
머신러닝을 위한 데이터 핸들링 기초
pandas 라이브러리
'권철민' 저자님의 파이썬 머신러닝 완벽가이드 책을 참고했습니다.
또한,kaggle의Datasets중
CCO License인World Happiness Report의 데이터를 사용하여 학습하며 작성했습니다.아래의 글은 직접 학습하며 작성한 게시물로, 오류가 있을 수 있습니다.
고수분들께서 발견하신 오류를 알려주시면 감사하겠습니다!
1. pandas 설치 및 import
1.1 설치
# 개인 가상환경에 pandas 설치
conda install pandas1.2 import

pandas는 pd로 alias하여 import하는것이 관례라고 함.
2. Data
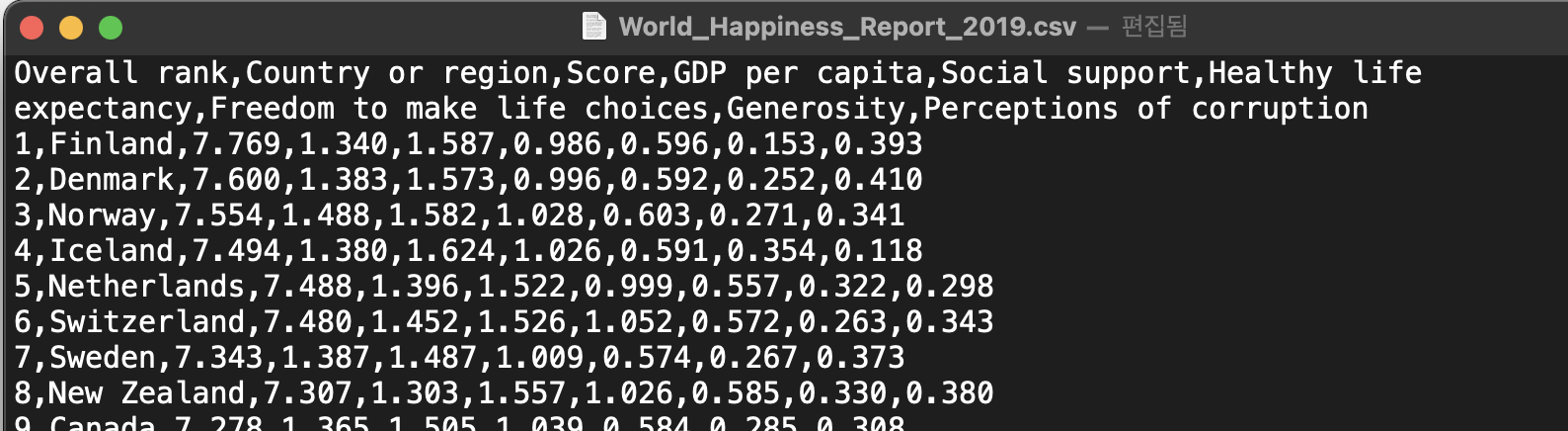
내려받은 data를 확인하니 맨 위의 줄에는 column명이 나열되어있고,
각 field는 콤마(,)로 분리돼 있음을 알 수 있다.
2.1 Data 읽기
read_csv(): CSV 파일 변환을 위한 API.
(read_csv()는 인자로 delimeter를 받는다.
가령, read_csv('fileName', sep='\t')로 탭으로 구분되어있는 파일도 변환이 가능하다는 뜻.)read_table(): Delimeter가 탭('\t')인 파일 변환을 위한 API.
read_fwf(): 고정 길이 기반의 column 포맷 변환을 위한 API.
내 파일은 CSV파일이므로, read_csv()를 사용해 변환한다.
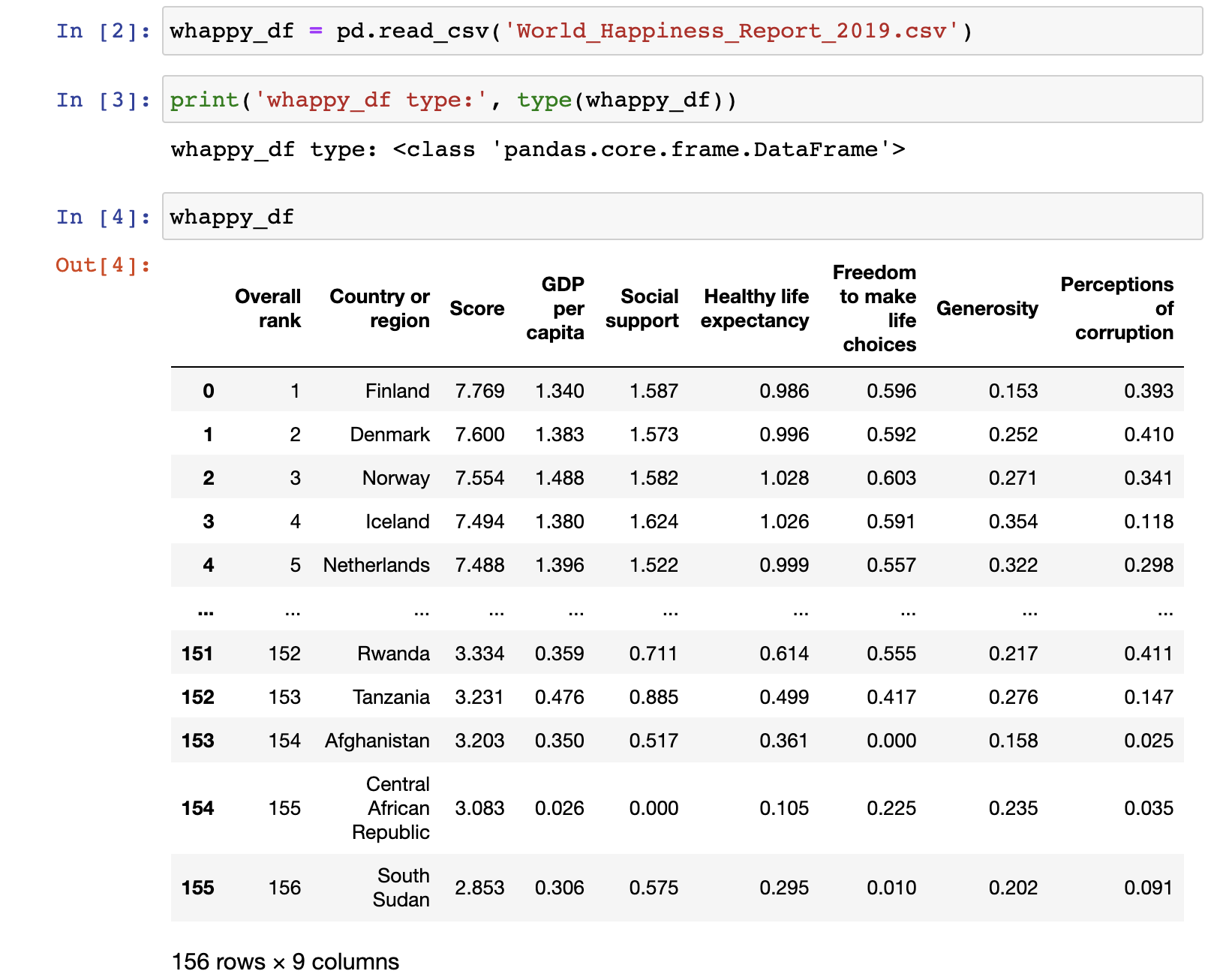
위를 보면, whappy_df객체는 DataFrame type임을 알 수 있다.
이렇게 read_csv()는 파일을 로딩해 DataFrame으로 반환한다.
2.2 Index, Series, DataFrame
2.2.1 Index
Index는 알다시피 개별 데이터를 식별하는 Key값이다.
Series와 DataFrame모두 Index를 Key값으로 가지고 있다.
위의 이미지에서 Overall rank의 왼쪽에 있는 수가 Index이다.
2.2.2 Series & DataFrame
Serise와 DataFrame의 가장 큰 차이는
Serise는 column이 하나뿐이고, DataFrame은 여러개라는 점이다.
즉, 위의 이미지 전체는 DataFrame이라고 할 수 있다.
이때 한 컬럼인 Country or region을 뽑아서 보면,
이 데이터는 Serise라고 한다.

추가로, Index는 문자열도 가능하며, 고유성이 보장된다면 아래와 같이 사용할수도 있다.

이 경우, 각 국가 또는 지역명이 Index이다.
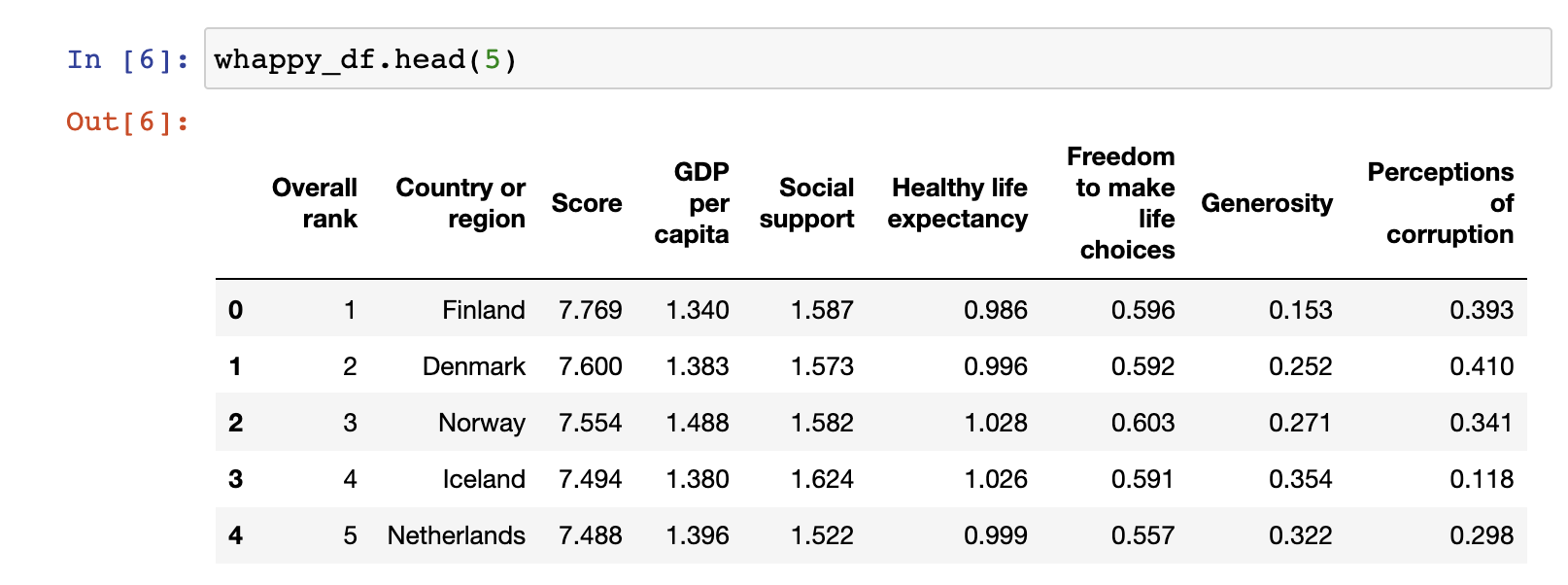
2.3 head()
- DataFrame.head()는 DataFrame의 맨 앞 N개의 row를 반환한다. (default = 5)
2.4 info()
- DataFrame.info()는 총 데이터 수, Null 수 등을 알 수 있다.
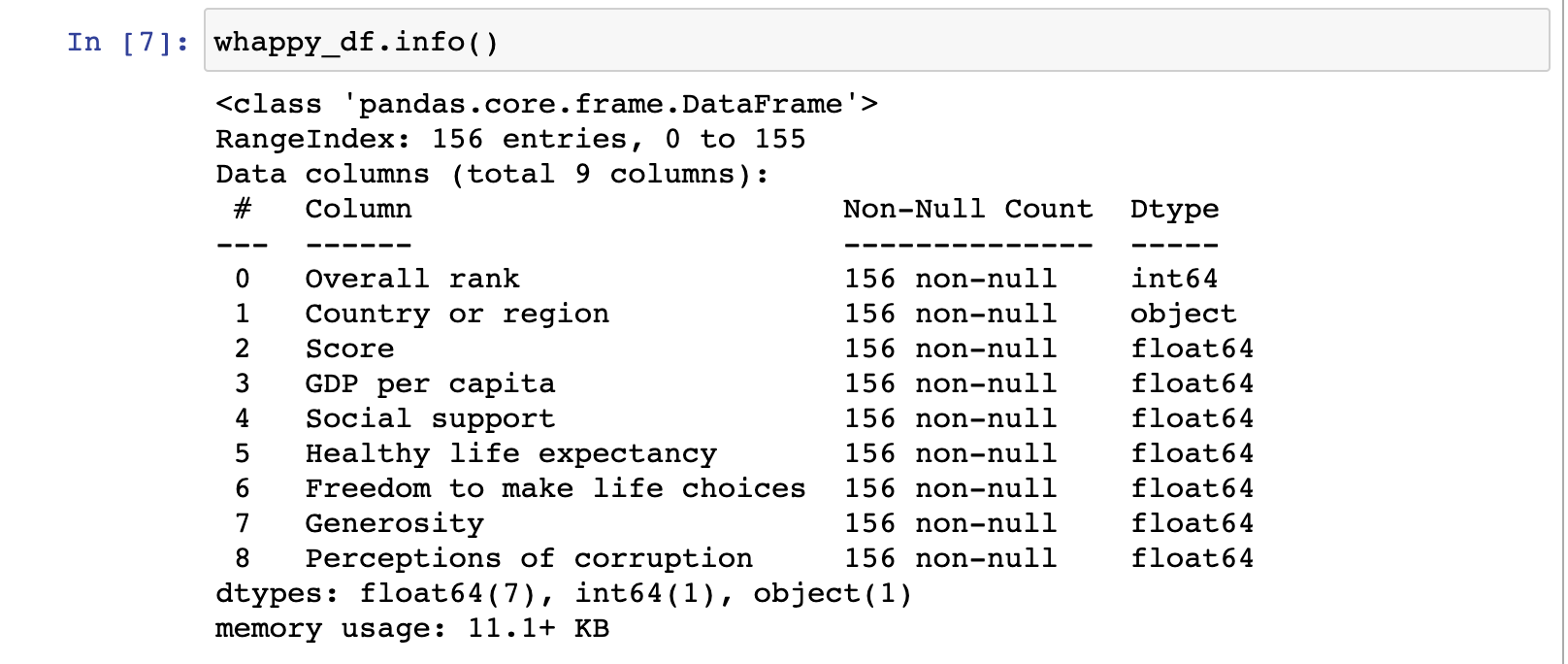
위부터 순서대로, row와 column수를 알 수 있고,
각 column별 data type을 알 수 있다.
'Non=Null Count'는 몇개의 데이터가 Null값이 아닌지 나타낸다.
아래쪽의 dtypes는 전체 column들의 type을 요약한다.
내 자료는 전체 (156, 9) 크기의 data이다.
그리고 Null값은 없으며, 9개의 column중 7개는 float이고 나머지는 각각 int64, object type이다.
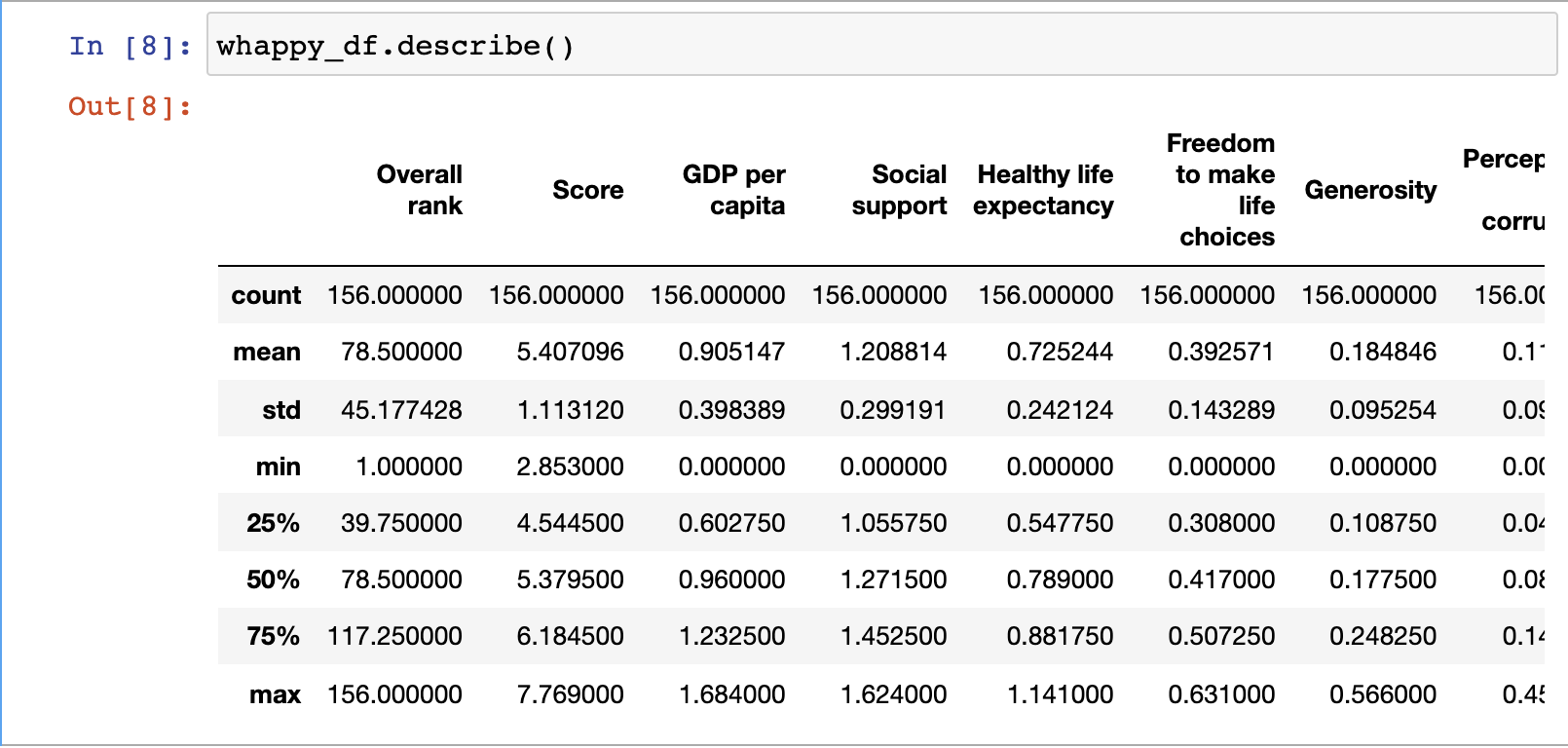
2.5 describe()
DataFrame.describe()는 N-% 분포도, 평균값, 표준편차, 최댓값, 최솟값 등을 나타낸다.
2.6 value_counts()
Series.value_counts()는 지정된column의 데이터 건수를 반환한다.
내 데이터의 예시에서는 확인하기 쉽지 않지만,
예를들어 column명이 location이고,
100개의 row 항에서 각각 '서울' - 50개, '부산' - 30개, '인천' - 20개의 값이 들어있다고 하면,
많은 건수 순서로
서울 50
부산 30
인천 20
Name:location, dtype: object식으로 반환 된다.
