[Paper Review] BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
BERT (원문 번역)
2018년 구글에서 공개한 자연어 사전학습모델 BERT

Abstract
- BERT는 라벨링되지 않는 텍스트 문서의 context를 파악하기 위해 bidirectional 한 모델이다.
- pre-trained BERT 모델은 output layer를 추가해 fine-tune하는 것만으로 광범위한 task에서 SOTA를 달성했다.
1. Introduction
- pre-training 언어모델은 많은 자연어 처리 task의 향상에 효과적이었다.
- down-stream task를 위해 pre-trained 언어 표현을 사용하는 방식은 두가지 전략이 있다: feature-based, fine-tuning
- 접근 방식
- feature-based 접근 방식: ELMo
- fine-tuning 접근 방식: GPT
- pre-train 시 같은 목적 함수를 공유함, 여기서 일반적으로 언어표현을 학습하기 위해서 단방향의 언어 학습 모델을 사용
- 한계
- 표준 언어 모델이 단방향인 것이 가장 주요한 한계이며, pre-training동안 사용될 수 있는 구조의 선택에 제약이 있음
- OpenAI의 GPT 모델은 오직 LTR(Left to Right)구조를 사용하므로, self-attention layer에서 모든 토큰들은 오직 이전의 토큰들만 attend할 수 있다.
- 이는 문장 레벨의 task에서 좋지 않고 토큰 수준의 task에서 fine-tuning 적용이 굉장히 불리할 수 있으며, 양쪽으로부터 context를 포함하는게 중요하다.
- BERT
- 본 논문에서는 BERT를 통해 fine-tuning 기반의 접근 방식을 향상시킨다.
- BERT는 Cloze task에 영감을 받은 pre-training을 목적으로 하는 masked 언어 모델(MLM)을 사용함으로 단방향성 제약을 완화시킨다.
- masked 언어 모델에서는 랜덤으로 input 토큰의 일부를 mask하고, 오직 context를 기반으로 mask된 단어를 예측하는 것이 목적임.
- MLM 목적은 왼쪽과 오른쪽의 context를 융합한 표현을 가능하게 하는 것이고, 이를 통해 deep 양방향 Transformer를 pretrain 할 수 있게 함.
- 더불어 pre-train 텍스트 쌍 표현을 공동으로 하는 'next sentence prediction' task도 사용함.
- Contribution
- 언어 표현을 위한 양방향 pre-training의 중요성을 증명했다.
- BERT는 pre-trained deep bidirectional representations를 가능하게 하기 위해 MLM을 사용함.
- pre-trained 표현은 많은 heavily-engineered task-specific 구조의 필요성을 줄여준다는 것을 보여준다,
- BERT는 큰 문장 수준, 토큰 수준 task에서 SOTA를 달성해, 많은 task-specific 구조를 능가하는 최초의 모델임.
- 언어 표현을 위한 양방향 pre-training의 중요성을 증명했다.
2. Related Work
- long history of pre-training general language representations
2.1 Unsupervised Feature-based Approaches
- pre-trained 워드 임베딩은 현대의 NLP 시스템에서 필수적인 부분임.
- 워드임베딩 벡터를 사용하기 위해, LTR 언어 objective와 좌우 context에서 잘못된 단어를 구별하는 objective를 사용함.
- 문장 표현을 train하기 위해 여러 objectives 사용해왔다.
- 이전의 작업들은 다음 문장의 후보를 rank
- 이전 문장의 주어진 표현으로 다음 문장 단어를 LTR로 생성
- objectves에서 파생된 오토인코더 노이즈 제거
- ELMo는 LTR, RTL 언어 모델로부터 context-sensitive 특징을 추출함
- 상황별 워드 임베딩들을 기존의 task-specific 구조와 통합할 때, ELMo는 여러 NLP 벤치마크에서 SOTA를 달성할 수 있었음(QA, SA, NER)
- LSTM을 사용해 좌우 모두로부터 단어를 예측하기 위한 작업으로 문맥학습을 제안
- ELMo와 같은 모델들은 특징기반이고 깊은 양방향이 아님
- Fedus et al.은 cloze task가 텍스트 생성 모델의 견고성을 향상시키는데 사용될 수 있다고 보여줌
2.2 Unsupervised Fine-tuning Approaches
- 특징기반 접근과 마찬가지로, 처음 작업으로 레이블되지 않은 사전훈련된 워드 임베딩 파라미터만 사용한다.
- 더 최근엔, 문맥적 토큰 표현을 생성하는 문장 혹은 문서 인코더가, 레이블되지 않은 텍스트로부터 사전훈련하고 지도된 downstream task에 맞게 fine-tuning된다.
- 이런 접근의 가장 큰 장점은 밑바닥부터 학습할 파라미터의 수가 거의 없다는 것임(밑바닥부터 학습을 진행하지 않아도 됨)
- 이러한 장점 덕분에, GPT는 이전에 GLUE 벤치마크로부터 많은 문장 단위 task에 SOTA를 달성함
- LTR 언어 모델링과 오토 인코더 objectives는 아래와 같은 모델에서 사전 훈련하기 위해 사용되어져 왔다.
- Universal language model fine-tuning for text classification, Improving language understanding with unsupervised learning, Semi-supervised sequence learning
2.3 Transfer Learning from Supervised Data
- 대규모 데이터셋과 함께 지도 task로부터 효과적인 전이를 보여준 작업들도 있다.
- such as natural language inference and machine translation
- 컴퓨터 비전 연구는 대규모 사전학습된 모델로부터 전이 학습의 중요성을 입증함
- 대규모 사전 학습된 모델은 ImageNet으로 사전훈련된 모델을 fine-tune하기 위한 효과적인 레시피임
3. BERT

- BERT의 프레임워크는 두개의 단계가 있다: pre-training, fine-tuning
- pre-training: 모델은 다른 사전훈련하는 task들을 걸쳐 라벨링되지 않은 데이터를 학습함.
- fine-tuning: 먼저 사전훈련된 파라마터로 초기화되고, 모든 파라미터들은 downstream task로부터 라벨된 데이터를 사용해 fine-tune한다.
- 각 downstream task들은 결국 별도로 fine-tune 됨.
- 다만, 다양한 task에 걸쳐 통일된 구조를 가진 것이 특징임.
Model Architecture
- BERT의 모델 구조는 다중 레이어 bidirectional Transformer encoder이다.
- Transformer는 (Attention is all you need.)에 기술된 원래 구현에 기초함.
- annotation & two models
- L = the number of layers(Transformer blocks), H = the hidden size, A = the number of self-attention heads
- BERT_BASE: L=12, H=768, A=12, Total Parameters=110M
- GPT와의 비교를 위해 같은 모델 사이즈
- BERT는 양방향 self-attention을 사용하고, GPT Transformer는 모든 토큰이 왼쪽의 문맥만 attend하도록 강요된 self-attention 사용
- BERT_LARGE: L=24, H=1024, A=16, Total Parameters=340M
Input/Output Representations

- Input
- 다양한 downstream task를 다룰 수 있는 BERT를 만들기 위해, 우리의 input 표현은 단일 문장과 문장의 쌍을 하나의 토큰 sequence로 명확하게 나타낼 수 있음.
- 'sequence'는 BERT에 대한 입력 토큰을 칭함.(하나의 문장 또는 두개의 문장을 묶은 것일 수도 있음)
- 30,000개의 토큰 단어를 사용하는 WordPiece 임베딩을 사용함.
- 모든 sequence의 첫번째 토큰은 항상 특별한 분류 토큰 CLS를 사용함.
- 이 토큰에 해당하는 마지막 은닉 상태는 분류 작업을 위해 합계 sequence 표현으로 사용됨.
- 하나의 문장쌍은 하나의 sequence로 함께 묶임
- 문장의 구분
- 첫 번째로, 특별한 토큰 SEP로 문장을 구별함.
- 두 번째로, 모든 토큰에 이것이 문장A or 문장B인지 표시하는 학습된 임베딩을 추가함.
- E = input embedding, C∈RH = the final hidden vector of the special CLS token, Ti∈RH = the final hidden vector for the i_th input token
- 주어진 토큰의 입력 표현은 해당 토큰, 세그먼트, position 임베딩을 합쳐서 구성된다.
3.1 Pre-training BERT
- LTR, RTL 언어 모델을 사용한 사전훈련 대신에, 앞으로 언급할 두개의 비지도 task를 사용해 BERT를 사전훈련함.

Task #1: Masked LM
- 직관적으로, 깊은 bidirectional 모델이 LTR, LTR + RTL의 얕은 결합보다 절대적으로 더 강력할 것이라는 믿음은 합리적임.
- 일반적인 조건부 언어 모델들은
- 양방향 조건에서는 간접적으로 단어의 'see itself'를 허용하고, 다중 레이어 문맥에서 대상 단어를 좋지 않게 예측할 수 있음.
- 이러한 이유로, 오직 LTR or RTL로만 훈련될 수 있음.
- Masking, MLM
- 깊은 bidirectional 표현 학습을 위해, input 토큰의 일정 비율을 랜덤으로 mask하고 masked된 토큰을 예측하도록 한다.
- 이 경우에, mask 토큰에 해당하는 마지막 은닉 벡터는 어휘를 통해 output softmax로 공급됨.(표준 LM과 같이)
- 각 sequence에서 모든 WordPiece 토큰의 15%를 mask한다.
- 오토인코더가 전체 input을 재구성하는 것과는 대조적으로, BERT에서는 오직 masked된 단어만 예측한다.
- MASK token
- fine-tuninng에는 MASK 토큰이 나타나지 않으므로, pre-training과 fine-tuning 사이에 불일치를 만들어내는 단점이 존재함
- 이를 완화하기 위해, masked 단어를 실제 MASK 토큰으로 대체하지 않는다.
- training data generator는 예측을 위해 무작위로 token position의 15%를 선택.
- 선택된 i번째 토큰을 아래와 같은 토큰 비율로 변경함.
- 80%는 MASK 토큰
- 10%는 임의의 토큰
- 10%는 변경되지 않는 i번째 토큰
- 는 cross entropy 손실과 함께 원래의 토큰을 예측하기 위해 사용됨.
Task #2: Next Sentence Prediction(NSP)
- 많은 중요한 downstream task(QA, NLI)는 두 문장 사이의 관계를 이해하는 것을 기반으로 함.
- 언어 모델에 의해서는 직접적으로 포착되지 않음
- 문장 관계를 이해하도록 모델을 훈련하기 위해, 어떤 하나의 말뭉치로부터 생성될 수 있는 Next Sentence Prediction task를 2진화하기 위해 사전훈련한다.
- 각 사전 훈련 예제에 대해 문장A, B를 선택할 때(훈련 데이터를 배치할 때)
- B의 50%는 A 다음에 실제로 오는 다음 문장
- 나머지 50%는 말뭉치로부터 랜덤 문장임.
- 각 사전 훈련 예제에 대해 문장A, B를 선택할 때(훈련 데이터를 배치할 때)
- C는 다음 문장 예측에 사용됨.
- 이런 단순함에도 QA와 NLI 모두에 매우 유익했음을 증명(5.1섹션에서)
- NSP는 아래 논문에서 사용된 표현 학습 목표와 밀접히 연관됨
- Jernite et al.(Discourse-based objectives for fast unsupervised sentence representation learning) 및 Logeswaran and Lee(An efficient framework for learning sentence representations.)
- 하지만 문장 임베딩만이 downstream task로 전이됨.
- BERT는 end-task 모델 파라미터를 초기화하기 위해 모든 파라미터를 전이함.
- NSP는 아래 논문에서 사용된 표현 학습 목표와 밀접히 연관됨
Pre-training data
- 사전 훈련 절차는 LM의 사전 훈련의 기존 문헌을 대체로 따름.
- 긴 연속적인 sequence를 추출하기 위해, Billion Word Benchmark와 같이 이것저것 섞인 문장 레벨 말뭉치가 아닌, 문서 레벨 말뭉치를 사용하는게 중요함.
3.2 Fine-tuning BERT
- Transformer의 self-attention 메커니즘으로 fine-tuning은 간단함.
- BERT가 적절한 입력과 출력을 교환함으로써 많은 downstream task를 모델링할 수 있도록 해주기 때문에(단일 혹은 텍스트 쌍을 포함하든지 간에)
- 텍스트 쌍을 포함하는 application의 경우, bidirectional cross attention을 적용하기 전에 텍스트 쌍을 독립적으로 인코딩 하는 것이 일반적임
- Parikh et al.(A decomposable attention model for natural language inference.)등 과 같이
- BERT는 위의 두 단계를 통합하기 위해 self-attention 메커니즘을 사용한다.
- self-attention을 통해 연결된 텍스트 쌍을 인코딩하는 것은 두 문장 사이의 bidirectional cross attention을 효과적으로 포함하므로.
- 각 task마다의 input과 output을 BERT에 연결하고 모든 파라미터를 end-to-end로 fine-tuning한다.(입력, 출력 단에 W layer 추가해서 미세조정)
- 입력에서, 사전훈련으로부터 나온 문장 A, B는 paraphrasing, hypothesis-premise, question-passage, degenerate text-ϕ 의 쌍들과 유사
- 출력에서, 토큰 표현은 토큰 단위 task를 위한 output layer로 공급됨.
- CLS 표현은 분류를 위해 output layer로 공급됨.
- pre-training에 비해, fine-tuning은 상대적으로 비싸지 않음.
4. Experiments
4.1 GLUE
4.2 SQuAD v1.1
4.3 SQuAD v2.0
4.4 SWAG
5. Ablation Studies
- (모델이나 알고리즘의 기능들을 하나씩 제거해보면서 이 기능이 전체 성능에 얼마나 영향을 미치는지 확인해 보는 작업)
- 상대적인 중요성을 더 이해하기 위해, BERT의 여러 면에 걸쳐 ablation 실험을 수행함
5.1 Effect of Pre-training Tasks

- 같은 사전 훈련의 데이터, fine-tuning scheme, 하이퍼파라미터를 사용해 BERT_BASE의 깊은 bidirectionality의 중요성을 입증함.
No NSP
- 다음 문장 예측(NSP) 없이, masked LM(MLM)을 사용한 bidirectional 모델
LTR & No NSP
- MLM 대신 일반적인 LTR LM을 사용해 훈련된, 오직 좌에서 우로 이어지는 문맥을 가진 모델.
- left-only는 fine-tuning에서도 적용되어야 함.
- pre-training과 fine-tuning에서의 불일치는 downstream task에서 좋지 못한 성능을 보임
- left-only는 fine-tuning에서도 적용되어야 함.
- NSP 없이 사전 훈련됨.
- NSP 영향력 검토
- NSP를 제거하는 것이 QNLI, MNLI와 SQuAD 1.1에서 퍼포먼스를 상당히 하락시킨다는 것을 보여줌.
- No NSP와 LTR & No NSP를 비교하면서 bidrectional 표현을 훈련하는 것의 영향력을 평가
- LTR 모델의 퍼포먼스는 MLM 모델보다 MRPC와 SQuAD에 큰 영향을 미치는(large drops) 모든 과제에 대해서 좋지 않음
- SQuAD에 대해 LTR모델은 토큰 레벨 은닉 상태가 우측 문맥이 없기 때문에 토큰 예측을 잘 못할 것이다는 것은 직관적으로 명확하였음.
- LTR 시스템을 강화하는 시도에 좋은 믿음(faith)을 만들기 위해서 우리는 무작위로 초기화된 BiLSTM을 맨 위에 추가
- SQuAD에서 효과적으로 결과를 향상시켰지만, 결과는 사전 훈련된 bidrectional 모델에 비해 여전히 꽤 나쁨(GLUE작업 성능 해침)
- ELMo가 하는 것처럼 별도의 LTR 및 RTL 모델을 훈련하고 각 토큰을 두 모델의 연결로 나타내어 평가
- 두 번 계산하기 때문에 단일 양방향 모델에 비해 두 배로 계산비용이 비쌈
- RTL 모델은 질문에 대한 답변을 조절할 수 없음
- QA(Question and Answer)와 같은 작업에 대해서 직관적이지가 않음
- 모든 layer에서 양쪽의 문맥을 사용하므로, 깊은 bidrectional 모델보다 성능이 낮을 수밖에 없음.
5.2 Effect of Model Size

- 모델 크기가 fine-tuning task 정확도에 미치는 영향 탐구.
- number of layers, hidden units, attention heads 를 다르게 하면서 훈련함.
- 더 큰 모델이 3,600개의 라벨이 붙은 훈련 샘플만을 사용 + 사전 훈련 작업과 실질적으로 다른 MRPC에서 4개의 데이터셋 모두에서 정확도를 strict 향상됨.
- 이미 상당히 큰 모델들 위에, 유의미한 개선을 달성한 것
- 탐구된 가장 큰 Transformer는 100M 개의 파라미터(L=6, H=1024, A=16), 문헌에서 찾은 가장 큰 Transformer는 235M개의 파라미터(L=64, H=512, A=2)
- BERT_BASE는 110M개의 파라미터를 포함, BERT_LARGE는 340M개의 파라미터를 포함
- 이미 상당히 큰 모델들 위에, 유의미한 개선을 달성한 것
- 모델 사이즈와 성능 향상과의 관계
- 기계번역, LM과 같은 큰 task에서 모델 사이즈를 키우는 것은 계속된 향상을 이끈다고 알려짐
- Table.6의 LM에서 입증됨.
- 충분한 사전 훈련 + 극단적인 모델 크기의 확장이 매우 작은 규모의 task에서도 큰 개선으로 이어짐.(설득의 첫 단계정도)
- downstream task 데이터가 매우 작은 경우에도 사전훈련된 표현으로부터 이익을 얻을 수 있음.
- downstream task에 맞게 fine-tuning되고, 적은 수의 랜덤되어 초기화된 추가적인 파라미터를 사용함.
- 기계번역, LM과 같은 큰 task에서 모델 사이즈를 키우는 것은 계속된 향상을 이끈다고 알려짐
5.3 Feature-based Approach with BERT
- 지금까지 살펴본 결과는, fine-tuning 접근법
- 사전 훈련된 모델에 간단한 분류 layer를 추가해, 모든 매개변수가 downstream task에서 공동으로 fine-tuning되는 방식
- 반대로, 사전 훈련된 모델에서 고정된 특징을 추출하는 feature-based 접근 방식의 장점도 있음
- 모든 task가 Transformer 인코더 구조에 의해 쉽게 표현되어지지 않는다는 점
- 과제별 모델 구조가 추가되어야 함.
- 계산상의 큰 이익
- 계산이 비싼 훈련 데이터의 표현을 한 번 사전 계산하는 것
- 이런 표현들 위에 값싼 모델과 함께 많은 실험을 수행할 수 있다는 점
- 모든 task가 Transformer 인코더 구조에 의해 쉽게 표현되어지지 않는다는 점
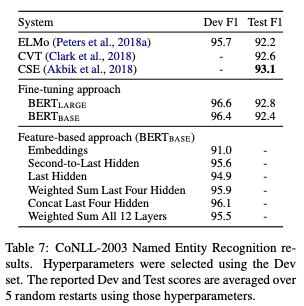
- BERT에 두 가지 접근법을 도입해, CoNLL-2003 NER(Named Entity Recognition, 이름 명명 인식) 작업을 비교
- ready
- BERT의 input으로 대소문자를 구별하는 WordPiece 모델을 사용, 데이터에 의해 제공되는 최대 문서 문맥을 포함
- 이것을 태킹 task로 공식화 하지만, output에 CRF 레이어를 사용하지 않음(표준 관행에 따라)
- BERT의 파라미터를 fine-tuning하지 않고, 하나 또는 그 이상의 layer에서 활성화 함수를 추출하는 것으로 feature-based 접근법을 적용
- 문맥적 임베딩은 분류 layer 이전에 랜덤으로 초기화된 768차원의 BiLSTM 2개를 쌓은 layer에 대한 input으로 사용
- results
- BERT_LARGE는 SOTA를 경쟁력있게 달성
- 가장 좋은 수행 방법은 사전 훈련된 Transformer 4개의 은닉 layer로부터 토큰 표현을 결합하는 것이었음.
- 전체 모델을 fine-tuning하는 것에 비해 0.3 F1밖에 뒤처짐.
- 결과적으로, BERT는 fine-tuning과 feature-based 접근법 모두 효과적임을 입증함.
- ready
6. Conclusion
- LM과의 transfer learning 덕분에 최근의 경험적 개선은 다음을 증명했다.
- rich, 비지도 사전훈련은 많은 언어 이해 시스템에 필수적인 부분이라는 것.
- 낮은 리소스의 task에서도 깊은 unidirectional 구조로부터 이익을 얻는 것을 가능하게 함.
- 이 연구의 가장 큰 기여점은 다음과 같다.
- 깊은 bidirectual 구조를 일반화 한 것.
- 동일한 사전훈련 모델이 광범위한 NLP task를 성공적으로 처리함.

Vision-Language Model과 Video Understanding에 관심이 있습니다.