[CV] Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition
PaperReview
기존 합성곱 신경망의 한계점이었던, 고정된 크기의 인풋 문제를 해결했다.
연산량이 줄어 속도를 향상 시켰다.
Abstract
기존의 합성곱신경망은 고정된 인풋이미지를 필요로 했다.
합성곱 신경망의 안쪽에 있는 FC Layer에 고정된 크기의 인풋이 필요하게 때문.
이 요구사항은 자체로 인공적일 뿐아니라 이미지의 공간적인 사이즈/스케일에 대한 인지 정확도가 감소될 수 있다.
저자들은 이를 해결하기 위해 다른 pooling 전략을 사용했고 ‘spatial pyramid pooling이라 명명한다.
이를 사용한 SPP-Net은 인풋 이미지의 사이즈에 상관없이 고정된 길이의 표현을 만들어낸다.
객체 변형에도 견고한 모습을 보인다고 한다.
Imagenet 2012 dataset에서, 다양한 CNN 구조에 대한 성능 향상을 나타냈다.
VOC, Caltech101 데이터셋에서 파인튜닝을 하지 않고, Single-Full-Image(이미지 크기의 변형 없이)를 사용해 소타 성능을 보였다.
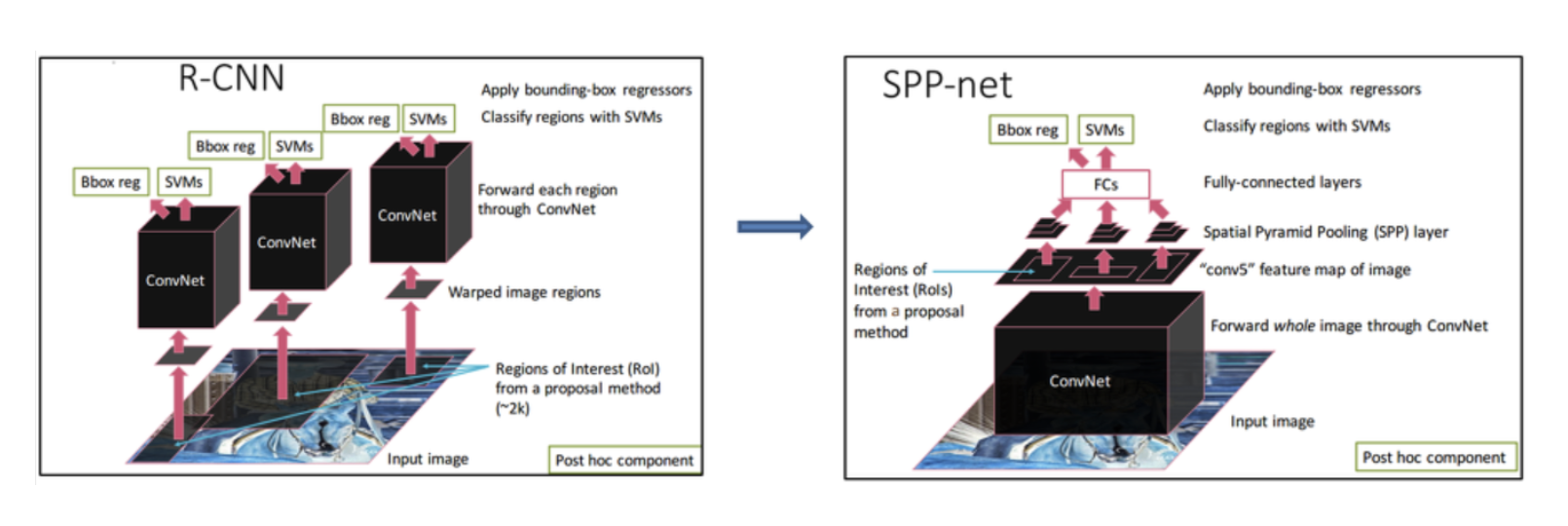
Object Detection에서도 좋은 성능을 보인다.
기존 RCNN 구조의 탓에, RCNN에서는 Resion Proposal로 2000개의 Candidate Bounding Box를 추출해 각각에 대해 합성곱 연산을 수행했다.
위 그림의 왼쪽을 참고하면 되겠다.
SPP-Net은 전체 이미지에서 합성곱 신경망을 먼저 수행하고, 추출된 Feature Map을 바탕으로 Candidate Bounding Box를 추출한다.
RCNN의 반복적인 합성곱 계산을 피할 수 있기 때문에 연산량에서 차이가 발생한다.
Introduction
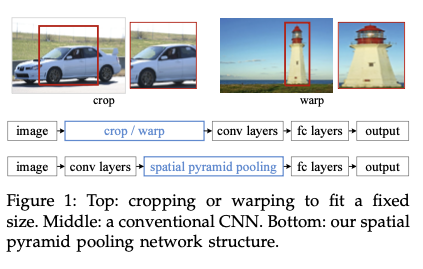
기존의 합성곱 신경망은 고정된 크기의 인풋 (ex 224 x 224)를 필요로 하기 때문에, 원본 이미지에서 crop, wrap 등의 작업이 요구된다.
이는 전체 객체를 표현하지 못할 수도 있고, geometric한 왜곡이 발생될 수 있다.
인지 정확도(Recognition Accuracy)에 악영향이 끼칠 수 있겠다.
또한 Pre-Defined Scale(위 예시의 224 x 224)은 다양한 Object Scale에 맞지 않을 수 있다.
Cnn 구조에서 합성곱 레이어는 슬라이딩 윈도우 방식에 따르고 아웃풋 FeatureMap은 공간정보를 반영함. 여기까지는 고정된 크기의 인풋이 필요 없다. 하지만 Fc layer가 고정된 크기의 인풋이 필요하다.
깊은 쪽에 있는 레이어인 fc layer만을 위해 크기 조정이 강제되는 것이 문제가 되겠다.
따라서 본 저자들은 SPP Layer를 만들었고 Spp Layer는 마지막 FC Layer와 연결되어 있다. (Figure 1을 참고)
즉, 시작단계에서 Cropping or Wraping 대신 합성곱 레이어와 Fc layer 사이에 정보의 ‘통합’을 수행하는 것.
그렇다면 어떤 방식으로 FC Layer의 요구사항을 충족시킬 수 있었을까?
-
공간정보의 손실 방지
제안된 Spatial Pyramid 구조는 기존에 존재하던 기법이고, 이는 또 기존에 존재하던 BoW(Bag-of-Words)의 단점을 개선하기 위한 기법이다.먼저 BoW는 특정 영역에 대해 이미지의 주요 Feature들을 뽑아내는 기법인데, FC Layer처럼 공간적 정보가 손실된다는 단점이 있다. 하지만 이미지를 N등분 시킨 뒤 각각에 BoW를 적용하게 되면 지역정보가 어느정도 보존되게 되고, 이를 피라미드 꼴로 구성한 것이 Spatial Pyramid 구조이다.
저자는 이 구조에 영감을 얻어 Max Pooling을 Spatial Pyramid 구조로 변형해 적용했고 FC Layer의 첫번째 한계인 공간정보 손실을 방지했다. -
고정된 크기의 Featur를 전달
FCL의 두번째 한계점은 고정 크기의 입력만을 받을 수 있다는 것이었다. 하지만 마지막 Conv Layer의 Filter 수를 고정시키고, Spatial Pyramid의 계층수와 각각의 분할영역의 갯수도 정해놓는다면, 임의 크기의 이미지로부터 얻어낸 Featu고정된 크기의 Featur를 전달
re Map을 고정 크기로 변환해 FCL에 넘길 수 있다.
SPP-Net의 장점은 다음과 같다.
- spp는 슬라이딩 윈도우 풀링은 할 수 없는, 인풋 사이즈에 상관없이 고정된 길이의 아웃풋을 생성함.
- 다양한 레벨의 spatial bins를 사용하는데, 슬라이딩 윈도우는 한개의 윈도우 사이즈만 가짐. Multi level pooling은 물체 변형에 견고하다는 것이 알려져 있음.
- 인풋 스케일의 유연성 덕분에 다양한 스케일로 추출된 피쳐들을 풀링할 수 있음.
- Test와 Train에서 가변적인 사이즈의 인풋 입력이 가능하므로 스케일 불변성을 증가시키고 오버피팅을 줄임.
- 기존의 CNN design과 직교(orthogonal)한다는 것. 직역하면 직교한다는 표현을 했지만, 호환이 된다는 의미인 것으로 해석했다.
또한, 앞서 미리 소개했듯이 Object Detection에서, 기존 RCNN은 높은 성능을 나타내지만, 시간 소모가 많이 들었다.
SPP-Net은 전체 이미지에 대해 단 한번의 합성곱연산을 거치기 때문에. 이는 많은 시간 단축의 효과를 가져왔다.
즉, Spp net은 기존 CNN구조의 피쳐맵의 강점을 이용할 뿐 아니라 가변적인 윈도우 사이즈에서 유연한 SPP 덕분에 성능과 효율성이 좋다.
2 DEEP NETWORKS WITH SPATIAL PYRA- MID POOLING
2.1 Convolutional Layers and Feature Maps

일반적으로, 합성곱 레이어는 슬라이딩 필터를 사용해 아웃풋을 만들어내고, 이는 대략적으로 인풋과 비슷한 비율로 생성된다. 생성된 피쳐맵은 캡쳐된 responses를 나타낼 뿐 아니라 공간적 위치 또한 나타낸다.
필터는 어떤 semantic 한 content에 의해 활성화 된다.
예를 들어 figure2의 55번쨰 필터는 원 모양에 의해 대부분 활성화 된다. 66번째 필터는 시옷모양으로 활성화 된다.
인풋에서 이러한 모양들이 피쳐맵의 상응하는 위치에서 활성화 된다.
즉 특징들이 인코딩되어 피쳐맵에 나타나는 것.
2.2 The Spatial Pyramid Pooling Layer
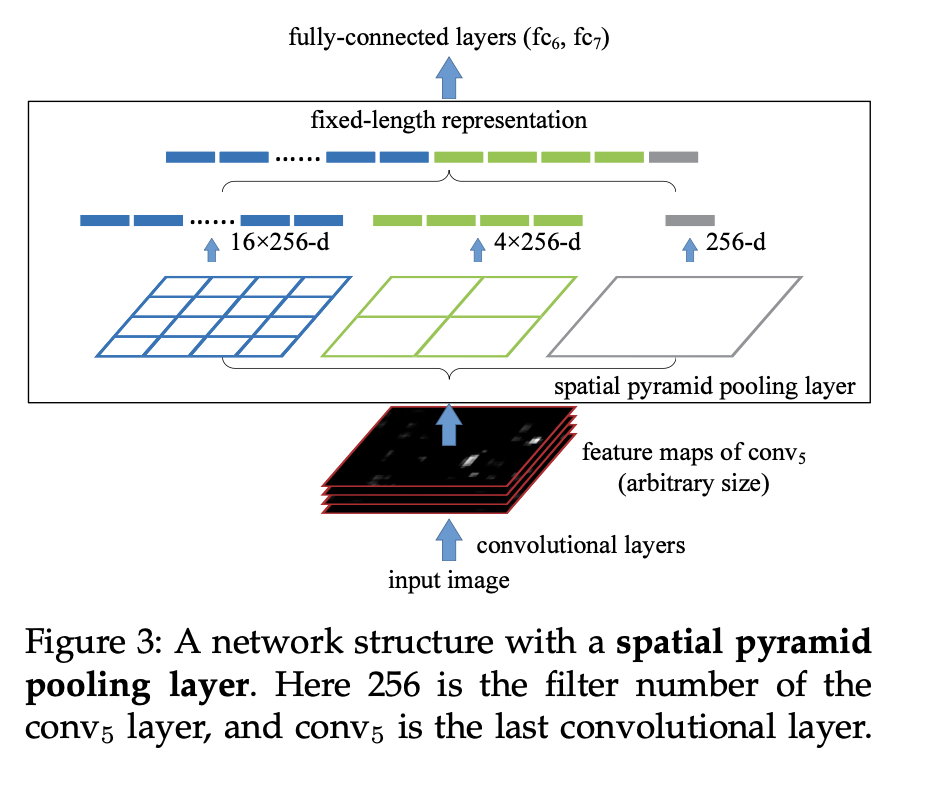
SPPNet의 구조.
5개의 Conv layer, 3개의 FC layer를 가진다.
SPP layer의 경우 Conv5 layer 이후에 위치시킨다.
(FC layer에 고정된 입력 크기로 전달해주기 위해)
Spatial bins의 크기를 조절해 원하는 크기로 FC Layer에 인풋을 전달할 수 있다.
위 그림에서는 인 경우이다.
21 bins의 경우에 3개의 pooling 으로 이루어져있다.
각각의 pooling을 conv5 layer에 적용하여 특징을 추출하고 의 크기를 출력한다.
이를 일렬로 피면 bin의 수(21)가 되는 것이다.
다양한 입력 사이즈를 수용했으므로 합성곱 연산을 거쳐 conv5에서 출력하는 Feature map의 크기도 다양하게 된다.
이때 Spatital Bins를 조절해 다양한 feature 크기에서 pooling의 window size와 stride 만을 조절하여 출력 크기를 결정하는 것이다.
Spp pooling의 아웃풋은 차원이 된다. (은 bin의 숫자, 는 Filter의 숫자)
이후 fc layer로 들어감.
M (bins의 숫자)를 조절할 수 있으므로 원하는 크기의 인풋을 FC Layer에 전달할 수 있다.
2.3 Training the Network
GPU를 사용할 때는 고정된 크기의 인풋이 선호되는데, 다음 내용은 spp를 사용할 때 gpu 수행에서의 이점을 가졌던 방법에 대해서 이야기 하겠다.
Single size training
이미지의 사이즈가 주어졌을 때 spp에 사용될 bin 사이즈를 미리 컴퓨팅할 수 있다.

의 Bin 사이즈를 얻기 위해, 각 pooling의 window size, stride를 지정해야한다.
저자들은 간단한 공식으로 이를 제시한다.
사이즈의 피쳐맵이 있을 때, Bins를 가지는 피라미드 레벨에서, 의 크기의 슬라이딩 윈도우 사이즈를 설정할 수 있다.
위 그림은 13 x 13 feature map에서 3x3, 2x2, 1x1 pooling을 얻기 위해 window size (sizeX), stride를 정하는 예시이다.
3x3 pooling에서는 의 올림인 5를 window size로, 의 내림인 4를 stride로 지정했다.
이런 식으로 bins를 얻기 위해 window size와 stride를 구할 수 있다.
Multi size training
Single size training을 기반으로,
저자들은 학습에서 다양한 이미지 사이즈를 다루기 위해 미리 정한 사이즈들의 set를 사용했다.
테스트단계가 아닌 훈련단계에서 180~224 인풋 사이즈 내에서 무작위 사이즈 s를 사용해 학습에 사용했다고 한다.
최대 크기인 224 사이즈의 인풋을 작은 사이즈로 조절해 set를 만들었다.
따라서 224와 180 사이의 영역은 해상도만 차이가 나고, 내용과 레이아웃에서는 차이를 두지 않았다.
3 SPP-NET FOR IMAGE CLASSIFICATION
3.1 Experiments on ImageNet 2012 Classification
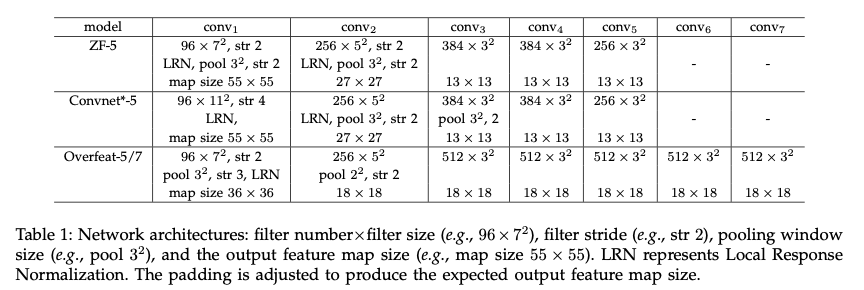
spp는 기존 합성곱 신경망에 사용이 가능하다.
기존 합성곱 신경망 베이스 라인의 구조는 위와 같다.
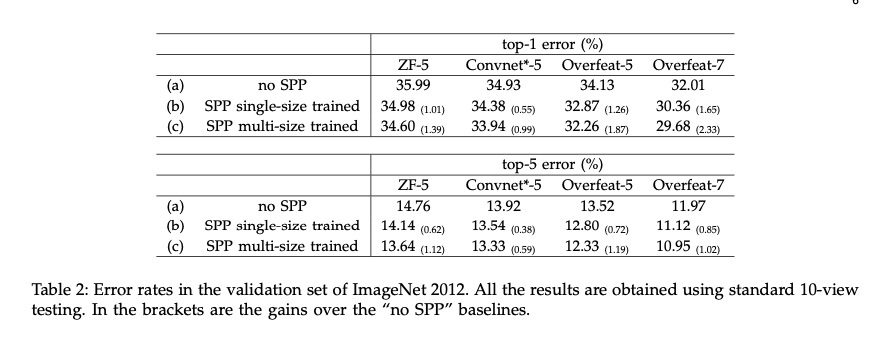
Multi-level Pooling Improves Accuracy
위 표는 기존 베이스라인 모델과 spp를 적용했을 때의 차이점을 보여준다.
여기서 말하는 level은, pooling시의 window size의 다양한 조합을 의미하는 것 같다.
Single level과 베이스라인의 구조차이는, 마지막 합성곱 레이어가 spp layer로 대체된 것인데, 성능 향상을 보인다.
Multi level pooling의 성능 향상은 단순히 파라미터 수가 많아서 그런 것이 아니라 객체 변형이나 spatial layout에서의 다양성에 대해 견고하기 때문이라고 한다.
이를 증명하기 위해 ZF-5에서 30 bin (no spp보다 파라미터 적음)으로 실험했을 때 성능 향상이 나타났다.
Multi-size Training Improves Accuracy
다양한 스케일/사이즈를 다루는 CNN 방법들이 기존에 있었지만, 주로 테스트에 기반한 것들이다.
다양한 사이즈의 인풋에 대해 학습한 것은 저자들이 처음이라 한다.
Full-image Representations Improve Accuracy
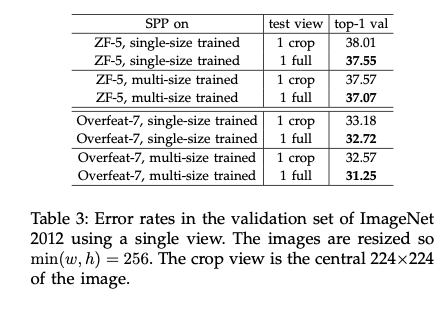
기존 이미지의 비율을 유지한 채 256 사이즈로 실험 (full size) 하고, 중심부에서 224 crop한 것에 대한 실험 결과로, 완전한 content 유지의 중요성을 확인했다.
Multi-view Testing on Feature Maps
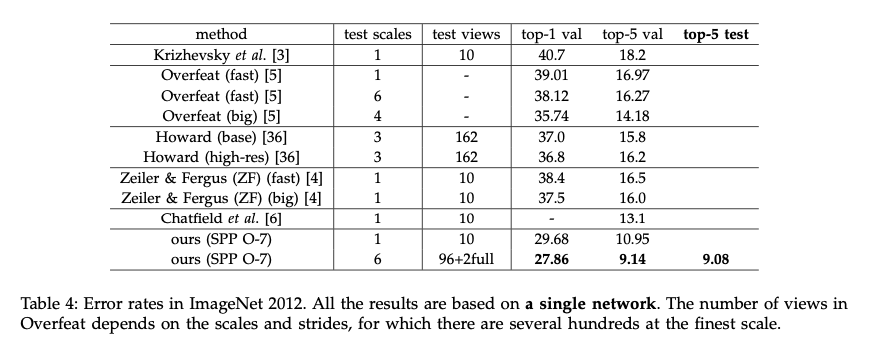
테스트에서 피쳐맵에 대해 multi view 방법을 도입해본 결과.
256 사이즈의 피쳐맵에서 224의 크기로 중심과 코너에서 10 view를 추출
224 256 300 360 448 560의 6 스케일에서 또 view를 추출해 총 96개
거기에 두개의 기존 전체 이미지뷰를 추가해서 테스트한 결과 오류가 줄음 (0.2 정도)
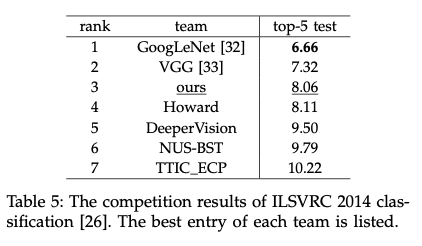
3.2 Experiments on VOC 2007 Classification
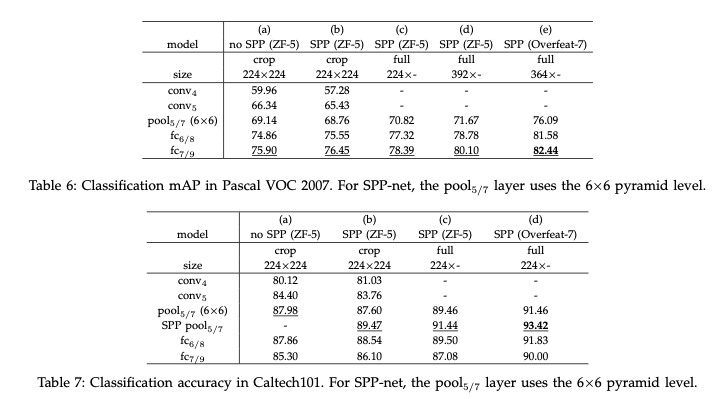
(b)와 (c)에서의 성능 향상을 통해, full size input (Content의 손실이 없는 인풋)의 중요성을 확인했다.
3.3 Experiments on Caltech101
4 SPP-NET FOR OBJECT DETECTION
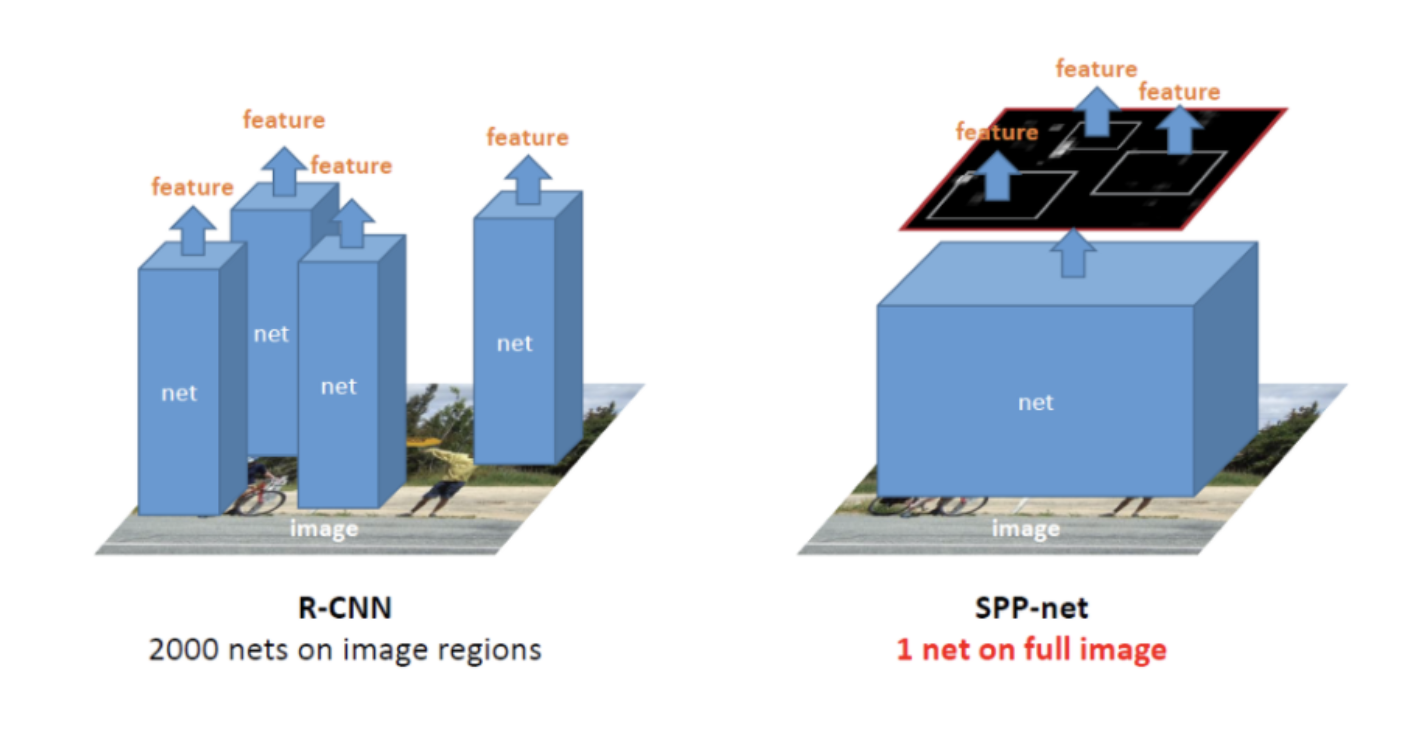
RCNN의 단점으로는, 2000개의 후보 영역에 CNN 연산을 각각 적용해 연산량이 많다는 것이 있다.
4.1 Detection Algorithm
SPP-Net은 먼저 이미지에서 합성곱 연산을 한번 수행하고, 나온 피쳐맵에 selective search를 통해 추출한 후보 영역으로 특징을 추출한다.
feature map에서, Multi scale feature extraction으로 특징을 추출하기 때문에 성능이 향상될 수 있다고 한다.
파인튜닝을 fc layer에만 하기 때문에 빠르다고 한다.
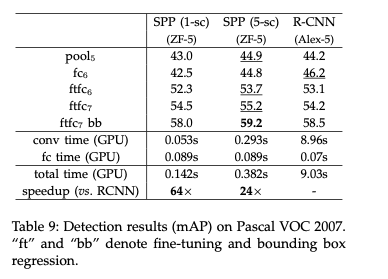
ft는 파인튜닝을 뜻하며, RCNN과 비교해 속도가 향상되었다.
4.3 Complexity and Running Time
기존 RCNN보다 향상.
4.4 Model Combination for Detection
같은 합성곱 레이어에 fine tuning한 결과들을 조합했을 때 성능 향상을 보인다.
5 CONCLUSION
SPP는 다양한 스케일, 크기 및 비율을 다루기 위한 유연한 솔루션이다.
SPP layer를 사용하여 깊은 신경망을 훈련시키는 해결책을 제안했다.
결과적으로 나타난 SPP-net은 분류/검출 작업에서 높은 정확도를 보이며 DNN 기반 검출을 크게 가속화한다.
refrence
https://deep-learning-study.tistory.com/445
https://blog.naver.com/siniphia/221526949815
https://velog.io/@twinjuy/SPPNet-%EB%85%BC%EB%AC%B8-%EB%A6%AC%EB%B7%B0Spatial-Pyramid-Pooling-Network
