EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks
ICML 2019
-
EfficientNet은 기존 합성곱 신경망 스케일링에서, 네트워크의 너비와 깊이, 그리고 인풋 이미지의 해상도 3가지 측면을 compound scaling을 통해 모두 스케일링하는 방법론을 제시한다.
기존의 합성곱 신경망 스케일링은 네트워크의 너비 (width), 깊이(depth), 이미지 해상도 (resolution) 중 한가지에 대해서만 스케일링 하는 것에 대한 문제점을 제기한다. -
사전에 MobileNet과 SENet을 공부하고 오면 좋을 듯하다.
Abstract
일반적으로 합성곱 신경망은 한정된 컴퓨팅 자원을 사용한다.
이때, 더 많은 리소스가 사용 가능하면 모델의 정확도를 높이기 위해 확장을 시도한다.
본 논문에서는 신경망의 깊이, 너비, 인풋 이미지의 해상도를 균형있게 스케일링하는 Model scaling, identify를 체계적으로 연구한다.
간단하지만 효과적인 compound coefficient를 사용해 깊이,너비,해상도 각각에 대해 균일하게 스케일링하는 방법을 사용했다.
신경망 구조 탐색 (Neural Architecure Search)을 해서,
EfficientNets라는 새롭게 디자인 된 신경망 모델들의 집합을 얻었다.
위 모델 집합은 기존 신경망보다 정확도와 효율성이 좋았고, 집합 속의 몇몇 모델들은 기존 모델보다 정확도가 높으면서 작고(파라미터 수가 적고), 따라서 연산량이 줄었다는 장점을 가진다.
여기서 신경망 탐색(Neural Architecture Search)이란,
Hidden layer num, filter size, filter num per layer, padding, stride size… 등을 수동으로 설정하는 것이 아닌
최적의 네트워크 구조를 편리하고 빠르게 탐색하는 방법론을 연구하는 분야를 의미함.
1. Introduction
신경망을 확장하는 것은 더 좋은 정확도(성능)를 얻기 위한 일반적인 방법이다.
ResNet18에서 200으로 확장한 것이 그 예시라고 할 수 있겠다.
하지만 신경망 확장의 프로세스는 확실하게 이해되어 있지 않고(절대적으로 좋은 방법이 존재하지 않았음), 많은 방법들이 존재한다.
신경망을 확장하고자할 때, 확장의 대상이 되는 것은 일반적으로 네트워크의 깊이, 너비, 그리고 인풋 이미지의 해상도이다. 기존 연구들은 주로 이 세가지 중 하나만 다뤘다고 한다.
두 세가지를 한번에 임의로 확장하는 것이 가능은 하지만, 수동적인 튜닝이 필요하고 (논문에서는 지루하다고 표현함), 아직 정확도와 효율성을 얻기 힘들다고 한다.
저자들이 연구를 해보니, 스케일링 시에 신경망의 깊이, 너비, 해상도의 각각을 균형있게 하는 것이 중요하며 이때 비율이 간단히 얻어질 수 있다고 한다.
위에서 말한 세가지 요소들을 균형있게 스케일링할 수 있는 compound scaling method라는 간단하지만 효과적인 방법을 제안했다.
위 스케일링의 요소들을 임의적으로 확장하는 대신 논문의 방법은 고정된 스케일링 계수(scaling coefficient)를 이용해 균일하게 스케일링한다.
예를 들어 만큼 컴퓨팅 리소스를 증가시키고 싶으면 (depth), (width), (image size) 만큼 각각 증가시키면 된다.
이떄 은 기존의 작은 모델에서 small grid search로 얻은 값이다.
즉 Auto ML의 방식으로 알파,베타,감마 값을 찾는다는 것.
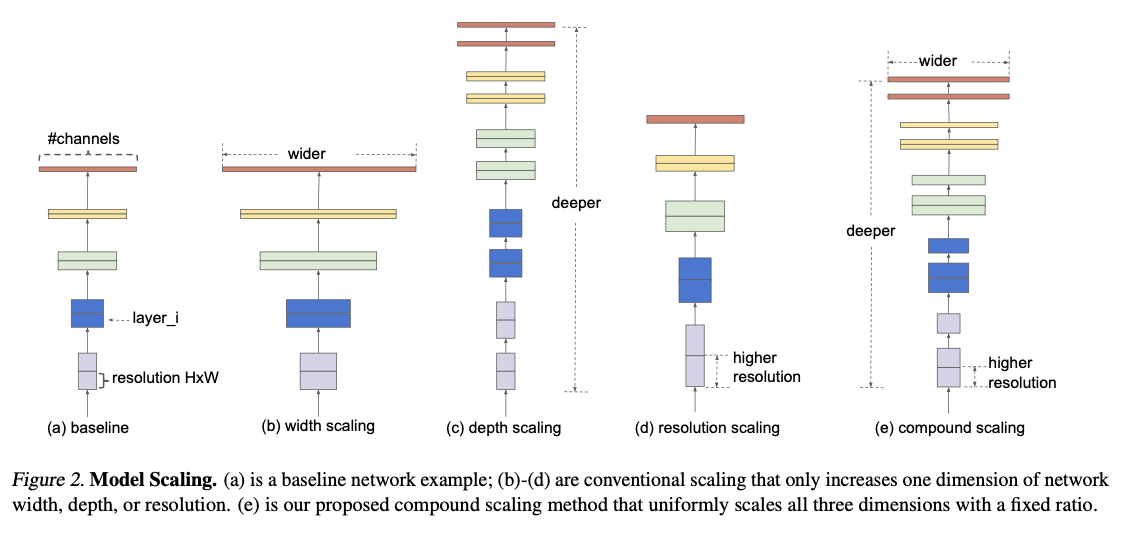
Figure2를 보면, compound scaling은 깊이, 너비, 해상도를 모두 스케일링 한 것을 볼 수 있다.
(b),(c),(d)는 기존의 한 가지만 스케일링을 했던 것에 대한 예시이다.
이미 기존 연구들에서 깊이,너비,해상도가 각각 관계를 가지고 있음을 보여줬지만, 본 논문이 최초로 관계를 양적으로 측정한 사례이다.
직관적으로 예를 들어 이미지 해상도를 높이면, 세부적인 디테일을 캡쳐하기 위해 모델이 깊어져야 할 것이다.
하지만 해상도와 깊이의 관계에 대해선, 본 논문이 양적으로 측정한 첫번째 사례라는 것.
모델 스케일링 (Model Scaling; Compound Scaling 을 뜻한다)은 기존 베이스 모델의 성능에 크게 의존한다. 이유는 뒤에서 자세하게 설명된다.
따라서 신경망 탐색을 통해 좋은 베이스 모델을 서칭하고, 이 모델들을 스케일링해 EfficientNets라는 모델 집합을 만들었다.
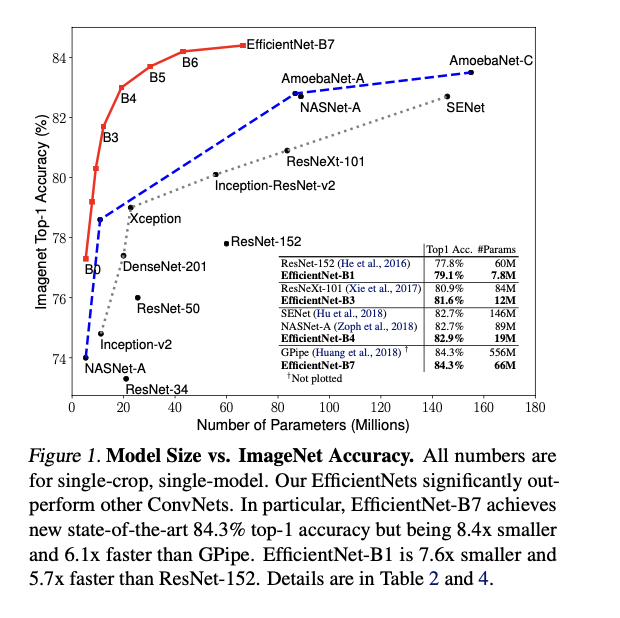
Efficient Nets의 모델들은 기존보다 가볍고, 빠르며 정확도가 좋다.
파라미터 수가 적으니, FLOPS가 낮다.
최대 21배 적은 파라미터의 수로, 전이학습에 널리 사용되는 8개의 데이터셋 중 5개에서 소타를 달성한다.
Figure1 을 보면, 기존 모델들의 확장에 따른 정확도 향상을 보여주지만, EfficientNets의 모델들은 더 적은 파라미터로도 더 높은 정확도를 달성하는 것을 보여줌.
FLOPS는 FLoating point Operations Per Second의 약자로,
1초당 얼마나 많은 연산을 처리할 수 있느냐하는 하드웨어의 퍼포먼스 측면을 보는 단위.
머신러닝에서 컴퓨팅 연산량을 측정하는 단위라고 생각하면 되겠다.
2. Related Work
-
ConvNet Accuracy:
AlexNet, GoogleNet, SENet 등 기존 모델들은 커져가며 더 정확도를 증가시켰다.
하드웨어 메모리에 대한 제한이 있기 때문에, 정확도가 물론 중요하지만 효율성의 중요성이 대두된다. -
ConvNet Efficiency
효율성 증진을 위한 방법으로 모델 압축(Model compression)이 일반적이다.
모바일 기기 보편화로 이를 위한 효율적인 모델들이 등장했다.
모바일 사이즈 신경망을 설계하기 위해 Neural architecture search가 점점 화두되었다.
규모가 작은 모델에서 주로 사용되게 때문에, 규모가 큰 모델에 적용할 때에는 더 큰 디자인 공간과 더 비싼 튜닝 비용이 요구됨. -
Model Scaling:
다양한 리소스 제약에 대해 많은 스케일 방법론이 있다 :
ResNet18, ResNet200 은 깊이를 조절하여 축소 또는 확장.
WideResNet 및 MobileNets는 너비를 조절하여 스케일링.
더 큰 인풋 이미지 사이즈는 FLOPS가 증가하지만 정확도를 향상시킬 수 있다.
네트워크 깊이와 폭이 중요하지만, 어떻게 효과적으로 더 나은 효율성과 정확도를 달성할지는 아직 해결되지 못한 과제.
3. Compound Model Scaling
3.1. Problem Formulation

합성곱 레이어 는 위 함수로 정의된다.
이때 : 연산자, 는 출력 텐서, 는 입력 텐서이고 의 텐서 형태는 <>이다.
이때 는 공간 차원, 는 채널 차원.
이때 합성곱 신경망 은
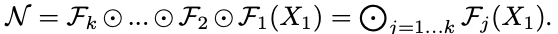
다음과 같이 나타낼 수 있다.
합성곱 레이어는 여러 단계가 있지만 각 단계의 모든 레이어는 동일한 구조를 공유한다.
따라서 합성곱 레이어를 밑과 같이 정리할 수 있다.
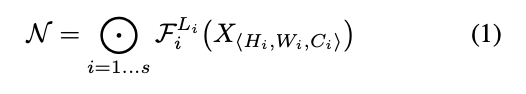
는 layer가 단계에서 번 반복됨을 의미한다.
<> shape의 를 에 넣는데, 는 한번의 (layer) 안에서 network length()만큼 계산 반복. layer()는 만큼 있으니 는 번 반복하는 계산을 번 수행한다.
일반적인 합성곱 신경망 설계는 주로 의 구조를 찾는데 중점을 둔 반면, model scaling은 를 기존 네트워크에서 미리 정의된 상태를 유지하면서 (네트워크 길이: 깊이), 너비(), 또는 해상도 ()를 스케일링 시도한다.
를 변경하지 않기 때문에 앞서 말한 좋은 베이스모델 서칭이 중요하다.
고정으로 단순화 시켰지만, 를 탐색하는 큰 디자인 스페이스가 남아있다.
이러한 디자인 스페이스를 줄이기 위해 모든 레이어가 균일한 비율로 스케일링 된다는 제약을 걸었다.
따라서 정확도와 리소스 제약을 다루기 때문에 최적화 문제로 귀결될 수 있음.

(depth, width, resolution)을 동시에 조절해 정확도와 효율성을 갖는 모델을 이루는 의 관계를 가지는 것을 목표로 한다는 뜻으로 보인다.
3.2. Scaling Dimensions
은 서로 연관되어 있고, 자원의 제약에 따라서 값들이 변경된다는 어려움이 존재한다.
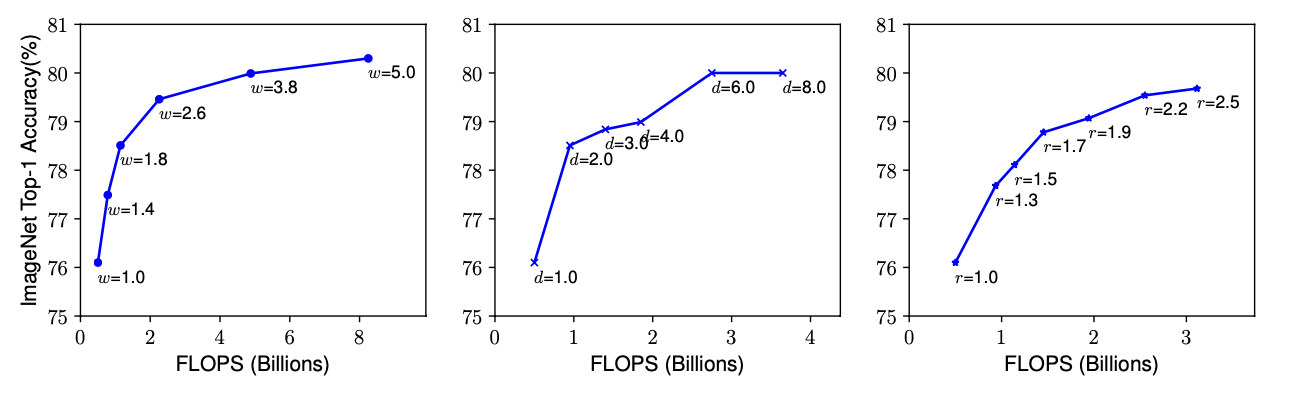
위 그래프의 x축은 참고로 FLOPS, 즉 연산량을 의미한다.
-
Depth(d):
더 깊은 ConvNet은 더 풍부하고 복잡한 특징을 잡아내어 새로운 작업에 일반화가 가능.
하지만 vanishing gradient problem을 해결해야 한다.
skip connection, batch normalization이 완화 가능하지만 매우 깊은 네트워크에서 힘을 쓰지 못한다. 위 가운데 그래프에서 깊이가 6과 8의 성능 차이가 미비함을 볼 수 있음. -
Width (w):
너비 조절은 작은 사이즈의 모델에서 일반적으로 사용된다.
넓은 네트워크는 세밀한 특징을 캡쳐할 수 있고 훈련이 더 쉬워진다.
하지만 극단적으로 넓지만 얕은 네트워크는 높은 수준의 특징을 캡쳐하는데 어려움이 존재한다.
위 왼쪽 그래프에서 3.8과 5의 성능 차이가 작다. -
Resolution (r):
더 높은 해상도의 인풋을 사용하면 ConvNets가 더 세밀한 패턴을 캡쳐할 수 있다.
초기에는 224 x 224로 시작하여 지금은 더 커졌으며, Object Detection에서는 600 x 600도 사용된다.
위 오른쪽 그래프에서도 어느정도 수준이 넘어가면 성능이 어느 수준에 수렴함.
Observation 1
즉 어느 차원이든지 스케일링하면 성능이 올라가지만, 더 큰 모델에서는 성능 향상 폭이 감소한다.
3.3. Compound Scaling
해상도와 네트워크의 너비와 깊이 이 세가지는 독립적이지 않다.
따라서 기존까지 이루어졌던 단일 차원의 스케일링이 아닌 다양한 스케일링 차원을 조율하고 균형맞춰야 한다.
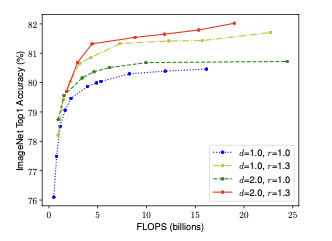
으로 고정했을 때 너비 스케일링만 진행했을 때보다, 동일한 FLOPS에서 너비 뿐만 아니라 깊이와 해상도도 스케일링했을 때 성능이 더 좋았음. 위 그래프에서 파란색이 전자에 해당한다.
Observation 2 –
정확도와 효율성을 위해, 네트워크 너비, 깊이, 해상도를 모두 균형있게 스케일링 하는 것이 중요하다.
본 논문에서는 기존의 수동적인 스케일링이 아닌, 모든 차원을 균일하게 스케일링하는 새로운 compound scaling을 제안한다.
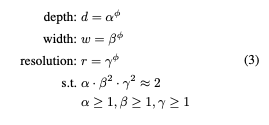
여기서 는 small grid search로 결정될 수 있는 상수.
직관적으로 는, 모델 스케일링에 사용가능한 추가적인 자원을 컨트롤하는 user specified 계수이다. (사용자 지정 하이퍼 파라미터)
이때 는 추가자원을 네트워크 너비, 깊이, 해상도에 얼마나 할당할지 정한다. (최적의 값을 찾아야 하는 변수들)
- 이때 깊이 2배 증가시킬 때 FLOPS 2배 증가.
너비를 2배 증가시킬 때 FLOPS 4배 증가. (너비는 출력레이어, 다음 입력레이어에 걸쳐 총 2번 연산이 됨.)
해상도 2배 증가시킬 때 또한 FLOPS 4배 증가 (이미지의 가로 x 세로를 의미하기 때문)
따라서 Total FLOPS by 이고,
본 논문에서는 의 값을 2로 제한했기 때문에, 총 FLOPS는 만큼 커진다.
4. EfficientNet Architecture
Model scaling은 레이어 연산자인 를 변경하지 않기 때문에 베이스라인 네트워크가 중요하다.
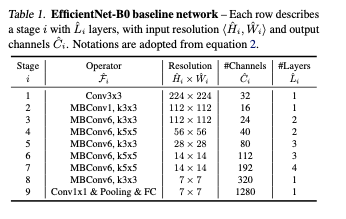
기존 ConvNet을 스케일링하여 평가할 것이지만, 저자들은 그들의 스케일링 방법론이 효과적임을 보이기 위해 EfficientNet이라는 모바일 사이즈의 베이스라인 또한 개발했다.
를 최적화하는 아키텍쳐를 만들었다. (MnasNet, Tan et al., 2019; Cai et al., 2019를 참조했다고 한다.)
and 는 모델 의 정확도와 FLOPS를 의미하고, 는 목표 FLOPS, 으로 설정했는데, 는 정확도와 FLOPS 사이의 편향을 조절하기 위한 하이퍼 파라미터.
기존 MnasNet과 달리 특정 하드웨어 장치를 대상으로 하는 것이 아니기에, latency(지연시간)가 아닌 FLOPS를 사용했다고 한다.
EfficientNet-B0는 기존과 동일한 탐색 공간을 사용하므로 MnasNet과 비슷하지만, 큰 FLOPS 타겟값때문에 살짝 더 크다고 한다.
EfficientNet은 메인 building block으로 mobile inverted bottleneck MBConv을 사용했고, squeeze-and-excitation 최적화를 추가했다.
MBConv (참고)
MBConv와 squeeze-and-excitation은 논문에는 자세히 다루지는 않는 내용이다.
참고용으로 보면 되겠다.
MBConv는 Deepwise separable conv, squeeze-and-extcitation의 개념이 필요하다.
Deepwise Separable Convolution란 Depthwise Conv + Pointwise Conv라고 생각하면 되겠다.
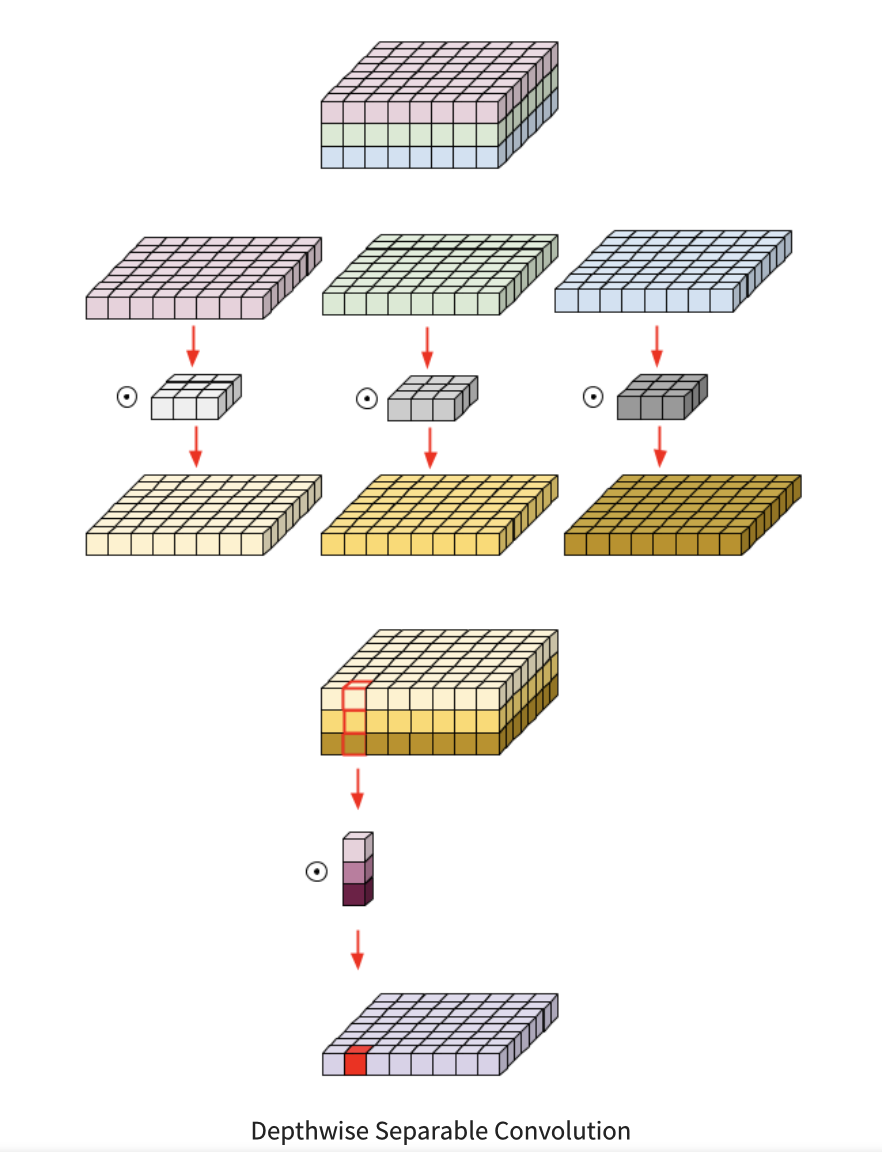
-
Depthwise conv는 이미지 혹은 피쳐맵을 채널별로 쪼개서 합성곱 연산을 적용, 위 그림에서 상단. (인풋 피쳐를 그냥 합성곱보다 적은 양의 파라미터로 캡쳐할 수 있음)
-
Pointwise conv는 필터 크기가 1로 고정된 1차원 컨볼루션으로 여러개의 채널을 하나의 채널로 합치는 역할, 위 그림에서 하단. (채널의 수를 조절해 차원을 감소시켜 연산량이 감소됨)
하지만 pointwise conv의 연산량이 많은 이슈로 linear bottleneck이 도입되었다.
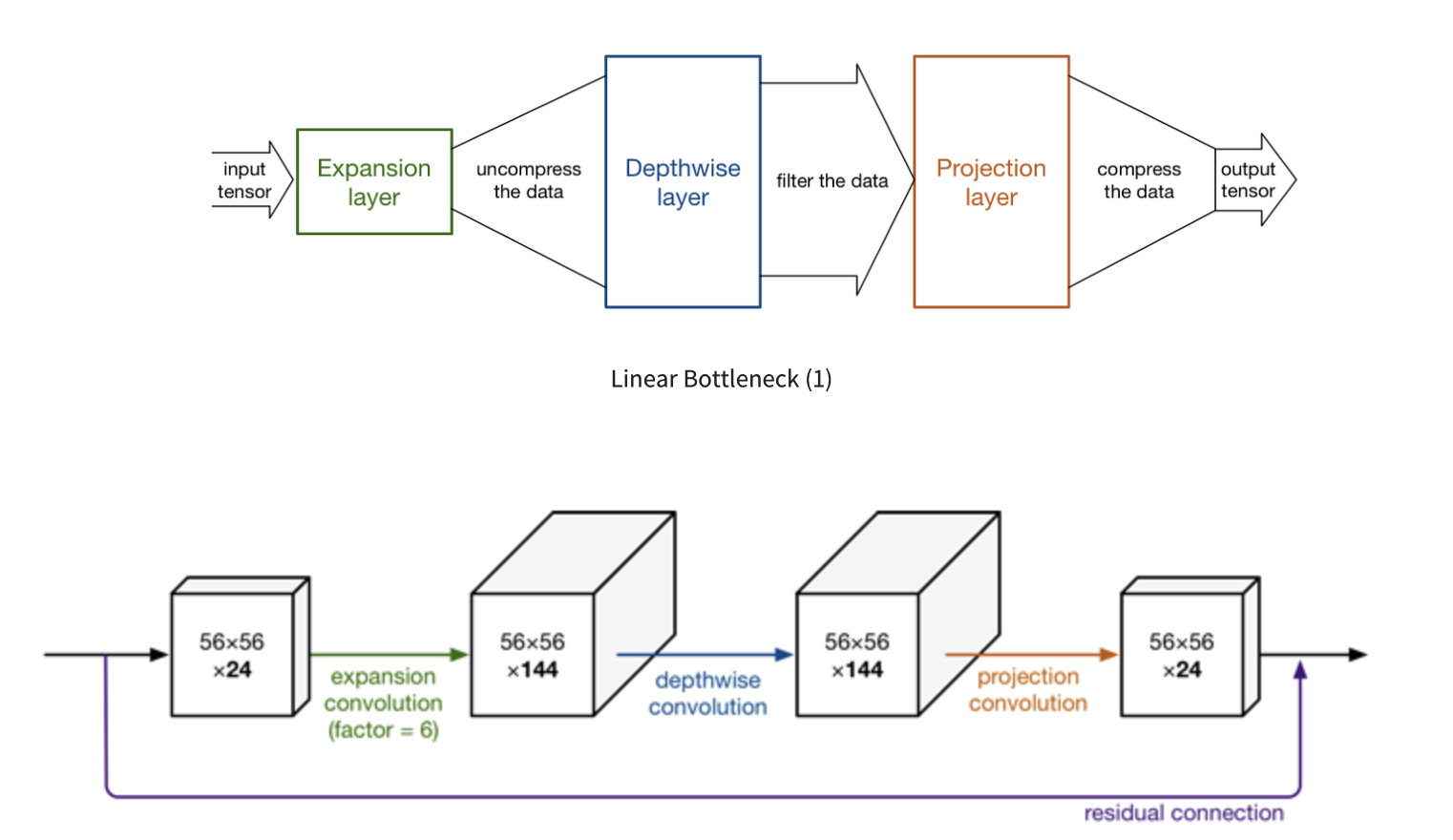
- Linear bottle neck : Manifold 가정 (고차원 정보는 사실 저차원 수준으로 잘 표현할 수 있을 것)의 가설에 기반해, 1x1 pointwise conv를 먼저 수행해 채널 수를 늘리고 depthwise conv를 진행한다. 그후 projection layer를 통해 인풋 채널 수 만큼 채널을 줄이는 구조. (메모리 접근이 감소한다고 한다.)
위 두개를 합친 것이 inverted residual이며 구조는 아래와 같다.
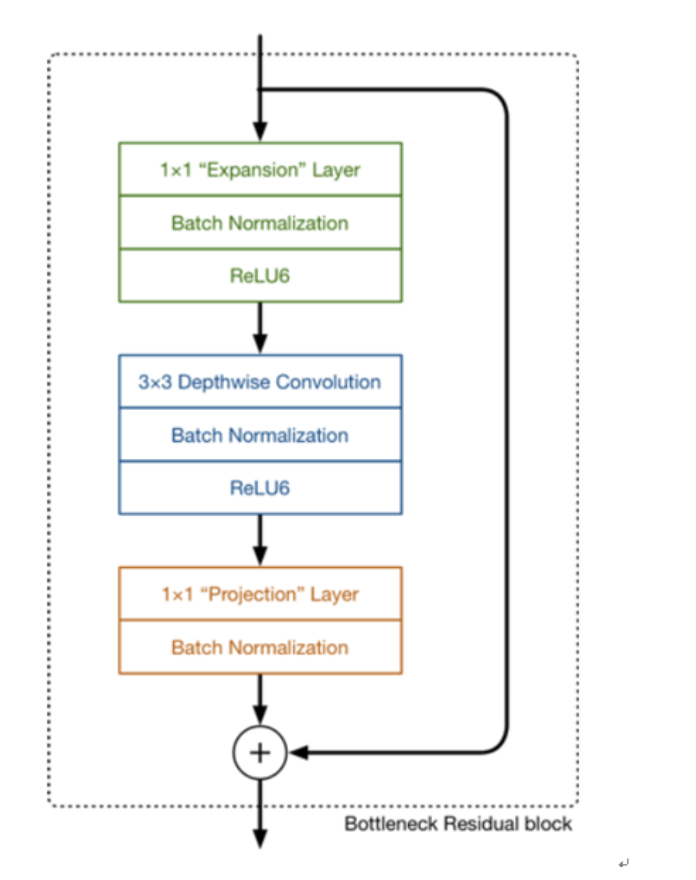
Squeeze and excitation (참고):
피쳐에 global average pooling을 사용해 피쳐맵을 1x1xC로 압축, 이후 다시 fc layer로 증폭.
채널별 중요도를 파악할 수 있다고 한다.
직관적으로 피쳐를 쥐어 짜서 정보를 얻고, 다시 증폭시켜 되돌려 놓는다고 생각하면 되겠다.
MBConv와 squeeze-and-excitation은 MobileNet과 SENet에 등장하는 개념이다.
나도 EfficientNet에 앞서 선행 공부를 하진 않은 상태이므로 추후 더 공부해보겠다.
다시 본 논문으로 돌아와서, 큰 모델에서 값을 직접 정하면 더 좋은 성능을 내겠지만, 비용이 많이 든다.
따라서 small baseline (B0)를 정하고 (step1), 다른 모델에 대해 같은 스케일링 계수를 사용한다. (step2)
STEP 1: 를 1로 고정, 두배의 자원이 더 사용가능하다고 가정하고 알파, 베타, 감마에 대한 small grid search 수행.
라는 규제 하에 라는 값을 얻었다.
STEP 2: 를 고정하고 파이를 바꿔가며 B1-B7을 얻었다.
5. Experiments
5.1. Scaling Up MobileNets and ResNets (기존의 ConvNet)
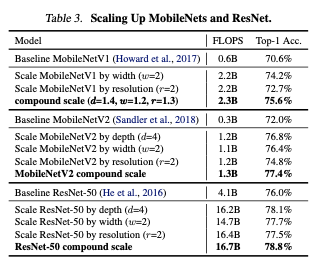
MobileNet, ResNet 베이스모델과 본 논문의 스케일방법을 사용했을 때의 성능 차이를 나타내는 표.
정확도 향상이 나타난다.
5.2. ImageNet Results for EfficientNet
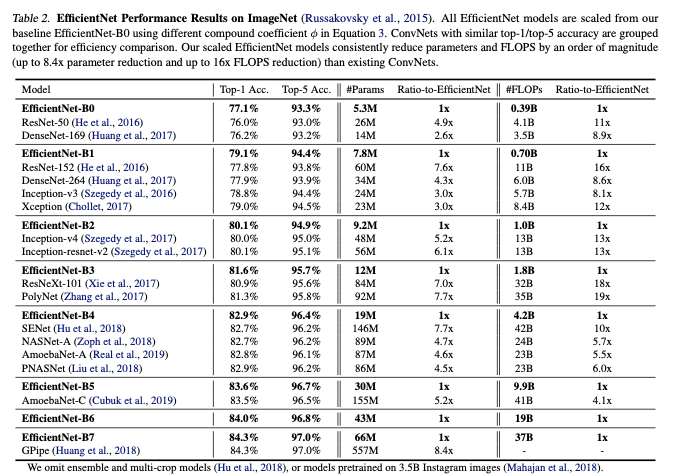
EfficientNet은 더 적은 파라미터 수와 FLOPS를 더 적게 수행했지만 정확도가 향상됨.
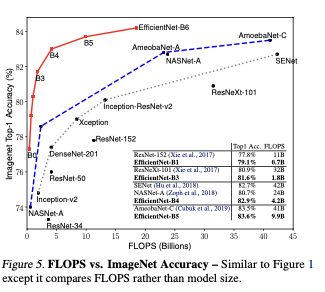
축은 FLOPS임을 참고하자.
EfficientNet이 파라미터 수가 적으니 FLOPS가 적게 나타나지만, 성능은 높다.

비슷한 성능인 모델에 대해, 지연 시간이 많이 감소된 것을 볼 수 있다.
5.3. Transfer Learning Results for EfficientNet
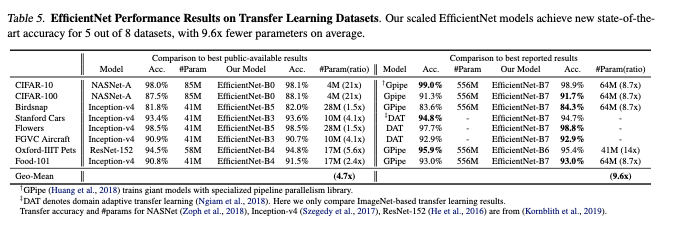
전이학습에 사용한 옵티마이저와 하이퍼파라미터 등에 대한 설명은 밑과 같으니 참고.
RMSProp optimizer with decay 0.9 and momentum 0.9; batch norm momentum 0.99; weight decay 1e-5; initial learning rate 0.256 that decays by 0.97 every 2.4 epochs. We also use SiLU (Swish-1) ac- tivation (Ramachandran et al., 2018; Elfwing et al., 2018; Hendrycks & Gimpel, 2016), AutoAugment (Cubuk et al., 2019), and stochastic depth (Huang et al., 2016) with sur- vival probability 0.8. As commonly known that bigger mod- els need more regularization, we linearly increase dropout (Srivastava et al., 2014) ratio from 0.2 for EfficientNet-B0 to 0.5 for B7.
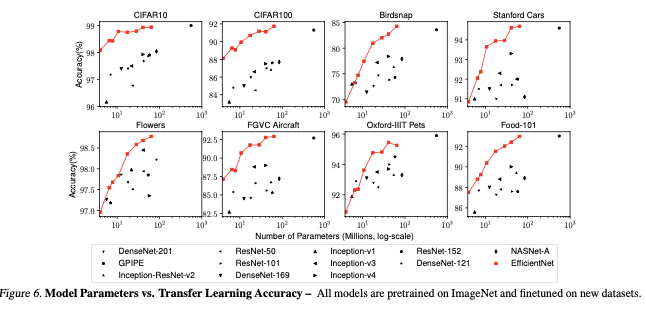
전이학습 데이터를 가지고 학습한 내용에 대한 결과는 위와 같다.
왼쪽은 평균 파라미터 수는 4.7배 감소했지만 정확도가 향상.
오른쪽은 평균 파라미터 수가 9.6배 감소했지만 비슷하거나, 더 높은 성능.
6. Discussion
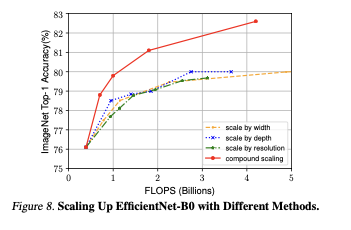
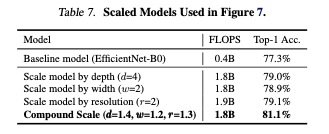
일반적으로 스케일링 방법은 더 많은 FLOPS를 지불하면 성능이 향상되지만, 단일 스케일링보다 compund scaling이 모든 차원을 균일하게 스케일링했고, 성능 또한 향상 시키는 결과를 가져왔다.
추가적으로, Compound scaling이 더 많은 객체 세부사항에 대해 더 많은 관련 영역에 집중하는 경향이 있었다고 한다.
7. Conclusion
너비, 깊이, 해상도에 대해 균형있게 스케일링을 하는 것이 중요하다.
타겟 자원 제약에 대해 다룰 수 있기에 효율성을 유지하면서 정확도를 더 높게 달성할 수 있었다.
refrence :
