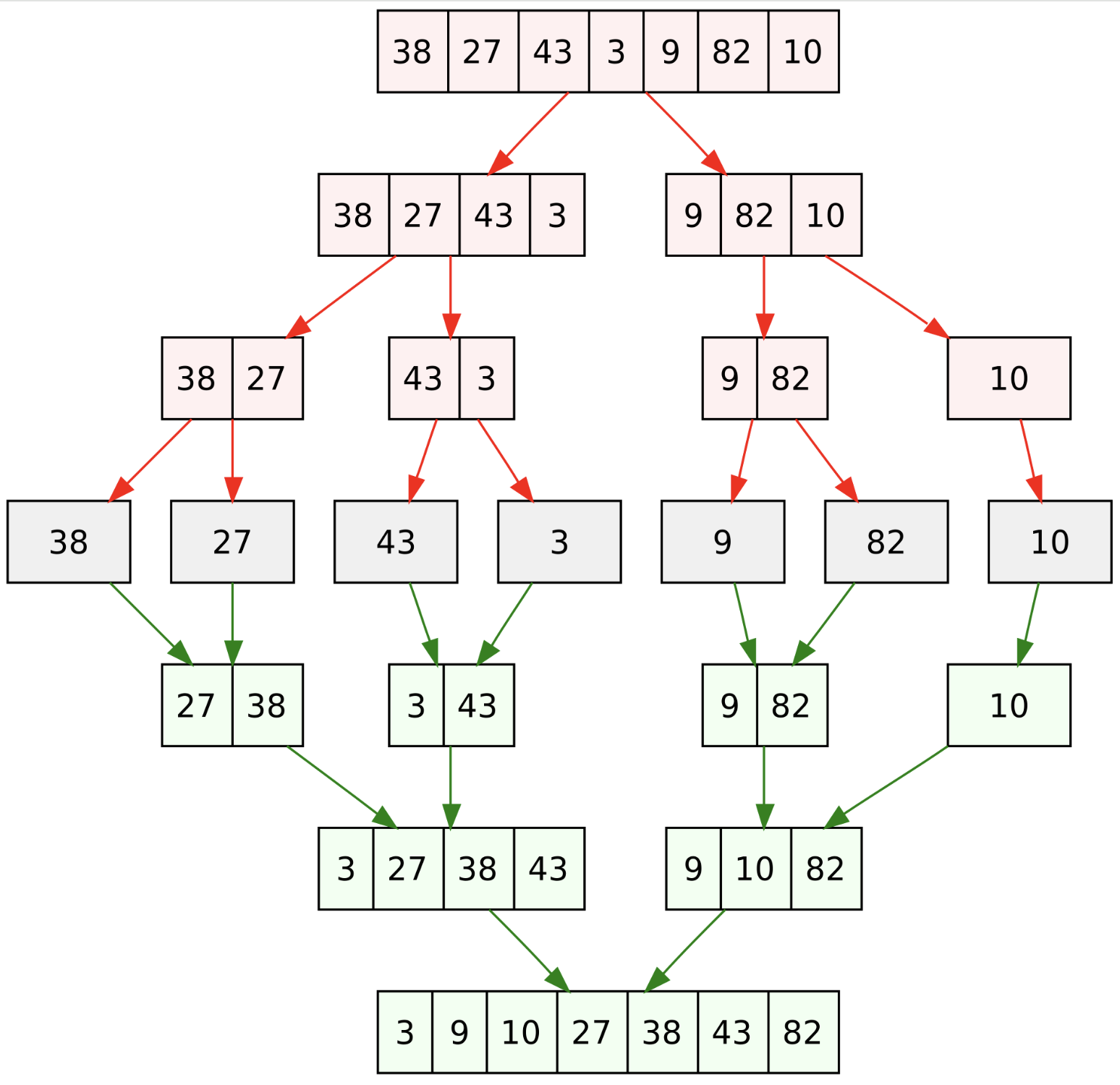
📍 분할 정복을 이용한 거듭제곱 : 큰 수의 거듭제곱을 계산할 때 호율적으로 계산하기 위해서 사용되는 알고리즘이다. 1. 분할 정복(Divide and Conquer) 이란 ? : 큰 문제를 더 이상 쪼갤 수 없이 작은 문제로 나눠 풀 다음 다시 그 문제들을 합
8.백트래킹, 퇴각검색 Back Tracking
📍Back Tracking 백트래킹, 퇴각검색 이란? : 탐색 알고리즘 중 하나로, 문제의 해답을 찾는 동안 모든 가능한 경로를 탐색하면서 해답에 도달하는 과정을 나타낸다. 어떤 경로가 해답이 될 가능성이 없다고 판단되면 되돌아가서 다른 경로를 탐색하는 방식으로 작
9.스택 STACK (JAVA)
📍 STACK 이란? 데이터를 쌓아 올린 형태의 자료구조이다. 데이터를 하나씩만 넣고 뺄 수 있다. 단방향 입출력 구조 : 데이터의 들어오는 방향과 나가는 방향이 같다. -> LIFO 후입선출이다. 1. 후입선출 : Last In, First Out (LIFO)로 나중에 삽입된 것이 먼저 삭제된다. (STACK 스택) 선입 선출 : First In...
10.모노톤 스택 Monotone Stack (JAVA)
📍 모노톤 스택이란? : 스택 변형된 형태이다. 모노톤은 단조(monotonic)에서 유래된 말로, 스택 내에 저장된 데이터들이 단조 증가 또는 단조 감소하는 성질을 가지도록 유지하는 자료 구조이다. 1. 모노톤 스택 종류 Monotonic Increasing Stack 모노톤 증가 스택 : 스택에 들어오는 각 데이터가 커지거나 같은 스택이다. 스택...
11.큐 QUEUE (JAVA)
📍 QUEUE 란? 데이터를 쌓는 형태의 자료구조이다. 데이터를 하나씩만 넣고 뺄 수 있다. 단방향 입출력 구조 : 한 쪽으로 데이터의 들어오고 반대 쪽으로 데이터가 나간다. -> FIFO 선입선출이다. Rear : 데이터가 들어오는 위치로 가장 뒤를 뜻한다. Front : 데이터가 나가는 위치로 가장 앞을 뜻한다. 1. 큐 메소드 offer(d...
12.특수한 형태의 큐 (JAVA)
📍 특수한 형태의 큐? 일반 큐에 관한 글은 https://velog.io/@hyong/data-structure-Queue 일반 큐는 FIFO(First-In, First-Out) 방식이다. 하지만 특정 요구사항에 따라 큐의 동작 방식을 변형하여 원형 큐 우선순
13.유니온 파인드 Union find (JAVA)
📍 유니온 파인드란? : 그래프/트리 알고리즘 중 하나로, 어떤 두 노드가 같은 집합에 있는지 확인하는 알고리즘이다. 서로소 집합(Disjoin-set)이라고도 한다. union(x, y) 연산과 find(x) 연산으로 이루어져 있다. 1. 두 개의 연산 Find: 주어진 요소가 속한 집합의 대표 노드(루트)를 찾는다. 이 연산을 통해 두 노드가 같...
14. 재귀 recursion (JAVA)
📍 재귀 알고리즘 이란? : 함수가 자기 자신을 다시 호출하여 문제를 해결하는 방법이다. 즉, 하향식 방식(top - down) 이다. 1. 재귀 구성 기저 조건(Base Case): 재귀 호출을 멈추는 조건이다. 재귀 호출(Recursive Call): 함수가 자기 자신을 다시 호출하여 문제를 점점 작게 만든다. 2. 장단점 (1) 장점 직관적이다...
15.HashMap, LinkedHashMap, TreeMap (JAVA)
📍 Map Map은 키-값 쌍을 저장하는 데이터 구조입니다. 각 키는 고유해야 하며, 키를 사용하여 해당하는 값을 빠르게 검색할 수 있습니다. Map은 키를 통해 값을 찾는 효율적인 방법을 제공하며, 데이터의 비순차적인 접근을 가능하게 합니다. 주요 특징 키-값
16.그래프 graph
그래프란? : 정점(vertex)를 간선(edge, link)로 연결한 형태의 자료구조이다. 트리도 그래프의 일종이지만 그래프는 사이클을 형성할 수 있고 이웃한 정점끼리 상하 관계를 갖지 않는다. 1. 그래프의 종류 (1) 연결/비연결 그래프 연결 그래프 : 그래프 상에 있는 임의의 두 정점 사이의 경로가 반드시 존재하는 그래프 비연결 그래프 : 어떤 정...
17.유클리드 호제법 Euclidean algorithm (JAVA)
📍 유클리드 호제법이란? : 두 수의 최대공약수를 구하는 알고리즘이다. > 두 양의 정수 a,b(a>b)에 대하여 a=bq+r(0≤r 1. 예시 예시로 12와 9의 최대공약수를 구하는 과정을 알아보자 (1) 12 = 9 × 1 + 3 여기서 12를 9로 나눈 몫 q는 1이고, 나머지 r는 3이다. a,b의 최대공약수는 b,r의 최대공약수와 같기 때...
18.에라토스테네스의 체 (JAVA)
📍 에라토스테네스의 체 란? : 소수를 찾는 빠르고 효율적인 방법이다. 특정 범위 내에서 소수를 찾을 때 O(N log log N) 의 시간 복잡도로 동작하여 매우 빠르다. 1. 단일 숫자 소수 여부 확인 시간 복잡도 : O(√N) 어떤 수 N이 소수인지 판별하려면, 1과 자기 자신을 제외한 다른 약수가 존재하는지 확인해야 한다. 하지만, 굳이 1부터...