
머신러닝을 위한 데이터 핸들링 기초
pandas 라이브러리
'권철민' 저자님의 파이썬 머신러닝 완벽가이드 책을 참고했습니다.
또한,kaggle의Datasets중
CCO License인World Happiness Report의 데이터를 사용하여 학습하며 작성했습니다.아래의 글은 직접 학습하며 작성한 게시물로, 오류가 있을 수 있습니다.
고수분들께서 발견하신 오류를 알려주시면 감사하겠습니다!
1. DataFrame의 Column data 생성 및 수정
1.1 생성
DataFrame['{new_column_name}'] = {initialize_value}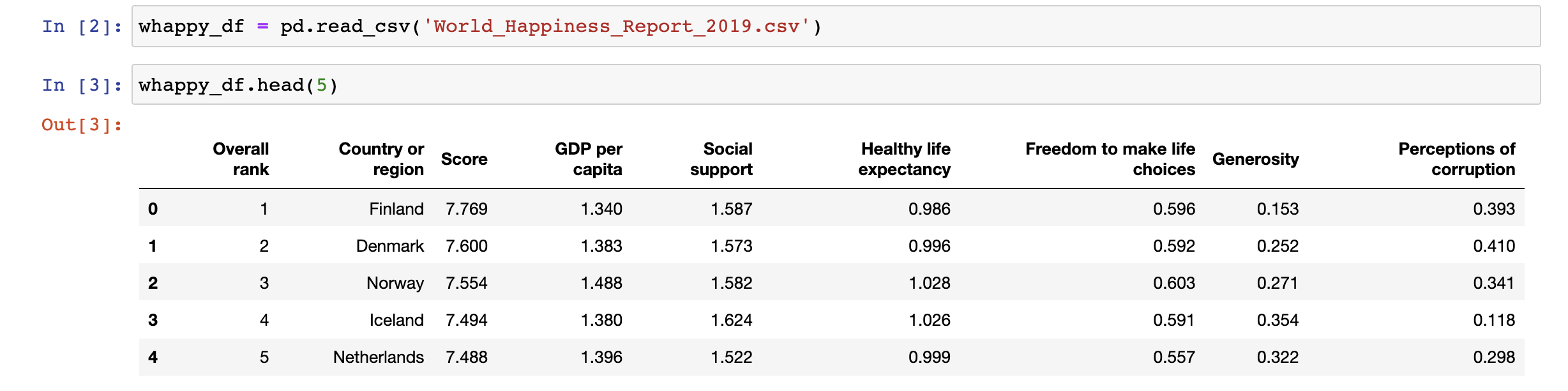
이 원본 데이터에 Country code 열을 추가하고 값을 0으로 초기화하면 다음과 같다.
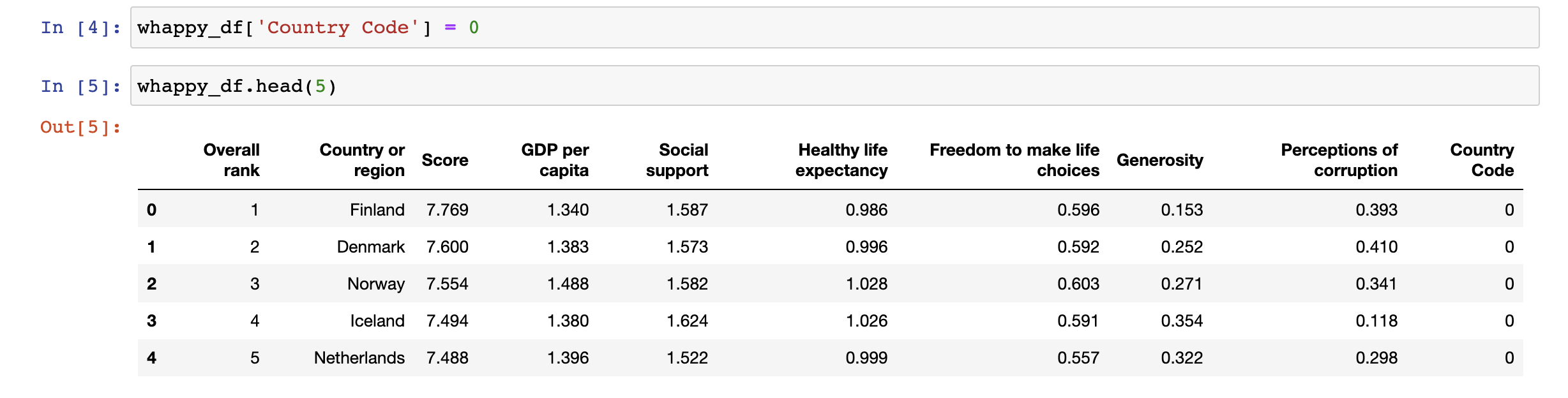
가장 오른쪽을 보면 Country Code 열이 추가되었음을 볼 수 있다.
1.2 수정
- 마찬가지로 기존 column에 값을 할당하여 일괄적으로 data를 수정할 수 있다.
(가장 오른쪽 Country Code 열 참고)
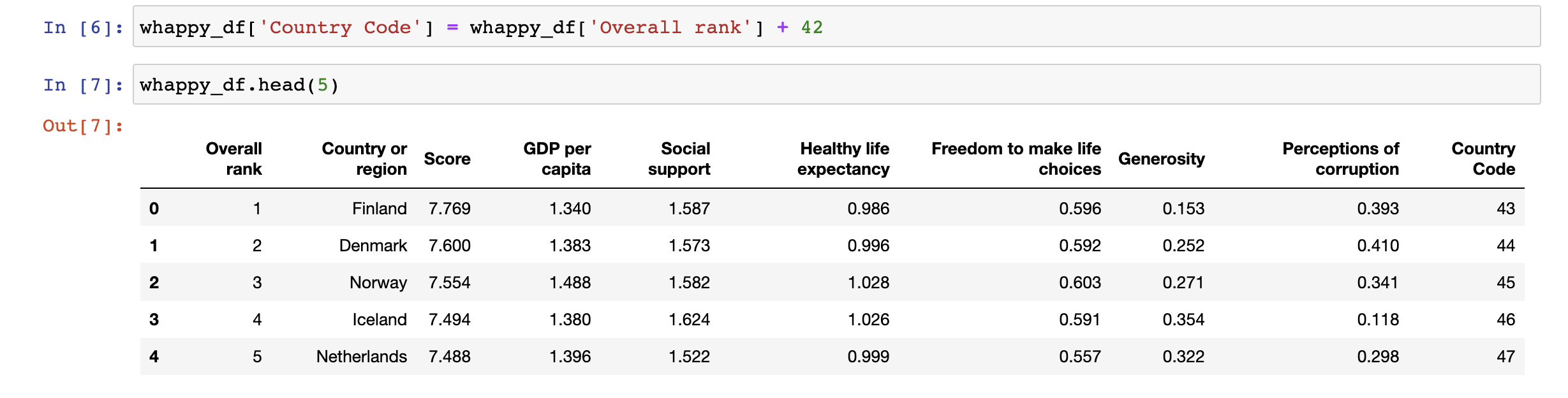
2. DataFrame의 data 삭제
- 데이터 삭제는 drop() 메서드를 사용한다.
drop() 메서드를 사용하는데에 있어서 몇가지 주의할 점이 있다.
- 삭제하는 축이 row인지 col인지.
- 원본을 삭제할 것인지, 원본은 그대로 두고 삭제된 DataFrame을 반환할 것인지.
먼저 drop() 메서드의 원형 중 여기서 주의할 파라미터만 살펴보자. (실제로는 더 많은 파라미터가 있다.)
DataFrame.drop(labels=None, axis=0, inplace=False)-
axis: 축을 나타낸다.
DataFrame은 2차원 데이터를 다루기 때문에,
axis=0은 row를, axis=1은 column을 의미한다. -
labels: axis=0인 경우 index를, axis=1인 경우 column name을 의미한다.
주로 기존 column값을 가공하여 새로운 column을 만들고 삭제하는 경우가 많아
axis=1로 설정하고 drop하는 경우가 많다고 한다.
-
inplace: False인 경우 원본 데이터는 삭제하지 않고 삭제한 결과 DataFrame을 반환한다.
True인 경우 원본 데이터를 삭제한다.
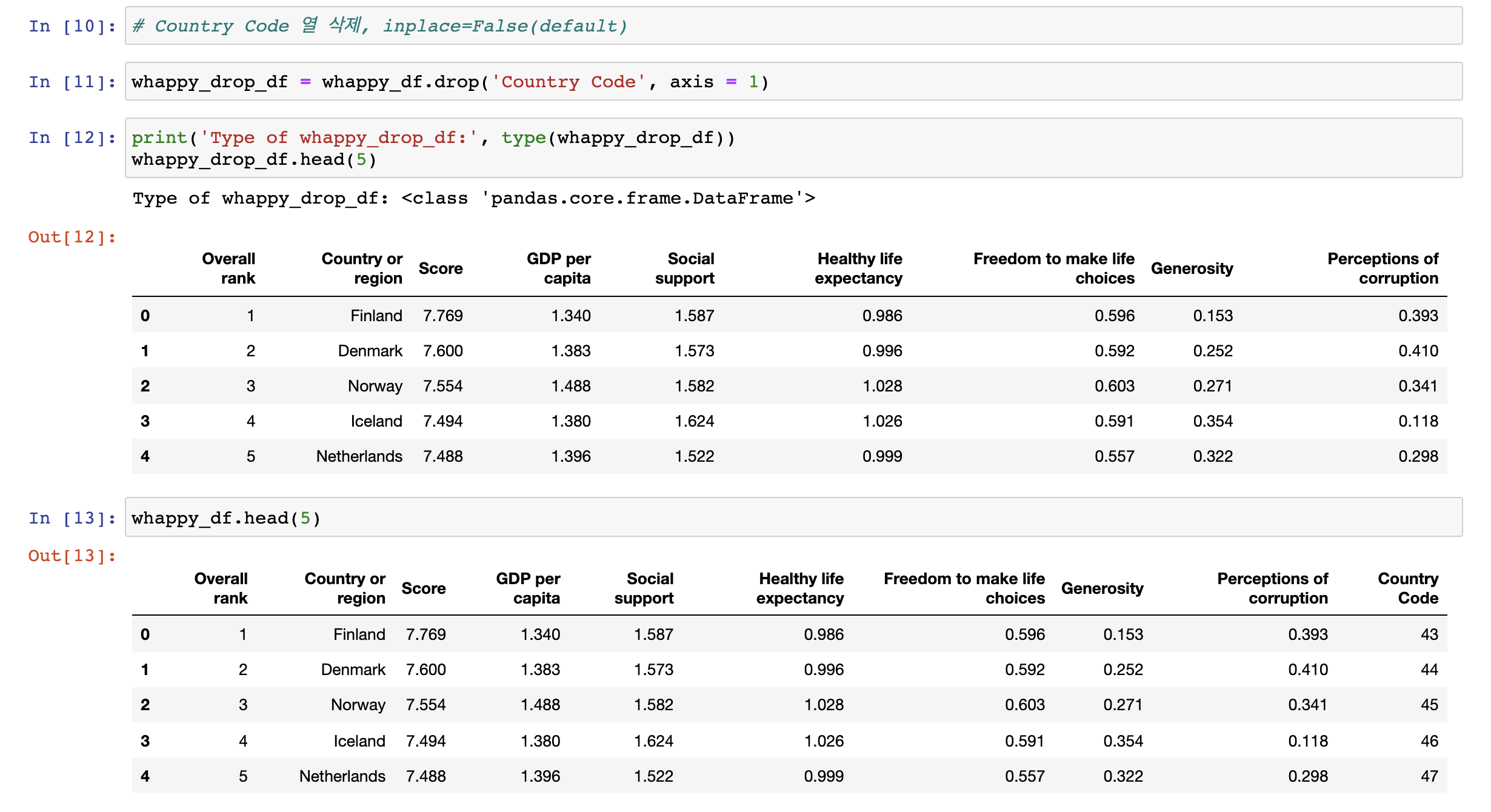
위의 코드를 보면 drop된 데이터를 반환받은 whappy_drop_df은 DataFrame타입이고,
whappy_drop_df의 데이터에는 삭제한 열인 Country Code열이 없지만,
원본 데이터 whappy_df 데이터에는 Country Code열이 남아있다.
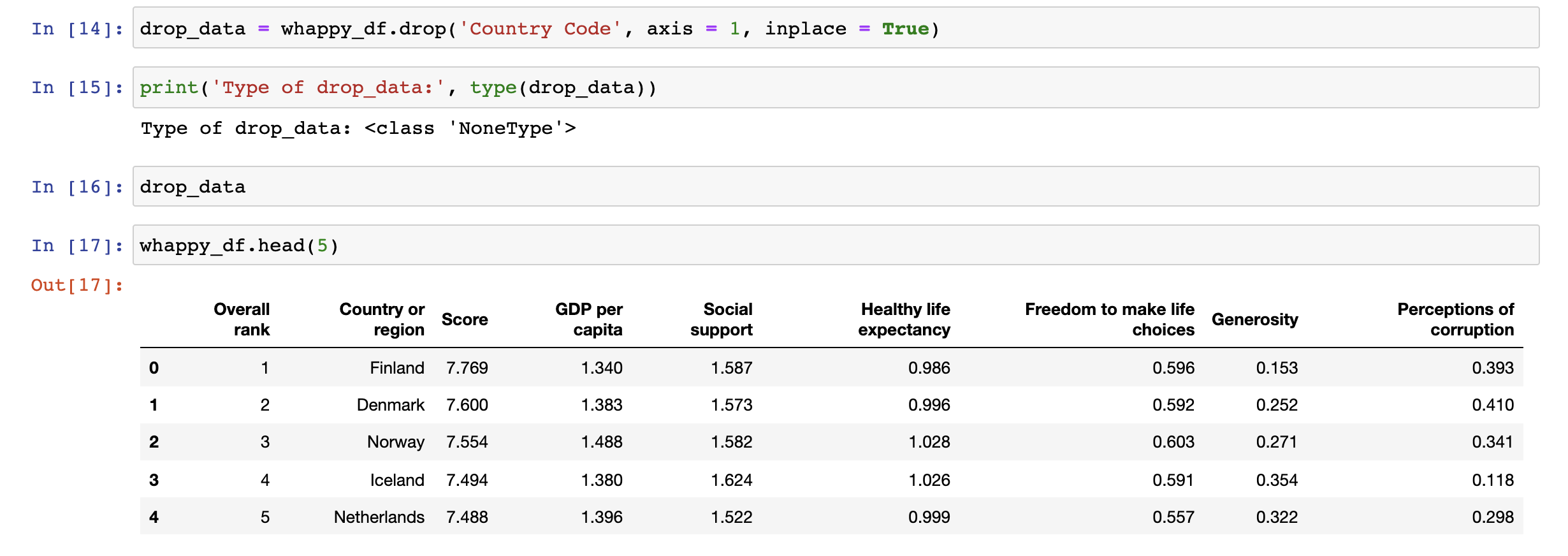
inplace=True 옵션으로 원본 whappy_df의 데이터에서 직접 삭제되었을을 알 수 있다.
또한, drop_data은 Nonetype이다.
즉 inplace=True 인 경우 자신에게 다시 자신의 whappy_df로 할당하면 안된다.
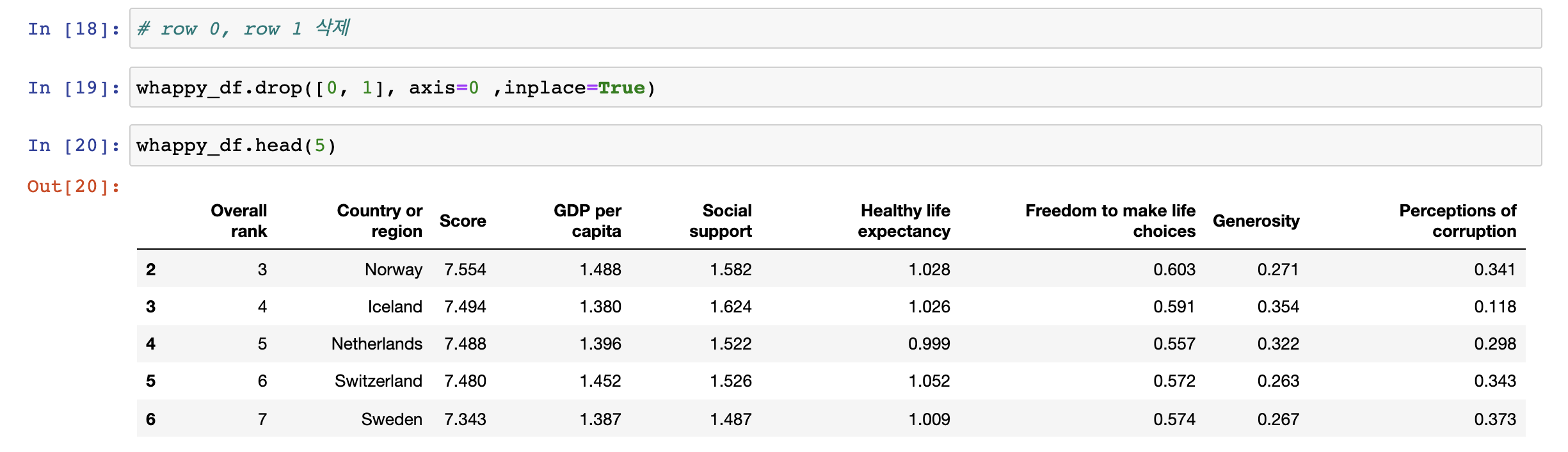
끝으로 row를 삭제하는 방법을 위와 같다.
맨 왼쪽의 index를 보면 0, 1이 사라지고 2부터 시작함을 볼 수 있다.
3. Index 객체
추가적으로 pandas에서는 index객체를 추출하고, 새로 할당하는 방법이 있다.
3.1 index 객체 추출하기.
index객체 자체를 추출하는 방법은 각각 다음의 속성을 사용하여 추출할 수 있다.
DataFrame.index
Series.index

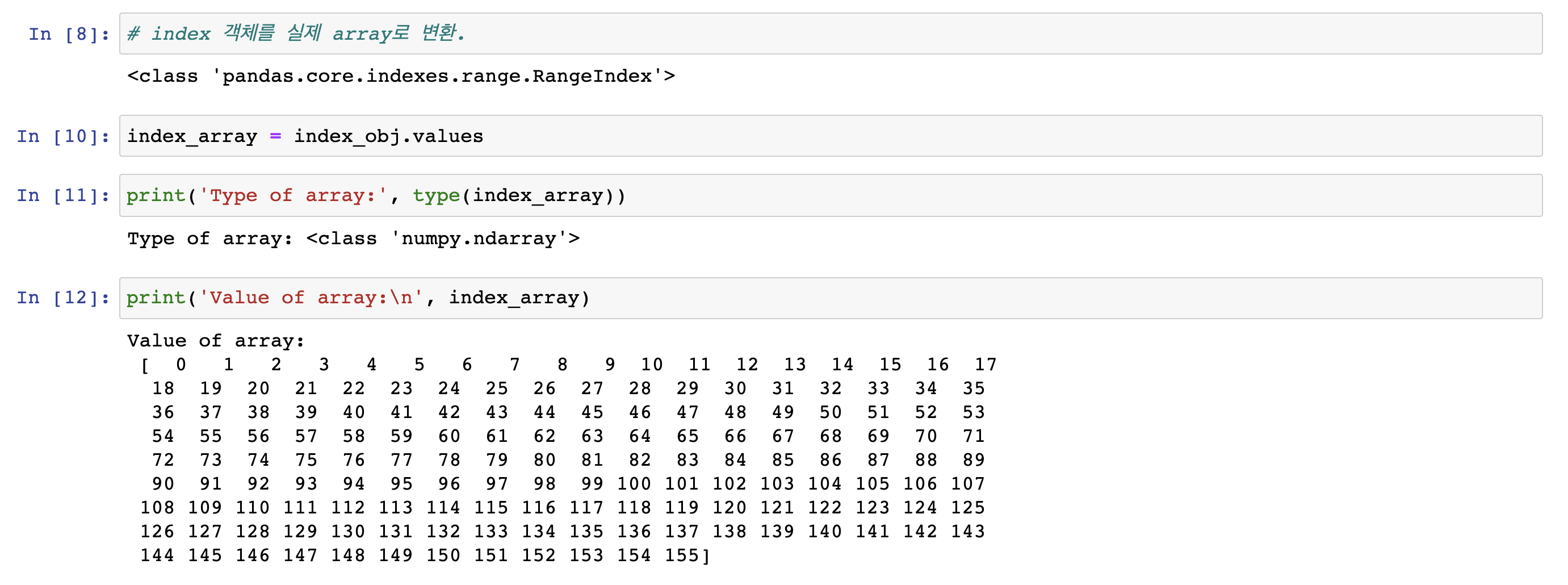
이렇게 추출한 index를 실제 array로 변환하여 사용할 수 있다.
ndarray 타입이기 때문에 관련 기능을 모두 사용할 수 있다.
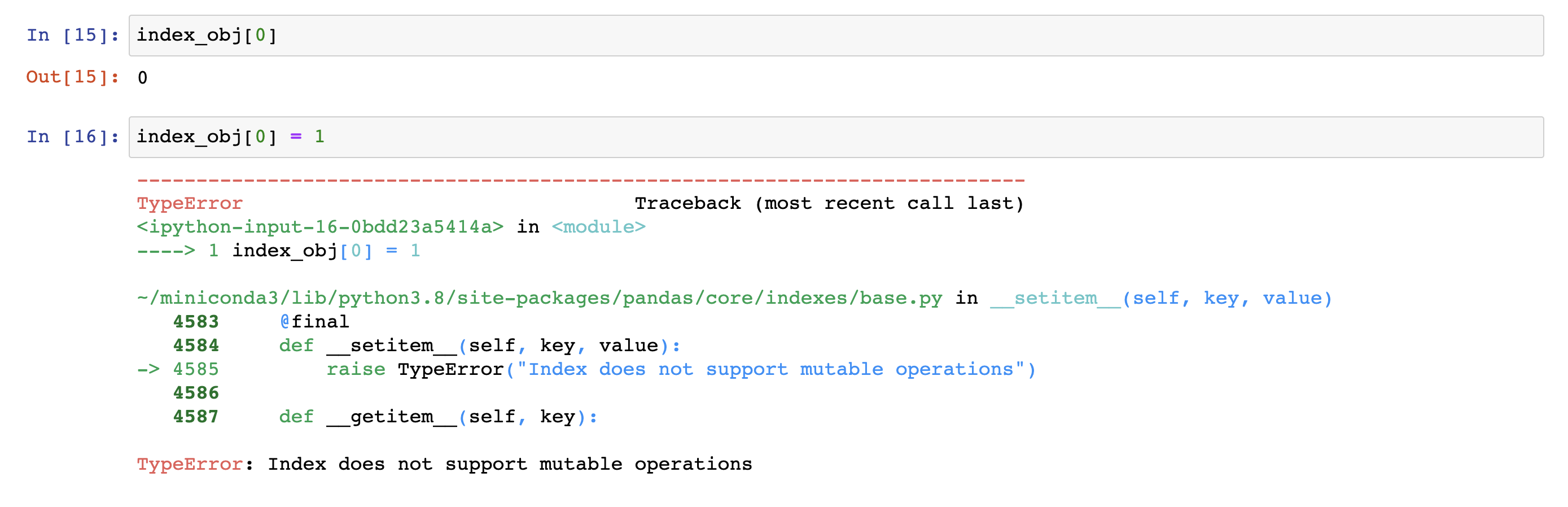
index 객체는 단일 값 반환 또는 슬라이싱등이 가능하지만, 값을 변경하는 작업은 불가능하다.
아래를 보면 'TypeError: Index does not support mutable operations' 라는 에러가 발생한다.
3.2 index 객체 새로 할당하기.
- reset_index() 메서드를 사용하여 DataFrame, Series에 연속 int 숫자형 데이터로 새로운 index를 만들어준다.
이때 기존의 index는 column name = 'index'로 추가된다.
(추가하고 싶지 않다면 reset_index()의 파라미터 drop=True로 설정하면 된다.)
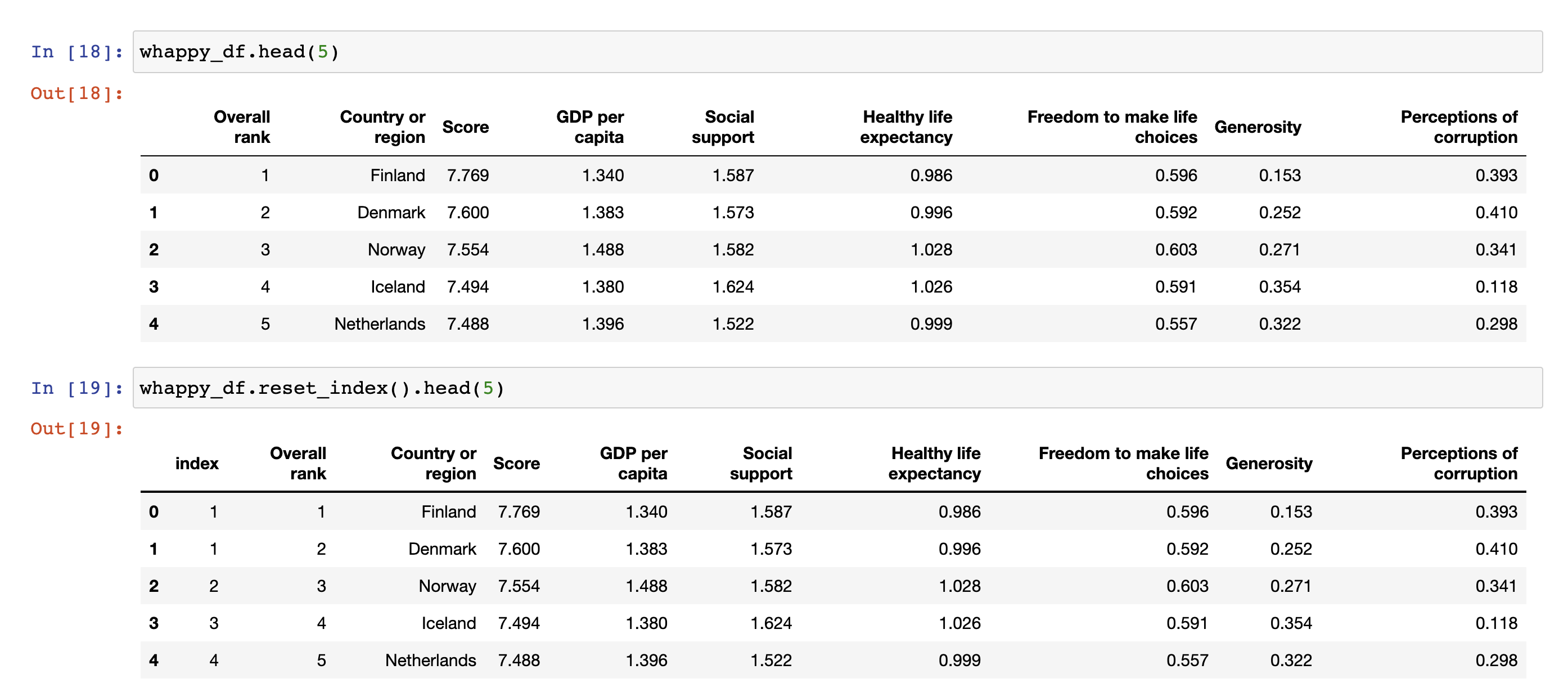
가장 왼쪽에 index라는 이름을 가진 열이 추가 생성되었음을 알 수 있다.
