
재표본추출 방법 (Resampling Methods)
: 훈련셋에서 반복적으로 표본을추출하고 각 표본에 관심있는 모델을 다시 적합하여 적합된 모델에 대해 추가적인 정보를 얻는것
- resampling의 필요성
-Model assessment : 테스트 에러율 평가
-Model selection : 적절한 flexibility 수준 선택
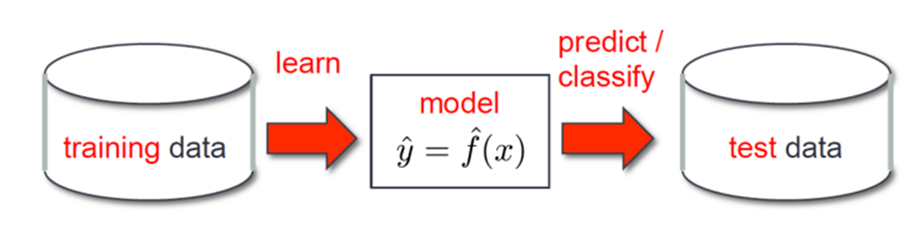
01. Training Error vs Test Error
- Test error : 새로운 데이터에 대한 모델의 예측값에 대한 평균 에러
- Training error : 학습에 사용된 데이터에 대한 에러
*Training error가 작아도 Test error는 클 수 있음
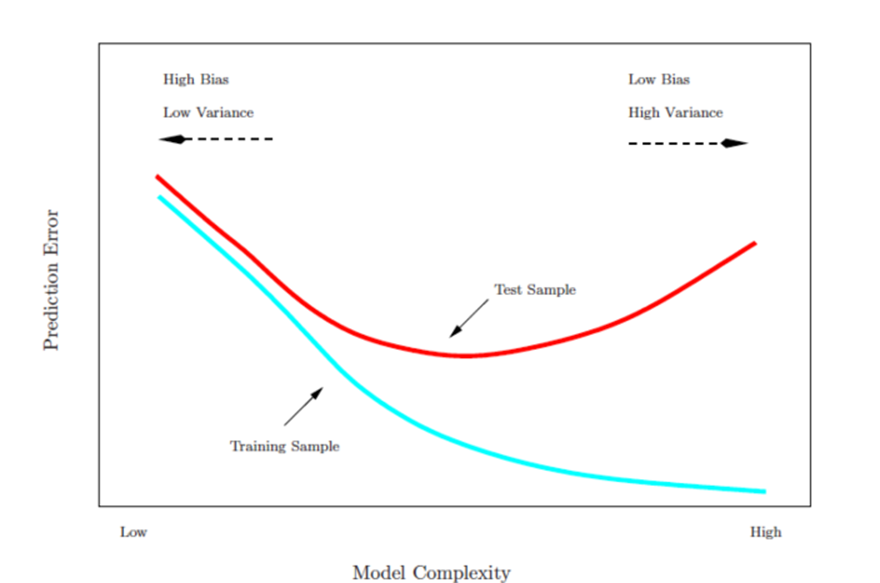
02. Prediction Error 평가
-
Best solution : 대규모 테스트 데이터 집합.
-
Test error rate을 평가하기 위해 training error rate을 수학적으로 조정하는 방법
ex) Cp statistic, AIC, BIC -
Resampling에서는 test error를 평가하기 위해 training data의 부분 집합을 남겨두고 해당 data에 다시 적용하는 기법
1. 교차 검증(Cross-validation)
STEP1 활용 가능한 data를 2개의 부분으로 나눔(Train, validation set)
STEP2 Training set을 활용해서 모델 만듬 -> 이 모델을 이용해 validation set 예측
STEP3 Validation set error을 이용해 test error 예측 (MSE, misclassificationr rate 측정)
01. Validation process
: 랜덤하게 둘로 나누어 왼쪽을 training set, 오른쪽을 validation set으로 정함
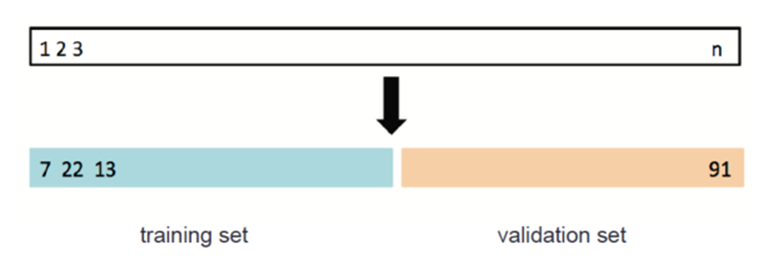
- Validation set 방법
-장점 : 간단하고 쉽게 구현 가능
-단점 : MSE 변화율 높음, 성능 낮아짐(일부분만 사용), test error를 과대평가하는 경향
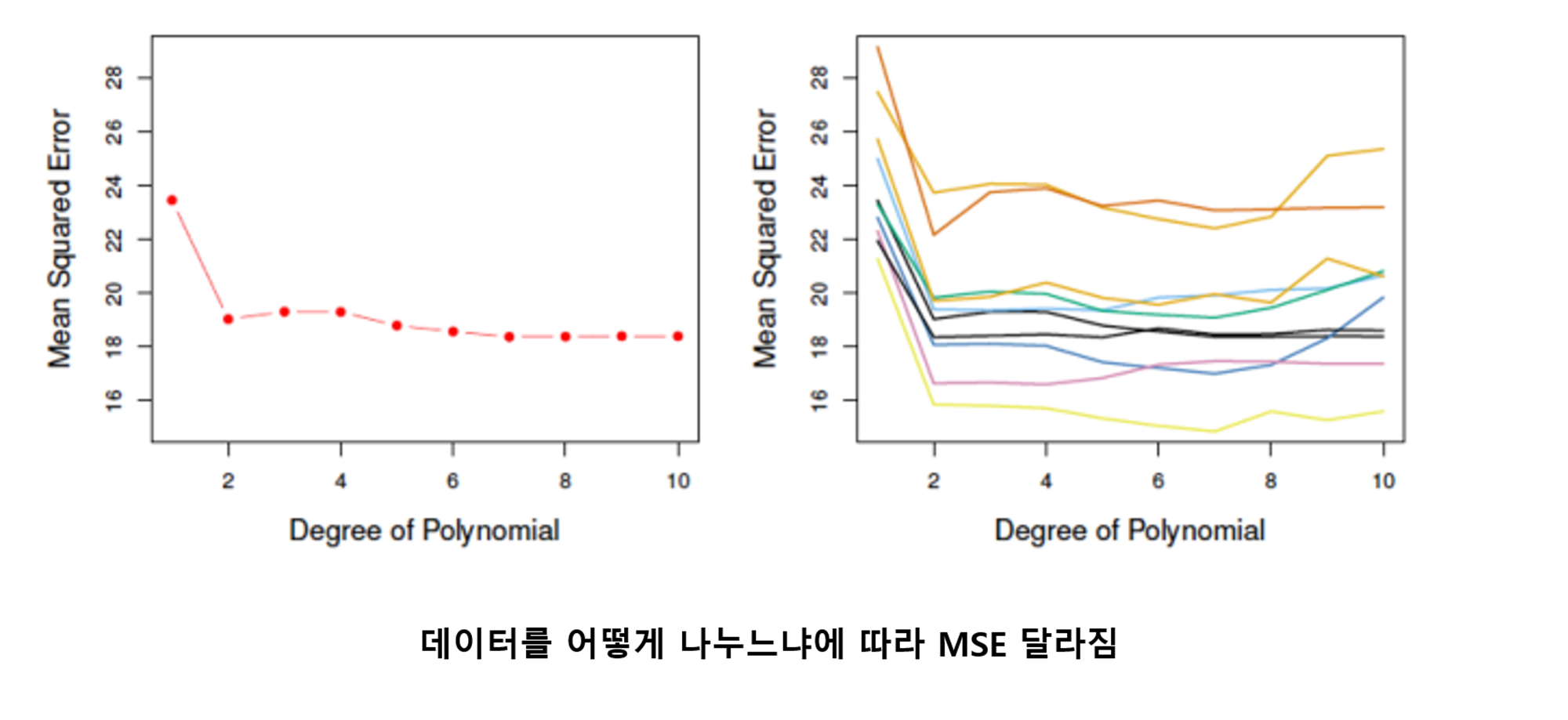
02. Automobile data
- Linear regression에서 Linear vs higher-order polynomial 비교
-mpg~horsepower
-mpg~horsepower+horsepower^2
-mpg~horsepower+horsepower^2+horsepower^3
-...
STEP1 랜덤하게 392개의 데이터를 각 196개의 training set과 validation set으로 나눔
STEP2 2개의 모델(linear vs higher-order) 학습
STEP3 MSE 측정
STEP4 10번 반복
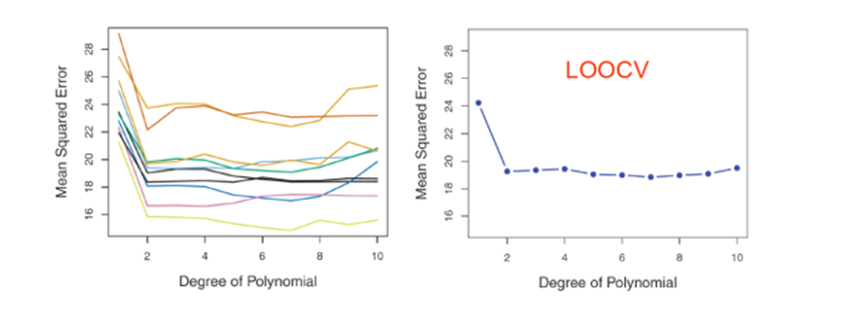
02. LOOCV(Leave-one-out Cross Validation)
: 교차 검증의 한 형태로, 모델의 성능을 평가하는 데 사용되는 방법
-training set : n-1개 -> 원래 방법보다는 큰 training data set
-Validation set : 1개
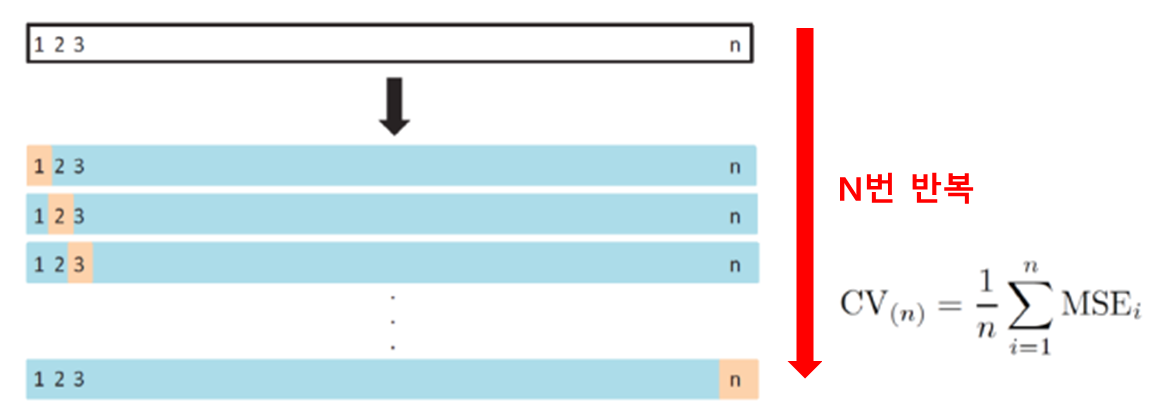
-장점 : 낮은 bias(거의 모든 data가 training에 사용), MSE 변화율 낮음
-단점 : 계산량이 많음
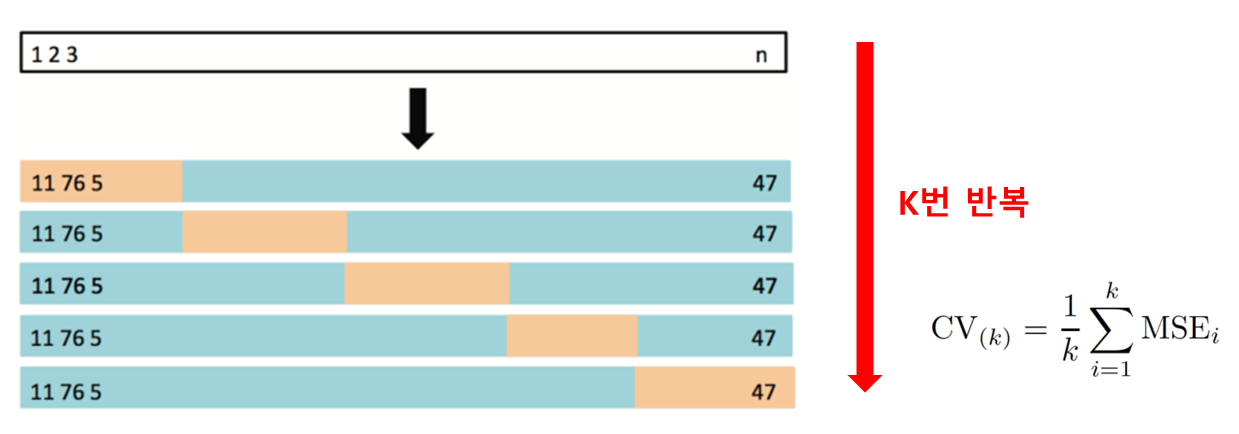
03. K-fold Cross Validation
: 데이터셋을 k개의 서로 다른 부분집합(폴드)으로 나누고, 각각의 폴드를 한 번씩 검증 데이터로 사용하고 나머지 폴드를 훈련 데이터로 사용하여 모델을 평가하는 방법
-CV/LOOCV 단점 해결
-가장 널리 사용되는 기법
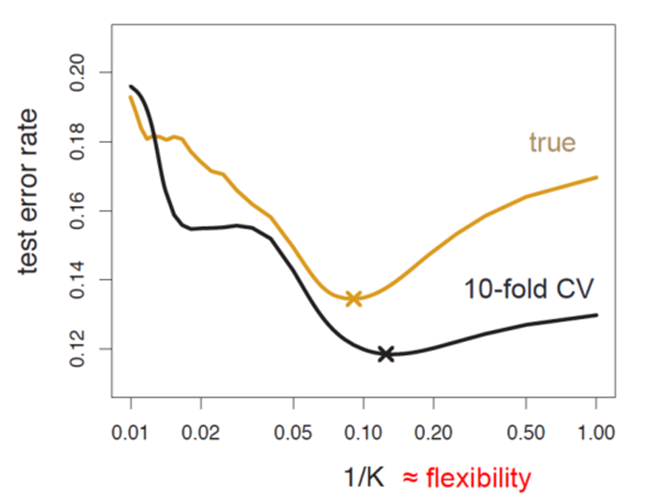
04. LOOCV vs K-fold CV (Auto Data)
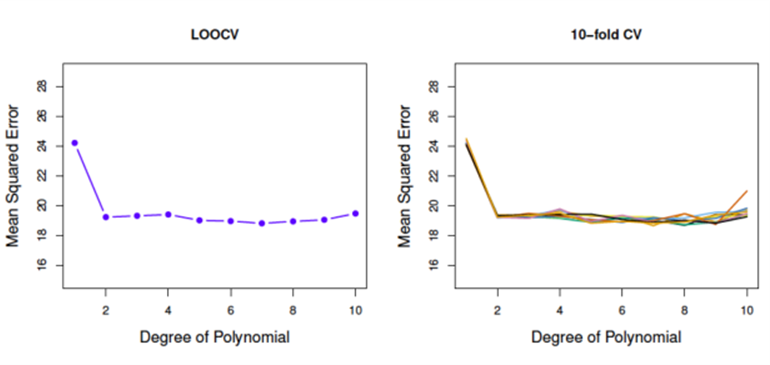
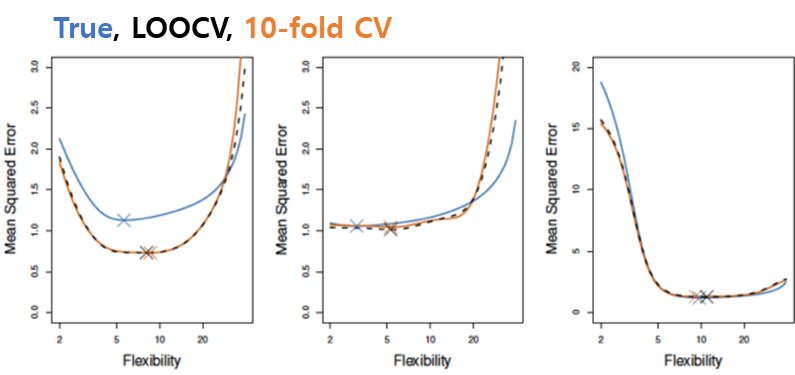
-> LOOCV ≈ 10-fold CV
-> 실제 MSE와 비슷하게 예측
05. 그래프 활용
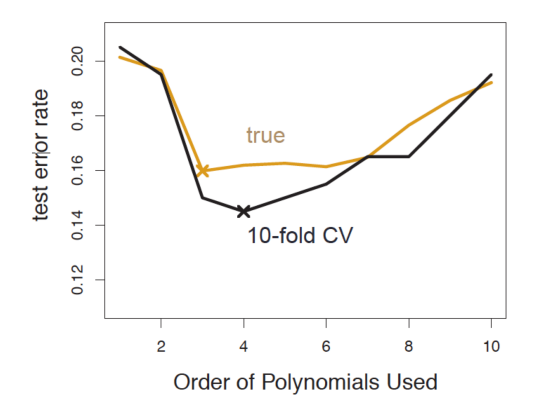
- Logistic regressions with various degrees
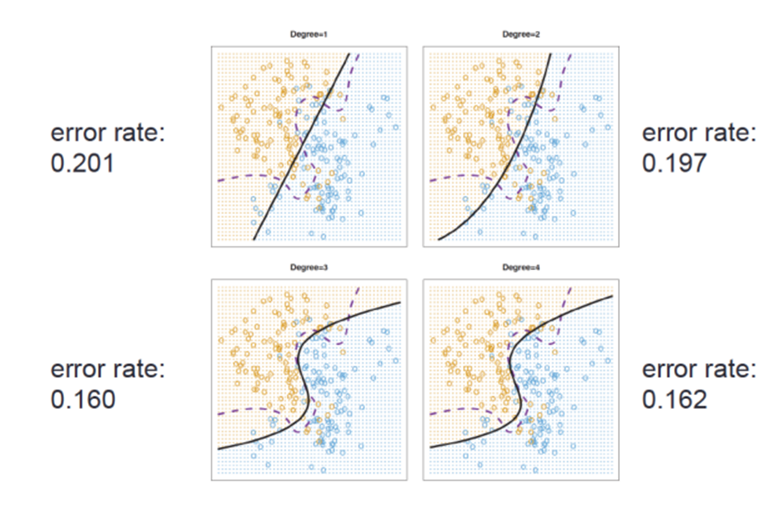
-
CV를 활용하여 적합한 degree 선택
-
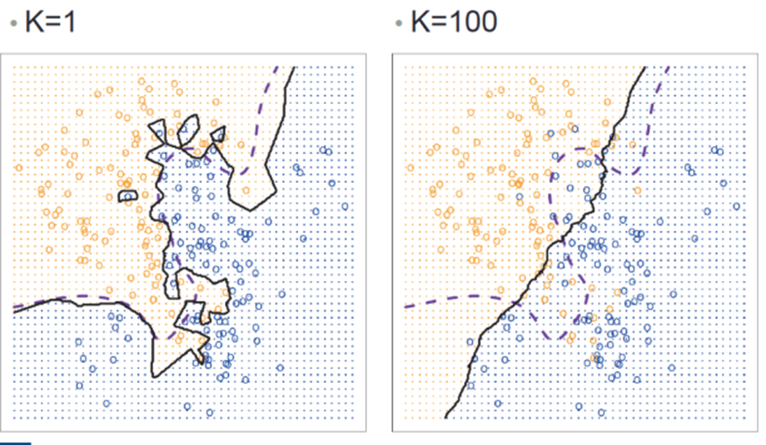
KNN텍스트
-
CV를 활용하여 적합한 K를 선택
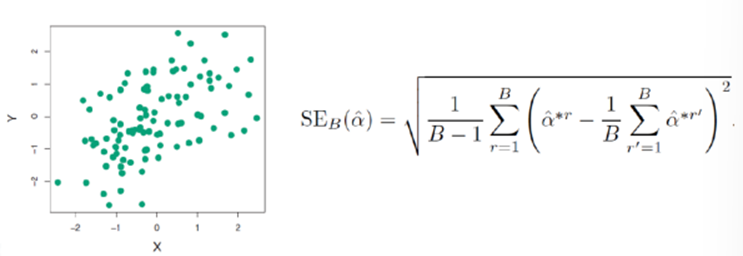
2. 부트스트랩(bootstrap)
: 통계학적인 추론을 위해 사용되는 재표본추출 방법 중 하나로, 원래 데이터셋으로부터 복원 추출을 통해 여러 개의 재표본을 생성하는 과정
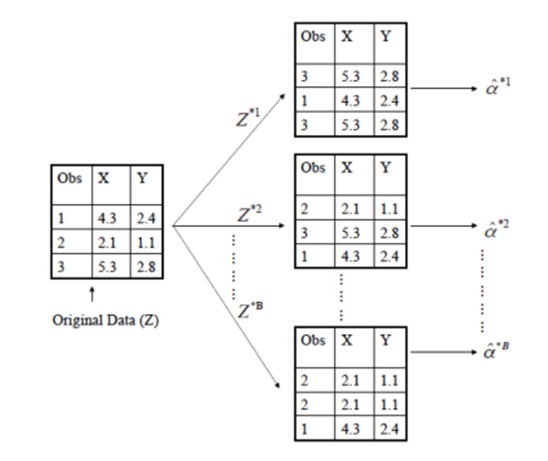
- n개의 데이터가 주워졌을때
STEP1 n개의 교체를 허용하면서 선택 (동일한 데이터 1번 이상 선택 가능)
STEP2 B번 반복 -> B개의 bootstrap data set
STEP3 B개의 예측값 -> standard error 계산
- 3개의 데이터가 있는 경우
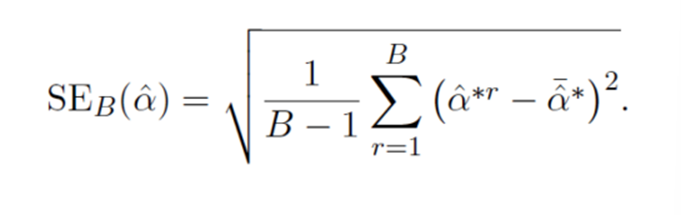
3. Lab
