ZFNet으로 유명한 다음의 논문을 읽고 학습한 내용입니다.
공부하며 작성한 내용이니 틀린부분 지적해주시면 감사하겠습니다!
Papers : 논문 링크
논문의 구현은 다음의 링크에서 확인할 수 있습니다.
github
ZFNet 이란?
이 논문이 발표 된 시기, 다양한 Large Convolutional Network 모델들이 ImageNet 분류에 상당히 좋은 성능을 내고 있었지만, 해당 모델들이 “왜 좋은 성능을 보이는지", 그리고 “왜 성능이 개선되었는지” 에 대한 물음에는 명확한 답변을 내놓지 못했습니다.
CNN의 구조를 결정하는 많은 HyperParameter를 어떤 값으로 설정할 것인지는 매우 중요합니다. 하지만 어떤 값들의 조합이 최적의 성능을 보이는지 예측하고 판단하기는 굉장히 어렵습니다. 이러한 문제를 해결하기 위해, 이 논문의 저자인 Zeiler는 Visualizing 테크닉을 통해 CNN을 구성하는 여러 layer들에 대한 insight를 제공합니다.
즉, ZFNet에서는 새로운 구조를 제안 하기 보다는, Visualizing을 통해 AlexNet의 Hyperparameter를 변경하여 성능을 더 개선 시킬 수 있음을 보였습니다.
Visualizaition with a Deconvnet
CNN의 기본적인 흐름은 Input(feature map) → Convolution → Activation → Pooling 의 반복이라고 할 수 있습니다. 이때 CNN의 동작을 이해하기 위해 hidden layer에서 위 순서의 반대 작업을 진행하여, CNN의 각 layer에서 어떤 값을 갖는지에 대한 insight를 얻는 것이 논문에서 제안하는 Visualizing 기법입니다.
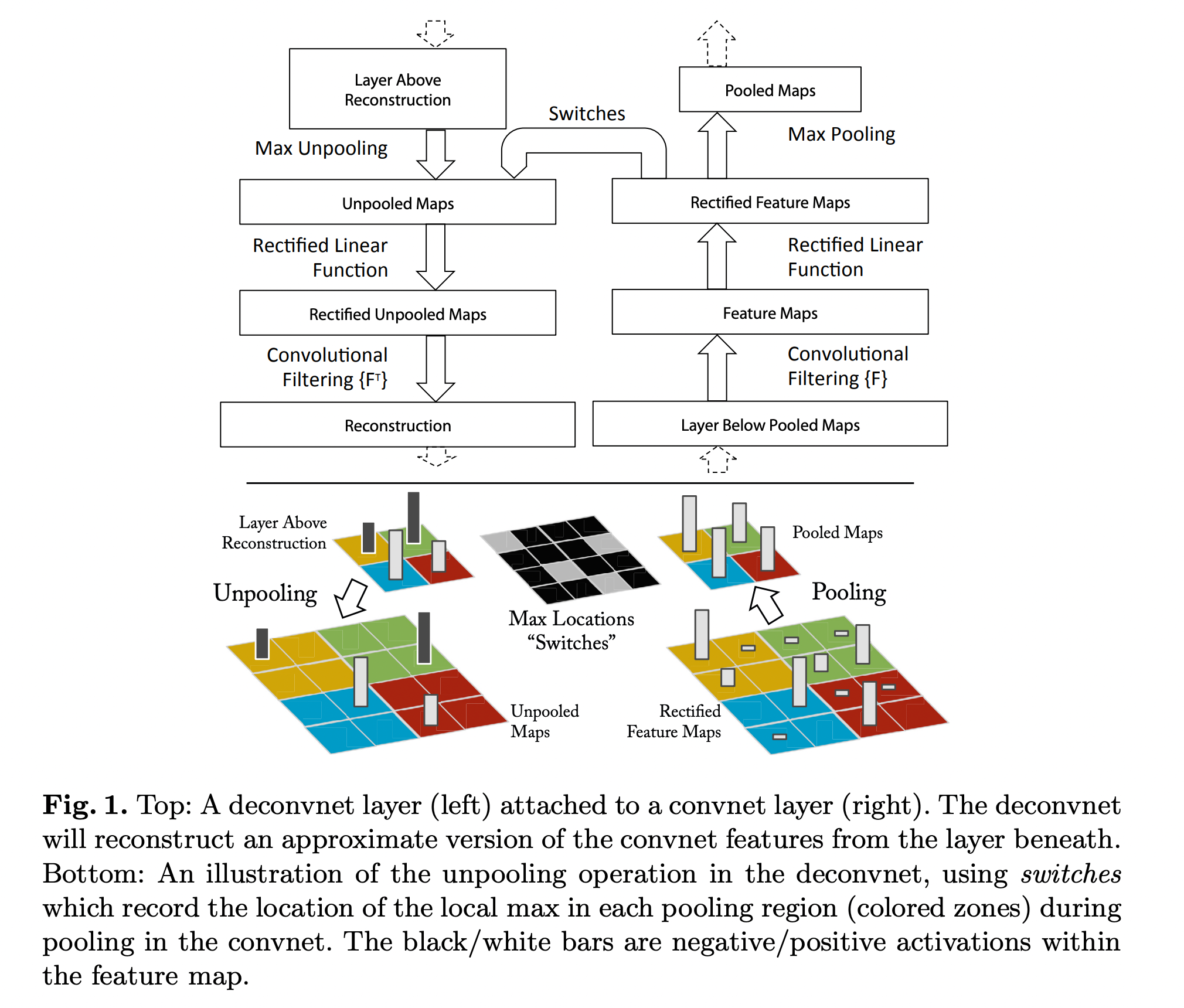
(image source - Matthew D. Zeiler and Rob Fergus : Visualizing and understanding convolutional networks)
위의 이미지는 Convolution과 Deconvolution과정을 나타내고 있습니다.
Deconvolution 과정은 Unpooling → ReLU → Filtering 의 3단계로 나누어져 있습니다.
각 과정에 대해 아래에 좀 더 설명하도록 하겠습니다.
Unpooling
Max pooling 과정은 가장 강한 자극만 남고 나머지 정보는 소실되는 비가역적인 연산입니다.
따라서 ZFNet에서는 switch에 가장 강한 자극의 위치 정보를 저장해놓고, unpooling을 실행할 때 switch정보를 활용하여 가장 강한 자극의 위치를 찾아갈 수 있도록 하였습니다.
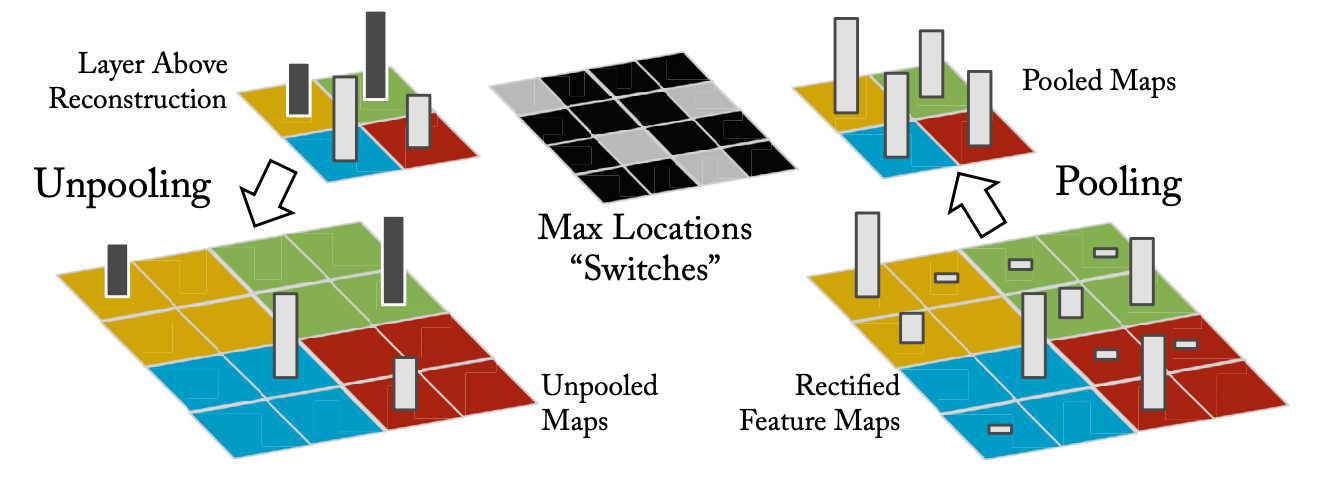
(image source - Matthew D. Zeiler and Rob Fergus : Visualizing and understanding convolutional networks)
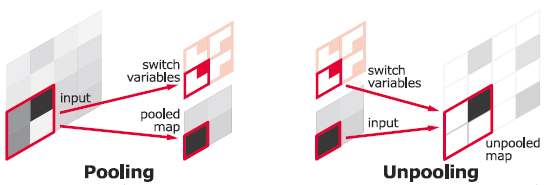
(Image source - https://towardsdatascience.com/review-deconvnet-unpooling-layer-semantic-segmentation-55cf8a6e380e)
ReLU
Convolution 과정에서 ReLU를 거치면서 양수인 부분은 그대로 남아있지만, 음수값은 0이 되어버려 되돌릴 수 있는 방법이 없습니다. 하지만 논문에서는 그 영향이 미미하다고 언급했습니다.
Filtering (Deconvolution)
Convolution 과정에서는 이전 layer에서 넘어온 feature map을 convolution 하기 위해 학습 된 커널(필터)을 사용합니다. 이를 역연산 하기 위해 커널(필터)들을 Transpose하여 Deconvolution을 실시합니다.
예를 들어 padding = 0, stride = 1로 3x3 kernel을 4x4 input에 적용시킬 때, 행렬로 나타내면 다음과 같습니다.
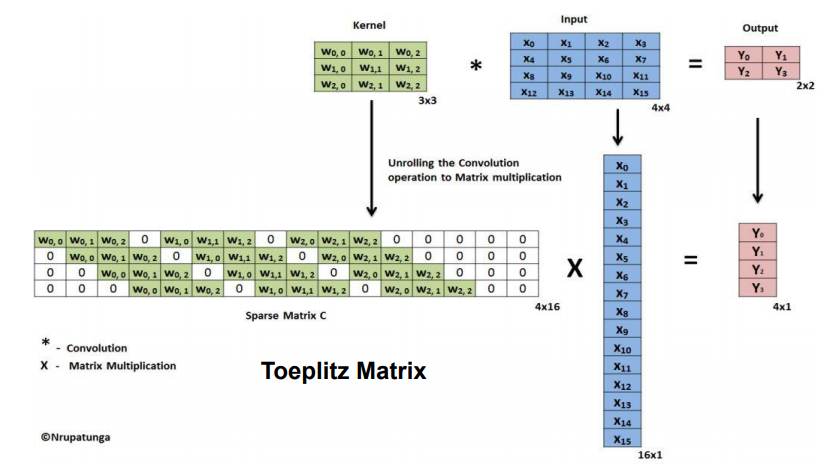
위의 4x16 행렬을 Transpose하여 2x2의 output과 연산하여 아래와 같이 기존의 input feature map을 만들어냅니다.
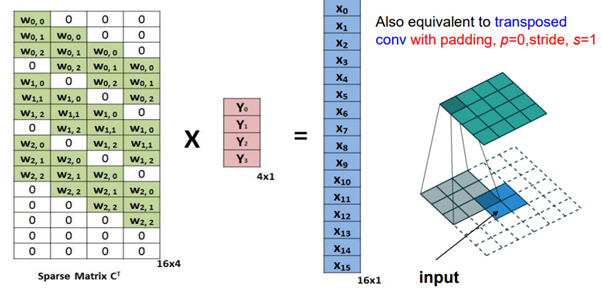
(image source - https://analysisbugs.tistory.com/104)
Training Details
- ZFNet에서는 위에서 언급한 대로 AlexNet을 기반으로 구현되었습니다.
단, 2개의 GPU로 나누어서 학습한 구조때문에 피치 못했던 Layer 3, 4, 5의 sparse connection을 dense connection으로 변경하였습니다. 또한 Layer 1, 2는 다음의 visualization를 검사한 이후 이루어 졌습니다.

(image source - Matthew D. Zeiler and Rob Fergus : Visualizing and understanding convolutional networks)
- ImageNet 2012 Dataset을 기반으로 학습되었습니다.
- Input image는 가로, 세로의 짧은 길이를 기준 256크기로 resize후, 256x256 으로 center crop을 진행합니다. 이후 각 이미지를 five_crop, horizontal flip한 10개의 224x224 크기로 sub-cropping 합니다.
- Minibatch size = 128, SGD 기법으로 학습을 진행하였습니다.
- Iitial learning rate = 0.01, momentum = 0.9 으로 설정하고, validation error를 측정하여 learning rate를 annealing 하였습니다.
- Layer 6, 7(hidden FC_layer) 에서 dropout 0.5 비율로 시행하였고, 모든 weights=0.01, bias=0 으로 initialize 하였습니다.
- 학습 도중 Layer 1 의 filter를 시각화 하면 일부가 dominate 하는 것을 확인할 수 있는데, RMS value가 일정 값을 넘기는 layer의 filter를 re-normalize하여 해결하였습니다.
- GTX580 GPU로 12일에 걸쳐 70epochs 학습 후 종료하였습니다.
Visualization results
ZFNet은 AlexNet처럼 5개의 Convolution layer를 가지고 있습니다.
따라서 지금부터는 각 feature map의 가장 강한 특징 9개를 시각화 한 결과를 보입니다.
Layer 1, 2
Layer 1, 2 에서는 Color, Edge, Corner와 같은 Low level feature들을 추출하는 것을 알 수 있습니다.

(image source - Matthew D. Zeiler and Rob Fergus : Visualizing and understanding convolutional networks)
Layer 3
Layer 3 에서는 Layer 1, 2 와 달리 좀 더 High level feature로 사물의 texture나 어느 정도의 물체를 추출 할 수 있다는 것을 알 수 있습니다. 이를 보면 layer가 깊어질수록 더 세밀한 특징들을 잡아낸다는 것을 알 수 있습니다.
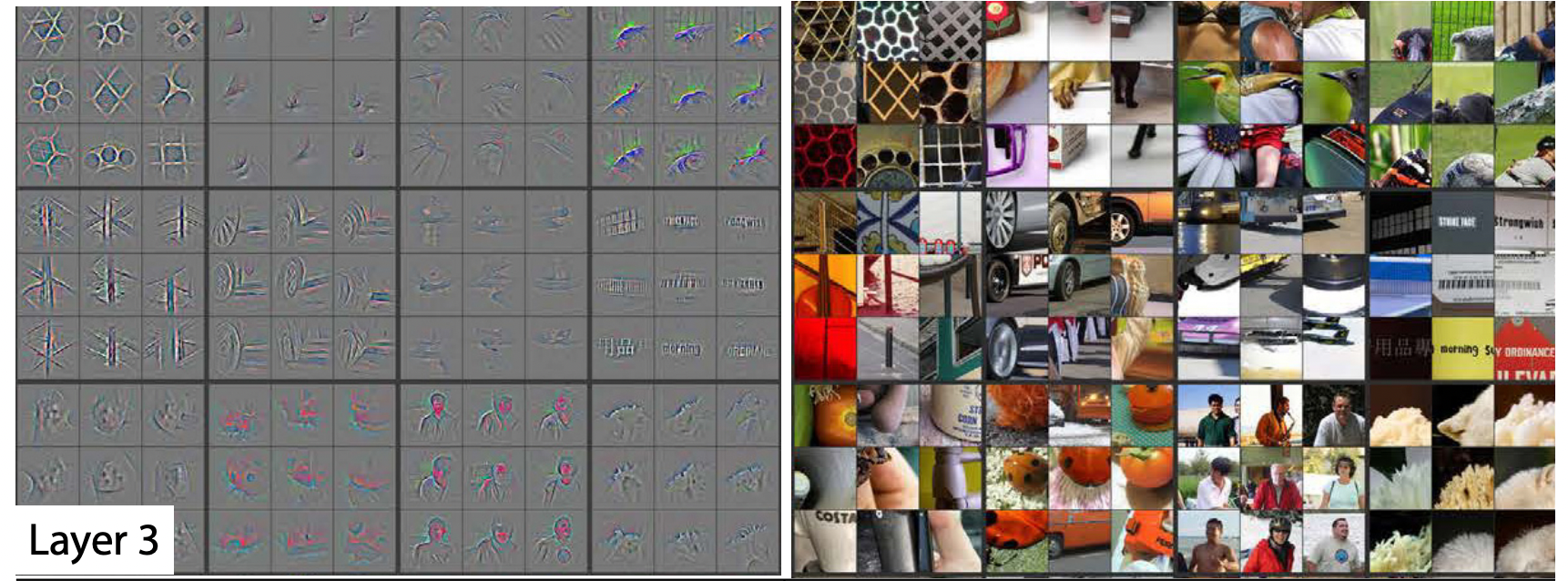
(image source - Matthew D. Zeiler and Rob Fergus : Visualizing and understanding convolutional networks)
Layer 4, 5
Layer 4 에서는 사물이나 개체의 일부분을 보여주는 feature를 시각화 할 수 있고,
Layer 5 에서는 사물이나 개체의 위치 및 자세변화를 포함하는 전체 모습을 시각화 하고 있습니다.

(image source - Matthew D. Zeiler and Rob Fergus : Visualizing and understanding convolutional networks)
Architecture
ZFNet은 AlexNet과 달리 하나의 GPU를 사용했습니다.
아래에 보이는 그림과 같이 AlexNet과 유사한 흐름이지만 구조적으로 다른 부분이 있습니다.
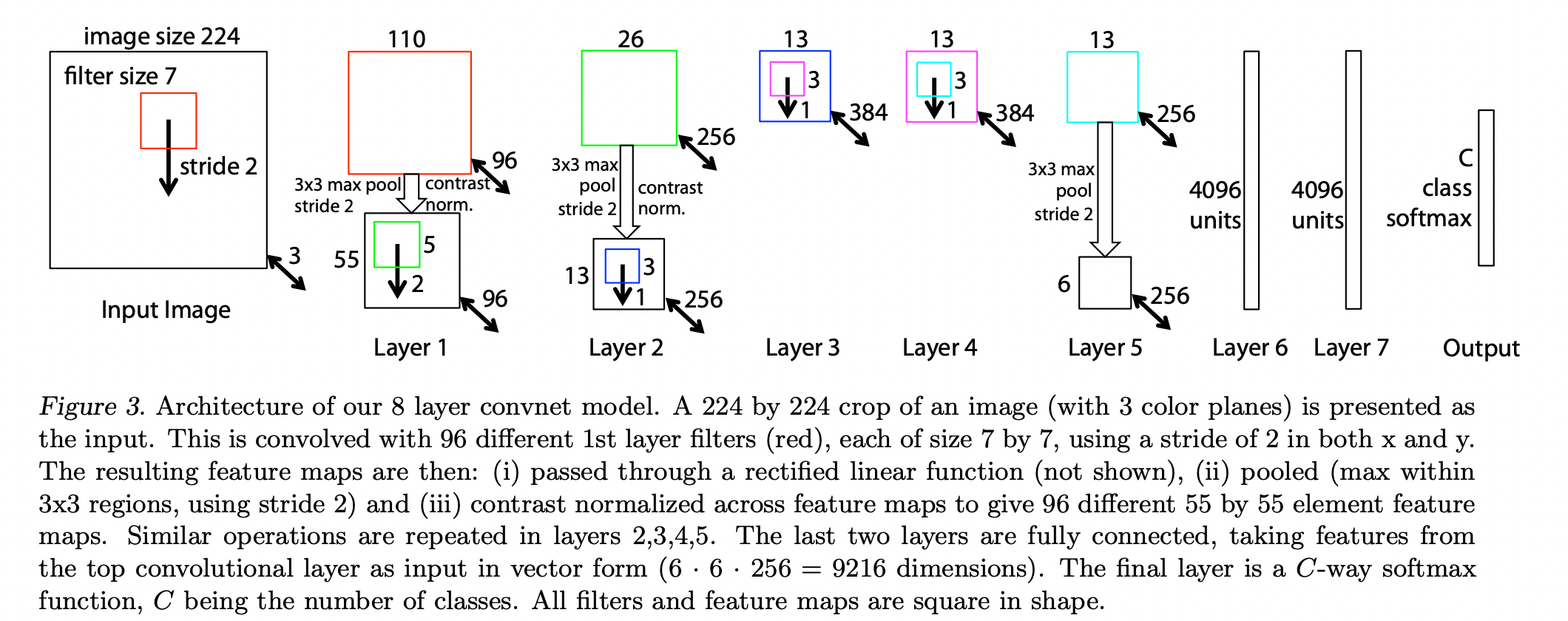
(image source - Matthew D. Zeiler and Rob Fergus : Visualizing and understanding convolutional networks)
Layer 1, 2
Layer 1, 2에서 Filter와 Stride를 줄였을 때, 더 선명하고 다양한 Filter를 얻을 수 있었습니다.

(image source - Matthew D. Zeiler and Rob Fergus : Visualizing and understanding convolutional networks)
따라서 ZFNet에서는 Layer 1, 2에서 다음과 같은 Filter, Stride 구조를 사용했습니다.
- Layer 1
- 7x7 Filter, Stride 2
- Layer 2
- 5x5 Filter, Stride 2
Layer 3~7
다음은 Layer 3~7의 paremeter들을 변경하며 테스트한 결과입니다.
위에서처럼 변경된 Layer 1, 2 를 사용한 경우가 Our Model입니다.
Layer 3, 4, 5의 크기를 각각 384, 384, 256에서 512, 1024, 512로 변경했을 때 더 나은 성능을 보였으나,
FC layer인 Layer 6, 7의 사이즈를 동시에 늘렸을 때는 오히려 Overfitting이 발생해 더 낮은 성능을 보이게 됨을 알 수 있습니다.
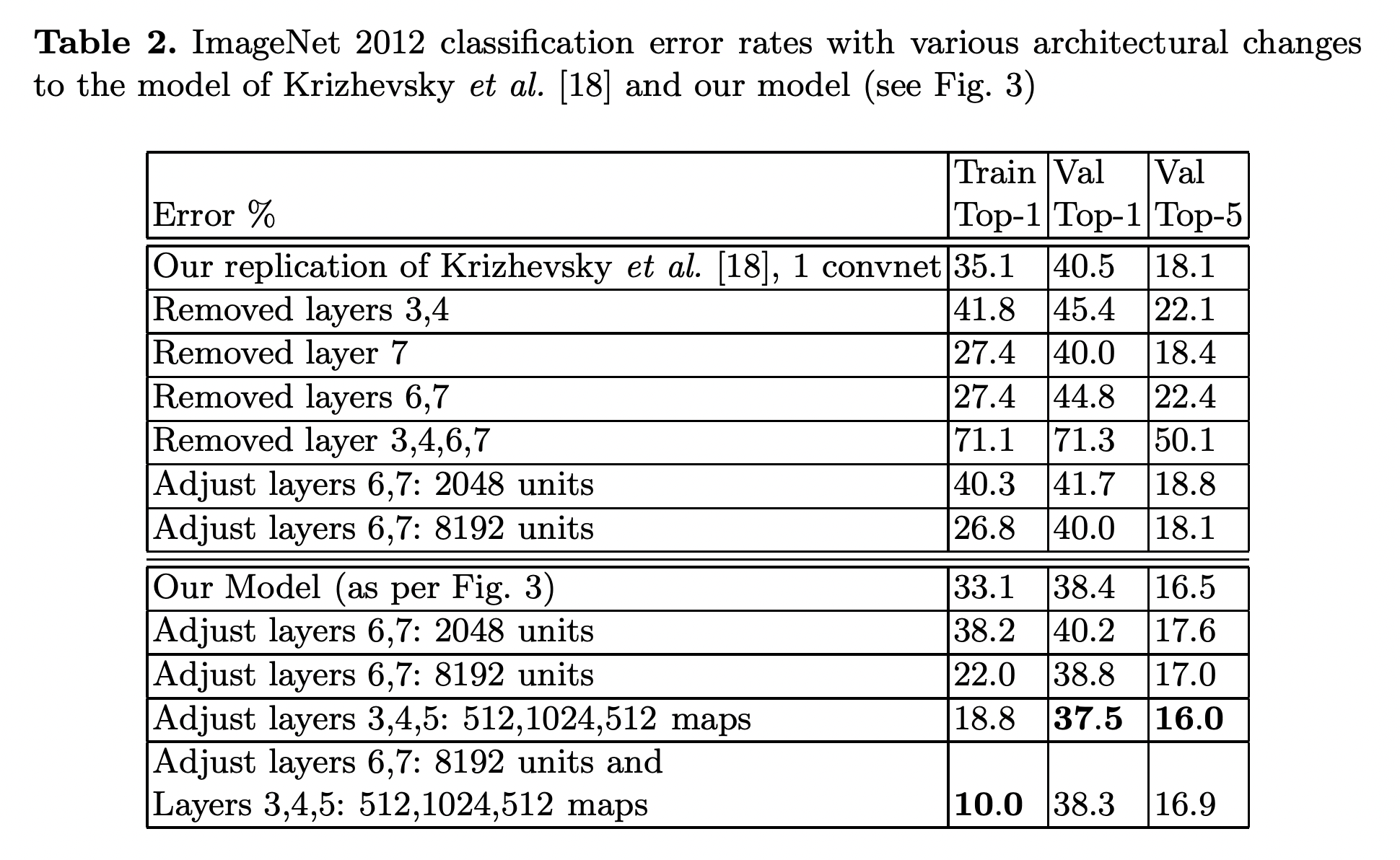
(image source - Matthew D. Zeiler and Rob Fergus : Visualizing and understanding convolutional networks)
Analysis
Feature visualization
아래 그림은 training 과정 동안 가장 강한 activation의 변화를 나타낸 것입니다.
비교적 낮은 Layer 1, 2, 3 에서는 몇 안되는 Epochs 만에 Feature가 수렴하는것을 볼 수 있습니다.
반면 Layer 4, 5 와 같은 높은 layer에서는 약 40 Epochs 이후에나 Feature들이 수렴하는 것을 볼 수 있습니다.
이를 통해 Layer 별로 Feature를 슥듭하는 시간이 다름을 알 수 있습니다.

(image source - Matthew D. Zeiler and Rob Fergus : Visualizing and understanding convolutional networks)
Feature Invariance
- a, b, c는 5개의 이미지를 vertical translation(a), scale(b), rotation(c) invariance 한 것 입니다.
- Column 2, 3은 각각 Layer 1, 7 의 Original image와 Transformed image의 Feature vector끼리의 Euclidean distance를 나타낸 것입니다.
- Column 4는 Transformed image의 True label 확률을 나타낸 그래프 입니다.
작은 변화는 Layer 1에서는 큰 영향을 주지만, Layer 7에서는 비교적 그렇지 않습니다.
네트워크의 Output은 vertical translation(a), scale(b) 에 대해서는 비교적 stable 합니다.
일반적으로 rotation(c)에 대해서는 invariant 하지 않습니다. 하지만 이미 회전대칭인 entertainment center(보라색 line)와 같은 경우는 제외합니다.
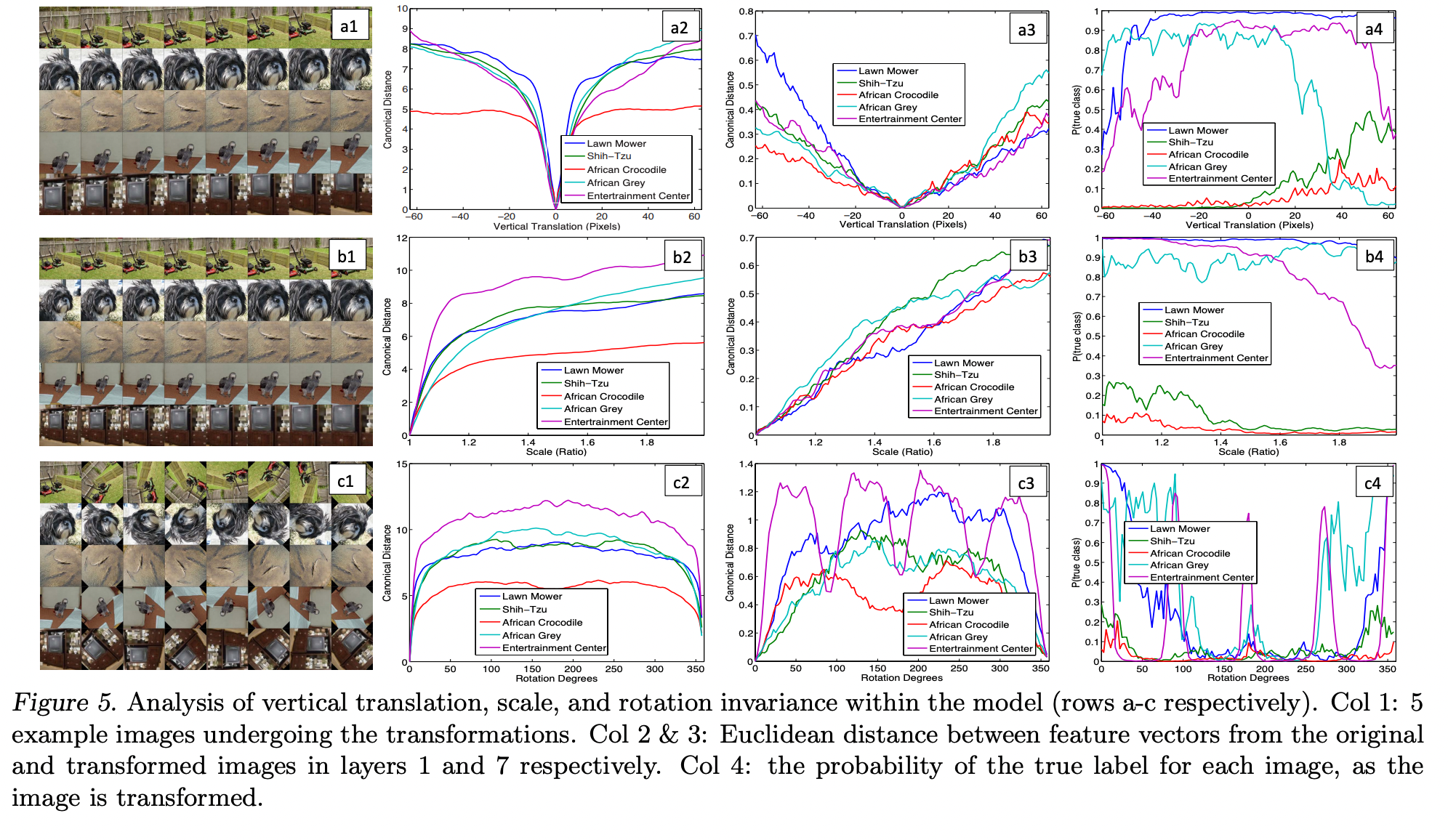
(image source - Matthew D. Zeiler and Rob Fergus : Visualizing and understanding convolutional networks)
Occlusion Sensitivity
ZFNet의 저자들은 CNN이 개체의 정확한 위치까지 파악을 해준다는 사실을 밝혔습니다.
이를 확인하기 위해 개체의 일부 영역을 회색 박스로 가리고 학습을 진행하였고, 이를 통해 물체를 가리면 그 물체를 제대로 분류해 낼 가능성이 떨어지는 것을 통해 이를 역으로 확인하였습니다.
- (a)는 실험에 사용한 이미지 입니다. 회색 박스의 위치를 옮겨가며 학습을 진행하였습니다.
- (b)와 (c)는 Layer5 에서 가장 강한 actiavation에 대한 heatmap과 feature map을 나타낸 것입니다.
- (d)와 (e)는 Classifier의 출력값을 나타낸 것입니다.
첫번째 행을 예시로, 회색 박스로 강아지의 얼굴을 가렸을 때, (b)에서 activation이 떨어지게 나타나는 것을 알 수 있습니다. (c)에서 검은 사각형으로 강조된 그림은 가장 강한 activation을 input 공간에 mapping 시켰을 때를 보여줍니다. (d)는 Classifier의 출력에 대해 특정 위치를 가렸을 때, 제대로 검출이 가능한가를 확률적으로 나타낸 것이고, (e)는 가리는 영역에 따라 ZFNet의 분류가 어떻게 달라지는지를 보여주게 됩니다.
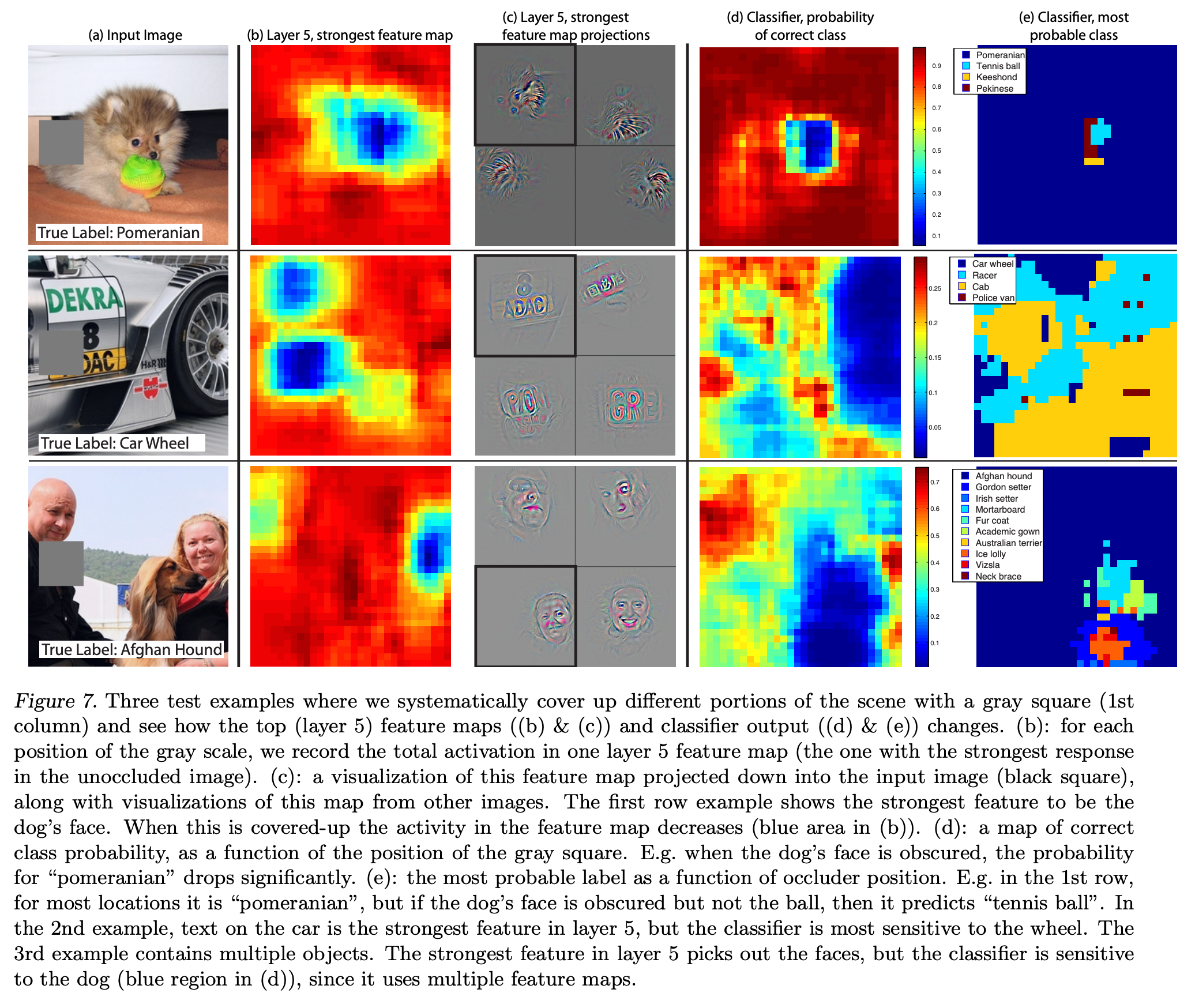
(image source - Matthew D. Zeiler and Rob Fergus : Visualizing and understanding convolutional networks)
결론
이렇게 Visualizing 기법을 이용해 각 Layer의 Feature map의 분포를 살펴 학습에 설정 된 Hyperparameter 들이 적절한 값인지 판단할 수 있고, 또 다른 여러 구조의 적절성에 대한 insight를 얻을 수 있음을 논문을 통해 확인하였습니다.
