NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis 논문 학습 정리
Papars-Vision
NeRF로 유명한 다음의 논문을 읽고 학습한 내용입니다.
공부하며 작성한 내용이니 틀린부분 지적해 주시면 감사하겠습니다!
Papers: 논문 링크
이 글의 이미지는 모두 위 논문을 출처로 가져온 이미지 입니다.
NeRF 란?
Scene Representation 분야의 붐을 일으킨 논문으로,
이전에 썩 좋은 성능을 보여주지 못하고 있던 View Synthesis task에 대해 새로운 방식이 제안되었습니다.
Neural Radiance Fields(NeRF)는 scene을 합성하고, 표현하는데에 있어서 Neural net을 사용한 아이디어로,
scene 표현 방식 또는 네트워크 자체를 의미합니다.
이후 이 논문의 후속작들이 쏟아져 나왔을 만큼 훌륭한 논문으로 알려져 있습니다.
아이디어
불연속적인 시점으로 찍어놓은 이미지를 이용해 NeRF를 학습시키면
Object 또는 해당 Scene 자체를 학습하여
training dataset에서 넣어주지 않았던 새로운 random view에 대해서도 표현할 수 있습니다.
위의 과정을 그림으로 표현하면 다음과 같습니다.

전체적인 구조를 아주 간단하게 표현하면,
Input으로 5D차원의 위치정보 와 viewing direction 를 넣고,
NeRF의 deep fully-connected layer를 통과시켜
픽셀의 RGB와 Density를 output으로 받아 rendering합니다.
이렇게 기본적인 아이디어나 구조 자체는 간단합니다.
이 논문에서는 이 구조를 학습이 가능하도록 하는 몇가지 방법들을 자세히 설명합니다.
자세한 내용에 앞서, 몇가지 정리를 하겠습니다.
Ray는 공간상에서 점 하나와 각도를 정해 그려진 직선 위 object들의 파티클 개념입니다.
NeRF는 이 ray위의 점들 중 sample을 뽑아 네트워크로 학습시켜 한 픽셀의 RGB와 density를 구합니다.
Density는 투명도의 역수 개념으로 density가 높을수록 해당 점에서의 color를 더 많이 반영하게 됩니다.
기본적으로 네트워크 하나를 통과하면 Ray 하나에 대한 output이 나옵니다.
(물론 이를 batch로 붙여 학습합니다.)
Neural Radiance Field Scene Representation
NeRF의 학습 과정에 대해 다시 훑어 보겠습니다.
-
우선 간단한 좌표 변환을 통해 직육면체 부피로 제한합니다.
-
이 안에서 object의 한 점과 카메라의 각도가 정해지면,
이 5D input 좌표 가 Position + Direction으로 들어갑니다. -
그럼 네트워크는 Ray위의 샘플링 된 점들에 대해 각각 Color와 Density 값을 뽑아냅니다.
-
이 값들은 Volume Rendering 기법으로 하나의 픽셀로 변환됩니다.
-
이렇게 픽셀을 합성하면 해당 픽셀과 Ground-Truth 값을 비교하여 Loss를 계산하고,
이 Loss를 backprop하여 네트워크를 업데이트 합니다.
(참고로 한 시점에서 찍어낸 이미지의 픽셀값을 넣을 것이기 때문에 Ground-Truth를 복셀(voxel)로 가질 필요는 없습니다.)
Volume Rendering은 Image Rendering 분야에서 보편적으로 쓰이는 기법으로,
이는 미분 가능한 연산이므로 학습에 문제가 되지 않습니다.
위의 과정을 나타낸 그림은 다음과 같습니다.
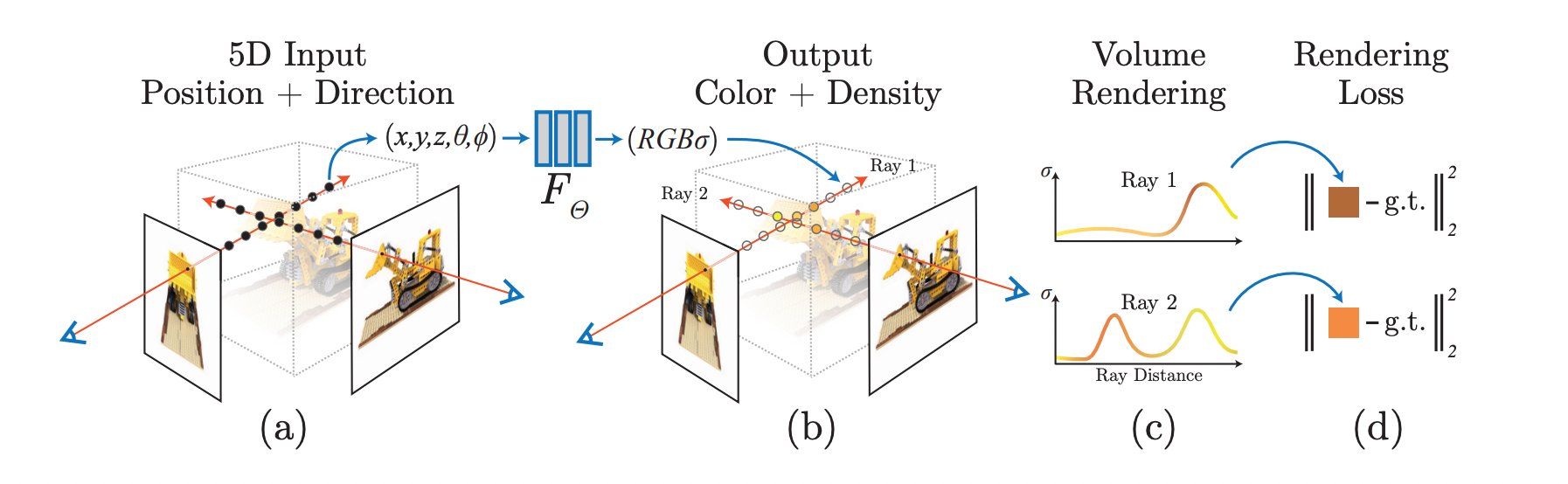
이때 Color는 location과 viewing direction 모두에 관계있는 값이고,
Density는 location에만 관련된 값입니다.
이렇게 설정 함으로써 다음 그림과 같이 Ground-Truth 값에 대해 방향에 따라 빛이 반사되어 하얗게 보이는 표면까지 표현할 수 있습니다.

또한 고정된 한 점에 대해 view 위치를 바꿔가며 찍었을 때, 연속적인 color 변화를 표현할 수 있게 됩니다.
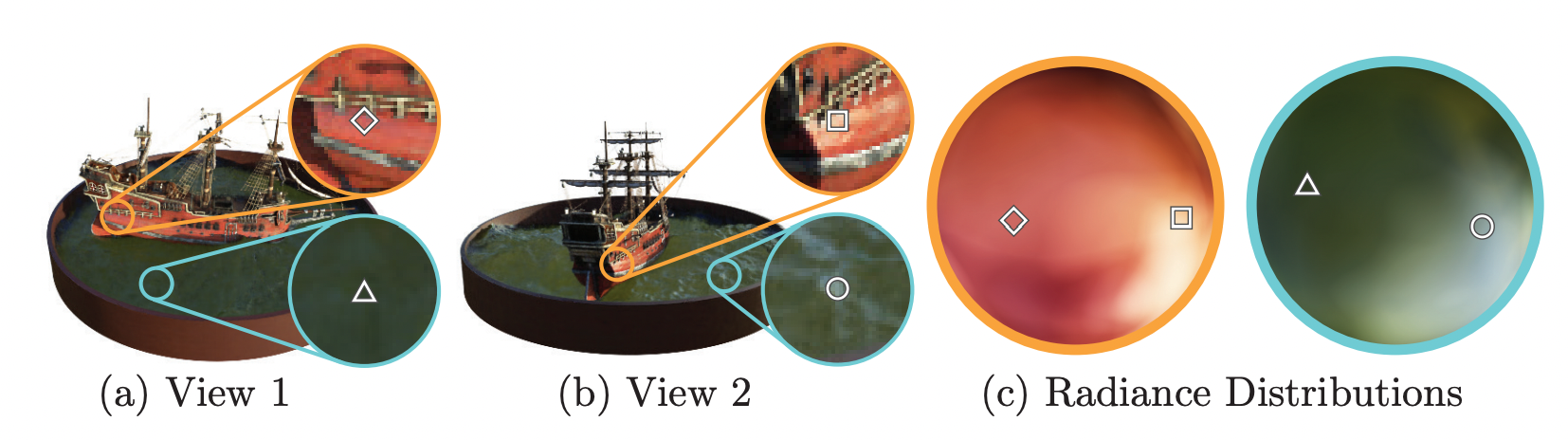
뒤에서 네트워크 구조를 볼 때 다시 한번 언급하도록 하겠습니다.
Volume Rendering
메인 아이디어는 위와 같이 간단합니다.
따라서 이 논문에서는 어떻게 학습을 잘 시키는 지에 대한 내용이 더 중요한 것 같습니다.
그 전에 샘플링 된 점들로부터 하나의 픽셀을 rendering 하는게 와닿지 않을 수 있는데,
이 논문에서도 volume rendering에 대해 좀 더 자세히 설명하고 있습니다.
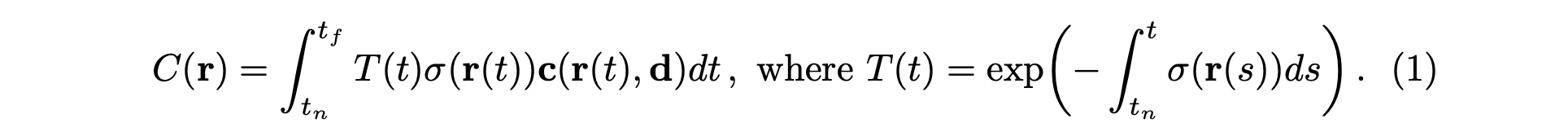
- : 이미지 픽셀 값
- : RGB 값
- : Density 값
- : 원점에 대해 방향벡터로 표현한 Ray
( 에서 값에 따라 샘플링 된 점들의 위치가 결정)
위 식의 (RGB color)에 대해 (density)를 확률로 볼 수 있습니다.
즉, 를 확률 변수, 를 확률 이라 하면, 이 둘의 기댓값으로 해당 픽셀의 값을 계산 할 수 있습니다.
해서 (density)값이 클수록 (RGB)값을 많이 반영하는 구조가 되는데,
이때 transmittance라는 개념이 추가됩니다.
Transmittance는 ray가 시작하는 부분부터 현재 보고있는 까지의 density값을 합쳐서 음수로 exponential에 올린 함수입니다.
이것은 앞의 sample들의 density값이 누적 되어 이 값이 클 수록 뒤는 안보인다는 개념을 반영합니다.
위의 적분을 quadrature하게 근사하기 위해 sampling 개념을 사용합니다.
단순하게 ray를 등분하여 sampling 하면, 한정된 공간에서 한정된 점들만 학습하게 됩니다.
따라서 연속적인 점들을 학습하게 하기 위해, 이 논문에서는 stratified sampling 기법을 사용합니다.
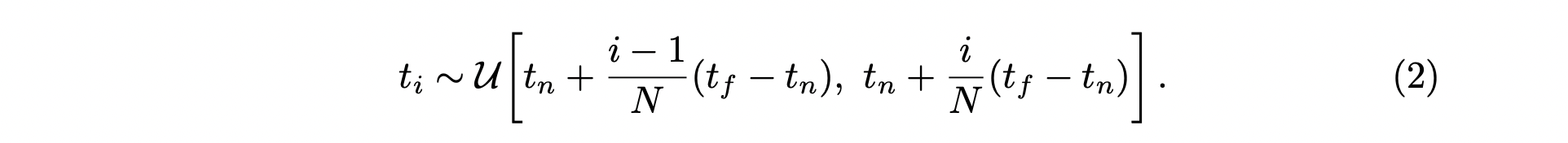
Stratified sampling은 박스의 시작하는 점 부터 끝나는 점 까지를 개의 bin으로 나누고,
각 bin 안에서 한 점을 random하게 sampling하는 방법입니다.
이렇게 하면 학습할 때 마다 sampling되는 점들이 달라지므로 연속적인 값에 대해 학습할 수 있습니다.
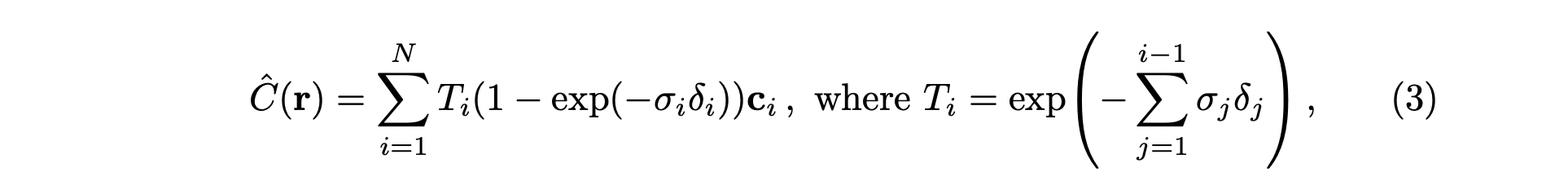
(1) → (3) 식으로 넘어올 때, density값이 변한걸 볼 수 있는데,
이것은 1995년에 발표된 다른 논문
(Max, N.: Optical models for direct volume rendering. IEEE Transactions on Visualization and Computer Graphics (1995))
에서 가져온 것으로 랜더링하는 쪽에서 흔하게 쓰이는 식으로 예상하고 넘어가도록 하겠습니다.
이렇게 volume rendering 기법을 통해서 sample들의 RGB color, Density 값으로부터 이미지의 한 픽셀값을 합성할 수 있음을 볼 수 있습니다.
Positional Encoding
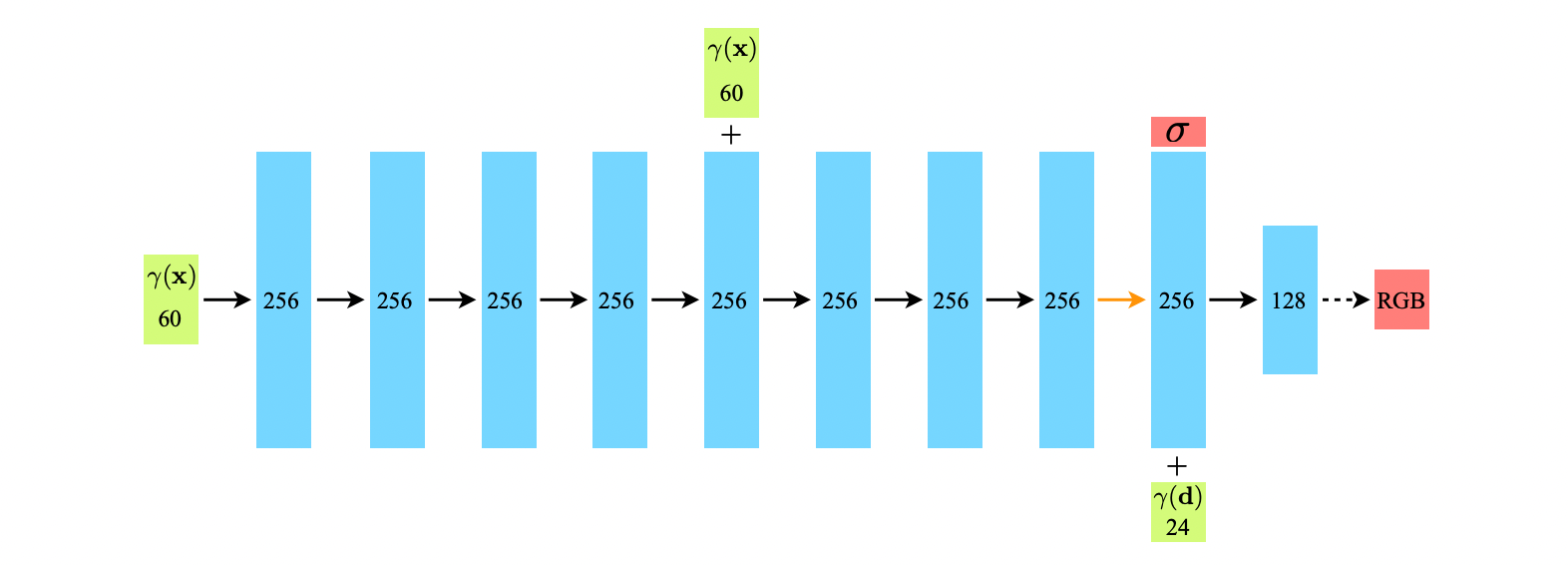
위의 그림에서 보는 것처럼, Neural net은 5D input으로 RGB, density값이 나오는 것이므로 굉장히 simple합니다.
단순히 fully-connected layer를 쭉 연결한 모습임을 알 수 있습니다.
이때 그냥 단순히 5D input을 MLP에 넣어주게 되면,
정보가 부족해서 information pumping이 잘 되지 않아 high frequency를 학습하기 좋지 않습니다.
이 문제를 해결하기 위해 positional encoding 기법을 이용합니다.
positional encoding은 high frequency 영역까지 표현할 수 있게 해주는 개념으로,
식은 다음과 같으며 자세한 내용은 신호처리와 푸리에 변환(Fourier transform, FT)등을 따로 찾아보면 좋습니다.

은 입력 데이터 의 각 원소 와,
를 통과하는 camera ray의 unit vector 의 원소 를 모두 적용하여 해당 값들을 [-1, 1]범위에서 normalize 합니다.
이렇게 하면 정보의 양을 늘릴 수 있습니다.
논문에서는 for , 그리고 for 로 설정하였습니다.
( 이면 해서 총 20개, 그리고 location값을 다 넣으면 60개의 차원이 나옵니다)
Neural net 중간에 positional encoding 벡터를 한번 더 넣어주고, 쭉 가다가 density값을 먼저 뽑아냅니다.
이는 위에서 언급한대로 density 값은 location 에만 의존하는 값이기 때문입니다.
거기에 viewing direction에 대한 positional encoding 벡터를 넣어서 한번 더 layer를 거쳐 RGB값을 뽑아냅니다.
계속해서 간단한 개념과 네트워크를 잘 학습시키기 위한 방법들입니다.
Hierarchical volume sampling
위의 stratified sampling 에서 random으로 sampling을 하면
각 학습마다 다른 sample을 사용하면서 연속적인 값들을 얻을 순 있지만, 비효율 적인 부분이 나타나게 됩니다.
camera ray가 통과하는 공간 중 object가 존재하는 sample이 뽑힌다면 운이 좋았지만,
그렇지 않은 경우 정보가 없는 빈 공간으로 학습하고 렌더링 하게 되기 때문입니다.
따라서 object가 있을 것으로 추정되는 구간에 좀더 집중해서 sampling을 할 수 있도록
hierarchical volume sampling 기법을 사용합니다.
이를 위해 논문에서는 coarse network, fine network의 두 네트워크를 사용하였습니다.
위에서 stratified sampling을 가지고 한번 학습을 시킨 network를 coarse network 라고 합니다.
이 coarse network로부터 더 많은 정보를 얻을 수 있는,
즉 density값이 크게 나온 부분에 대해 더 잘게 다시 한번 sampling을 합니다.
이렇게 하기 위해서 식 (3) 에서 alpha composited color를 구했던 을 아래와 같이 의 weighted sum으로 재정의 합니다.

그리고 위의 weights를 다음과 같이 normalize하면,
piecewise-constant한 PDF가 된다고 합니다.
그리고 이로부터 inverse transform sampling을 사용해 fine network를 위한 개의 sample을 뽑아냅니다.
이 sample들로 다시 학습을 시켜 fine network를 만들어 냅니다.
최종 결과물은 coarse network의 개와 fine network의 개를 전부 넣어서 만들어 냅니다.
Implementation details
마지막으로 NeRF를 구성하는 detail한 요소들에 대한 내용입니다.
매 epoch마다 camera ray를 random sampling하고,
정해진 camera ray위의 점들을 hierarchical sampling하여 sample을 뽑아냅니다.
그렇게 나온 sample들을 이용해 coarse, fine networks를 통과시켜 volume rendering을 통해 픽셀을 합성하고 Loss를 계산하게 됩니다.
Loss는 간단하게 개에 대한 total squared error를 사용합니다.
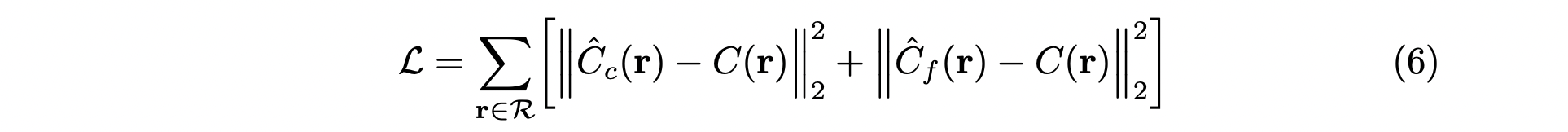
논문에서는 로 fine network에서 더 큰 sampling을 하는 것이 좋다고 합니다.
Result


결과로서 이전의 scene 합성 기법들과 비교했을때,
고스트 이미지도 없고, ringing effect(일렁이는 부분)도 없고,
occluded regions(T-Rex 이미지에서 갈비뼈 사이 뒤의 난간 같은 부분)도 더 잘 표현한다고 합니다.
NeRF의 단점으로는 학습이 매우 오래 걸립니다.
한 scene에 대해 NVIDIA V100 GPU를 사용해도 하루에서 이틀정도 걸리는 것을 보아,
실시간으로 사용하기는 불가능한 점이 있습니다.
이런 단점을 극복하기 위해 FastNeRF, pixelNeRF, NeRF++ 처럼 속도를 개선하는 후속작들이 많이 나온 것으로 보입니다.
