논문 요약 2탄이다.
이번엔 Transformer에 대한 내용인데, 사실 이 논문의 경우 블로그에 글을 쓰는 시점을 기준으로 1달 전에 읽었던 논문이다.
요즘 딥러닝 분야에서 핫한 모델을 꼽으라면 개개인의 관심분야나 중요도의 척도 등에 따라 다르겠지만 Transformer를 말하는 사람들이 많을 것이다. 그 만큼 Transformer는 현재 여러 딥러닝 분야, 특히 NLP에서 월등한 성능을 보이고 있고 최근에는 Computer Vision 분야에도 접목되어 높은 성능을 보이고 있다.
학부 인공지능 수업에서도 Transformer에 대한 내용을 따로 배웠는데 그 때도 Seq2Seq모델 부터 시작해서 Transformer를 거쳐 기본적인 NLP에 대한 이론을 배우기 까지 거의 1달 가량을 Transformer와 관련된 내용을 배운 것 같다.
나날히 중요성이 증가하고 있기 때문에 Transformer라는 모델이 처음으로 등장한 "Attention Is All You Need" 논문을 읽게 되었다.
(일단 이름부터가 간지다 - Attention은 너가 필요한 모든것이다)
Transformer의 등장이 BERT와 GPT-3 같은 모델이 등장하게 되는 계기가 되고 NLP 분야의 발전의 기반이 되었다. 따라서 이 논문을 읽고 과연 Attention이란 무엇이고 왜 이 모델에서는 Attention의 중요성을 이렇게나 강조하였는지 알아보고자 한다.
그 전에 사람들에게 단순히 attention의 단어 뜻을 물어본다면 focus라는 단어와 연관지어 "집중"이라고 말할 것이다. 이 논문을 읽고 나면 느끼겠지만 attention도 많이 쓰이지만 attention의 동사형인 attend라는 단어가 정말 많이 쓰인다는 것을 알 수 있다. 무언가에 집중을 한다는 것은 여러 대상들 사이에서 특정한 무언가에 가중치를 더 줘서 우선순위를 높인다는 의미로 해석할 수 있다. 이 논문은 후자의 의미로 해석을 하면 훨씬 이해하기가 수월할 것이다.
참고
Introduction
RNN과 LSTM이 특히나 sequence modeling과 language modeling 같은 sequence modeling 분야에서 SOTA로서 입지를 확고히 다지고 있었는데 Transformer라는 재귀를 삼가하고 input과 output간의 global한 dependency를 이끌어내기 위해 attention mechanism을 사용한 모델 구조를 제시하여 성능을 향상시킨 기법을 소개하고자 한다.
In this work we propose the Transformer, a model architecture eschewing recurrence and instead relying entirely on attention mechanism to draw global dependencies between input and output.
Seq2Seq 모델의 한계점
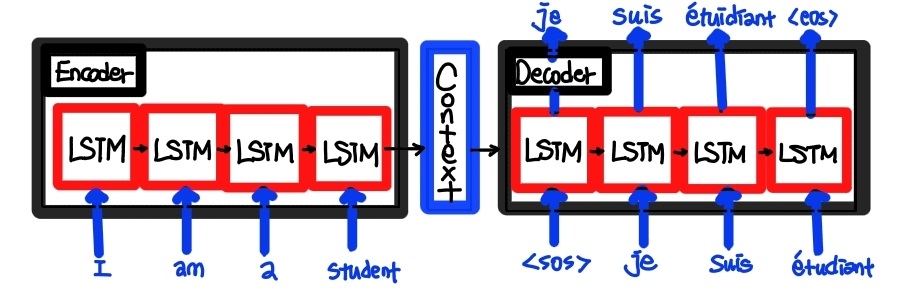
기존의 Seq2Seq 모델의 경우 단순히 encoder와 decoder가 결합한 형태의 모델 구조를 갖고 있다. 이 구조의 경우 encoder에서 입력 시퀀스를 하나의 벡터로 압축하여 만든 뒤 decoder에게 전달해서 decoder가 이를 해석하여 출력 시퀀스를 생성하는 과정으로 이뤄진다.
위의 그림을 예시로 들면 I am a student라는 문장이 하나의 벡터로 압축이 되어 context를 통해 decoder로 전달이 되는데 그 뒤 decoder가 이 벡터를 해석하여 Je suis étudiant라는 출력 시퀀스가 생성이 되는 것이다.
그러나 seq2seq 모델의 경우 단점이 존재하는데, 위의 과정에서 통로가 하나이기 때문에 여러 입력 시퀀스가 입력될 경우 병목현상 (Bottleneck problem)이 발생할 수도 있고 단어 Sequence를 하나의 벡터로 압축하는 과정에서 정보 손실이 발생할 가능성이 존재할 뿐더러 참조하는 윈도우의 고정된 크기로 인하여 sequence에서 멀리 떨어진 항목들 사이의 관계는 Exploding/Vanishing gradient 문제가 발생하여 학습이 잘 이루어지지 않는다는 문제점이 존재한다. 이러한 문제점들의 개선 방안을 찾아가는 과정에서 Attention mechanism이라는 개념이 등장하게 되어 Transformer 모델에 적용되게 되었다.
Background
Self-Attention
Self-Attention. sometimes called intra-attention is an attention mechanism relating different positions of a single sequence in order to compute a representation of the sequence.
말이 길지만 해석하자면 말 그대로 스스로에게 attention을 한다는 것이다. 이를 Attention mechanism의 관점에서 해석을 하면 특정 문장이 있을 때 자기 자신에게 attention을 부여하여 sequence내에서의 자기 자신과 다른 text간의 관계를 파악하고 문장 내에서의 의미를 파악하는 것을 말한다.
이러한 Self-attention을 처음으로 사용하고 더 나아가 self-attention에만 relying entirely 라는 강조의 표현까지 사용해가며 self-attention의 중요성을 강조한 모델이 바로 Transformer이다.
Model Architecture
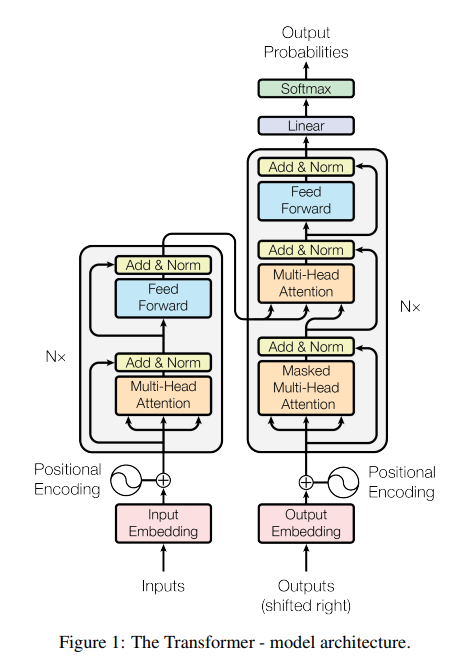
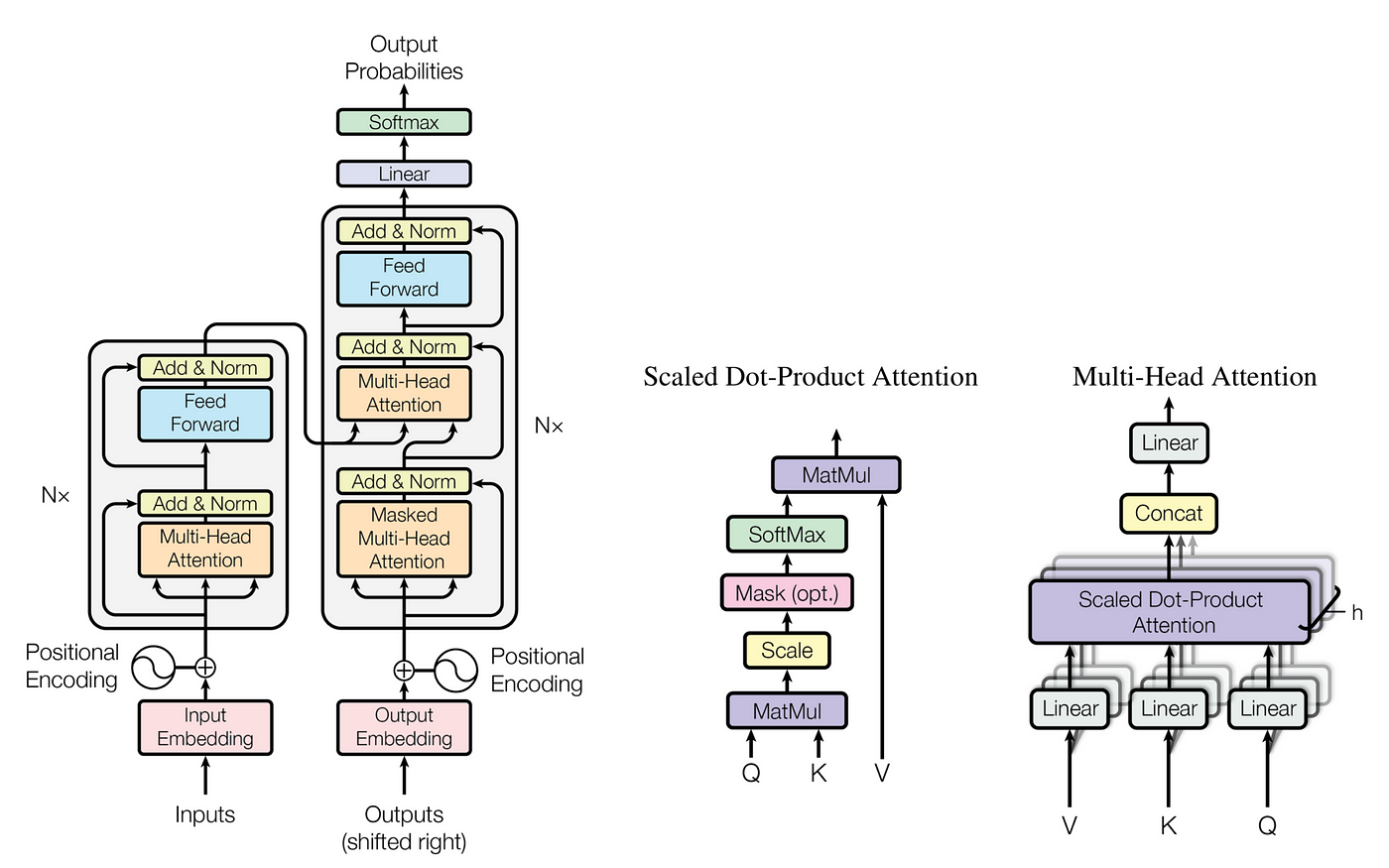
1. Encoder and Decoder Stacks
- Encoder : Encoder은
N=6인 동일한 layer들의 stack으로 이루어져 있다. 각각의 layer는 2개의 sub-layer들이 있는데 첫번째는 multi-head self-attention mechanism이고 두 번째는 simple, position wise fully connected feed-forward network이다.
각각의 layer의 output은 이고 모든 layer들은 512 차원의 output을 생산한다. - Decoder : Decoder는 Encoder와 마찬가지로
N=6의 동일한 layer들의 stack으로 이루어져 있다. 그러나 Encoder와 달리 Decoder는 세 번째 sub-layer를 추가하는데 이 layer는 multihead-attention을 encoder stack의 output에 대해 수행한다. 또한 특이한 점은 Multihead-attention에 masking을 한 점인데, 이를 통해 position 에서의 예측이 오롯이 보다 낮은 위치에만 의존하도록 할 수 있다.This masking, combined with fact that the output embeddings are offset by one position, ensures that the predictions for position can depend only on the known outputs at positions less than
이를 그림과 수식으로 나타내면 다음과 같다.
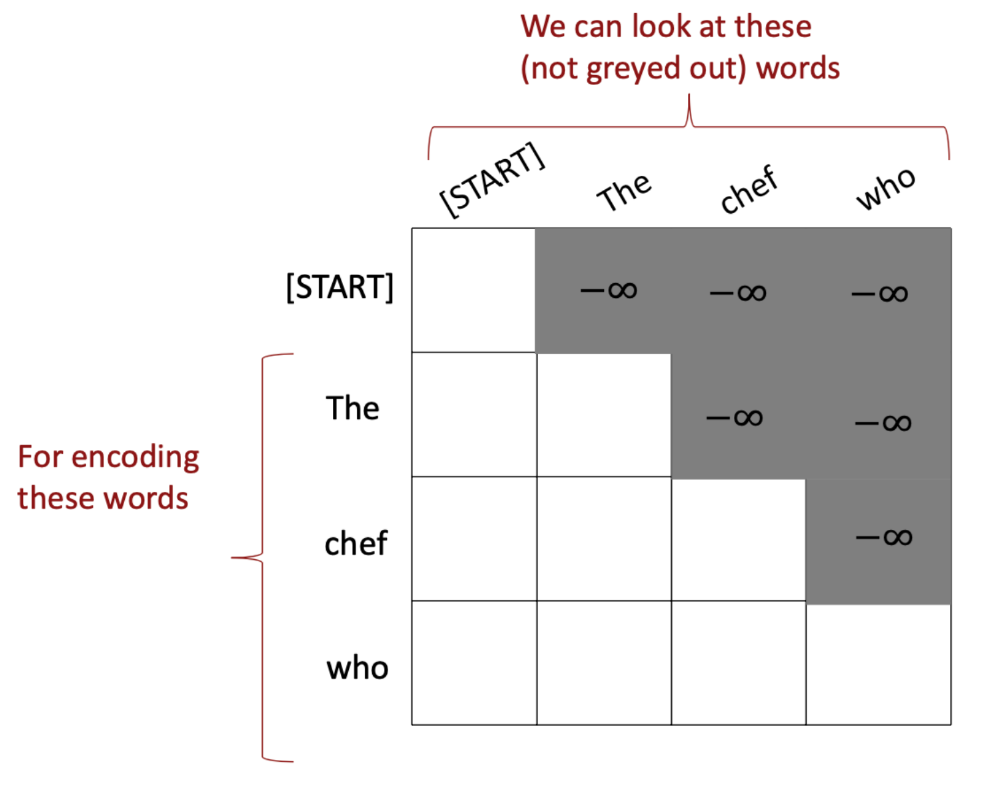
위의 행렬을 보면 하삼각행렬을 제외하고는 나머지가 전부 으로 채워져 있다는 것을 알 수 있다. 위 행렬은 대칭행렬이기 때문에 (i,j) 성분과 (j,i) 성분이 같아서 연산의 양을 이런 식으로 대칭성을 이용해 줄일 수 있다.
Encoder로 들어간 Sequence "The chef who~"를 통해 다음에 올 단어를 예측하는데 이 과정에서 다음에 오는 단어는 볼 수 없도록 마스킹 처리를 하는 것이다. 예를 들어 The의 경우는 chef와 who를 볼 수 없다.
2. Attention
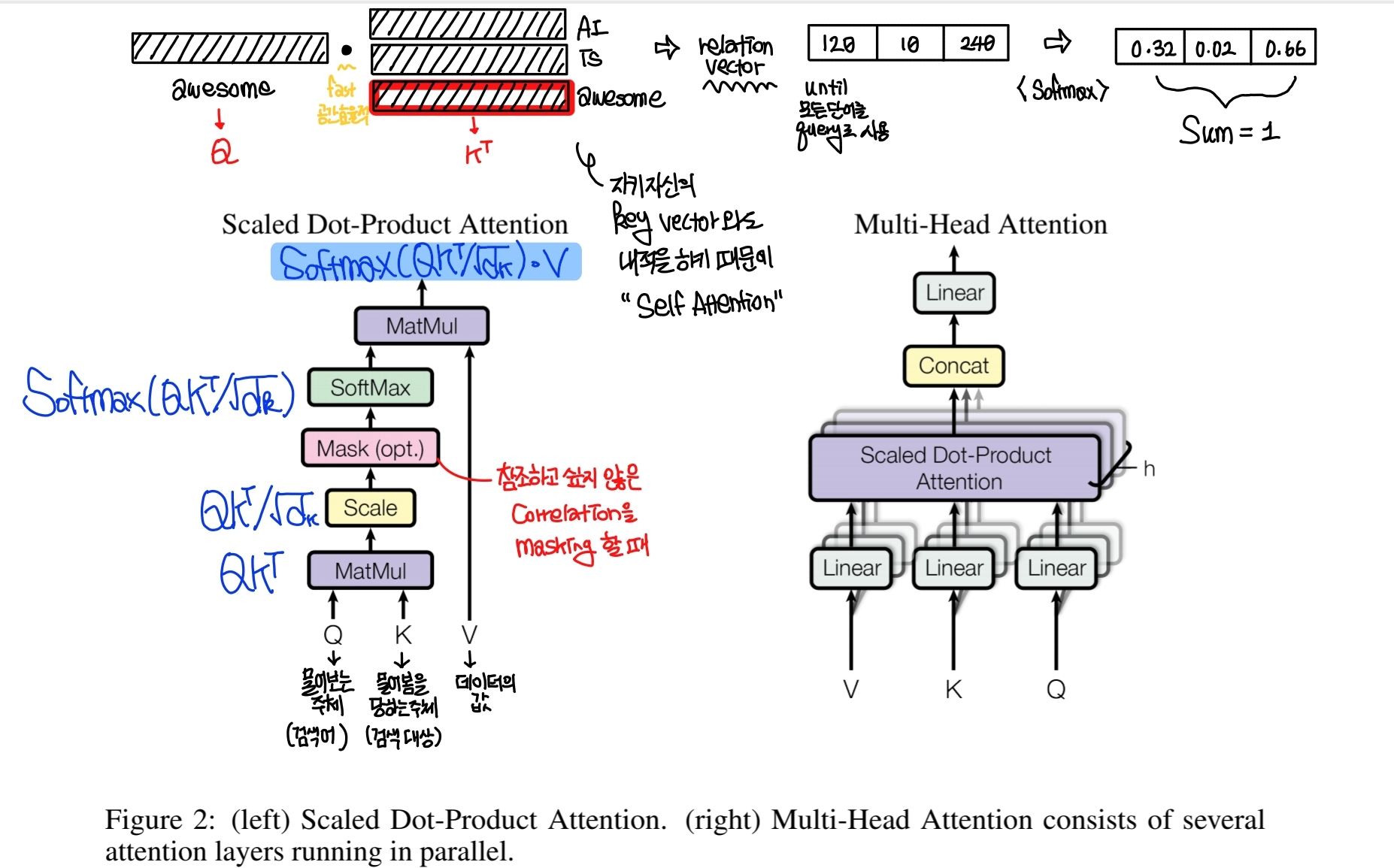
(필기는 양해 부탁드립니다. 그래도 이정도면 알아볼 수 있을 정도 아닌가요?ㅎㅎ)
위의 구조를 보면 Key와 Query가 Matmul (내적)을 거쳐 크기가 1로 정규화된 뒤 Masking과 Softmax를 거쳐 Value와 연산되어 결과가 출력된다. 이를 수식으로 나타내면
가 되는데 이를 병렬적으로 여러개의 layer로 쌓아서 concatenate 한 것이 Multi-Head Attention이다.
여기서 먼저 Key, Query, Value에 대해 각각의 의미를 살펴보면,
쉽게 말해 Query는 검색어, Key는 검색에 대한 결과, Value는 결과에 들어있는 내용이라고 생각하면 된다.
구글을 예시로 들자면, 구글에서 Transformer에 대해 검색하고 싶을 때 Transformer를 검색창에 입력을 하고 그에 대한 결과로 Transformer가 무엇인지 관련된 블로그나 뉴스기사 등등이 나온다. 여기에서 검색어 Transformer가 Query의 역할이고 Transformer에 대한 결과로 나오는 결과가 Key, 그 안의 내용 (데이터의 값)이 value이다.
2-1. Scaled Dot-Product Attention
이 식이 Scaled Dot-Product Attention 식이다. 여기서 dot product 연산을 수행한 이유는 훨씬 빠르고 공간절약적이며 매우 최적화된 행렬 연산이기 때문이다.
dot-product attention is much faster and more space-efficient in practice, since it can be implemented using highly optimized matrix multiplication code.
또한 이 식에서 차원으로 scale을 해주는 것은 dot product를 하게 되면 softmax 함수에게 매우 큰 수를 전달하게 될 가능성이 있는데 이게 매우 작은 gradient를 가질 수 있기 때문이다.
We suspect that for large values of , the dot products grow large in magnitude, pushing the softmax function into regions where it has extremely small gradients. To counteract this effect, we scale the dot products by .
2-2. Multi-Head Attention
하나의 single attention 함수를 실행하는 것 보다 선형적으로 query, key, value를 project하는 것이 더 효율적이라는 것을 발견하여 여러 layer의 scaled dot-product attention을 합쳐서 구성을 하였다.
2-3. Applications of Attention in our Model
Transformer 모델에서는 multi-head attention을 세 가지의 방법으로 사용하였다.
- "encoder-decoder attention" layer에서 query는 이전의 decoder layer에서 전달되고, key와 value들은 encoder의 output으로 전달된다. 이게 decoder에서 모든 input sequence를 attend할 수 있도록 해주는데 이 점은 seq2seq model에서의 encoder-decoder 모델을 모방한 것이다.
- Encoder는 self-attention layer를 갖고 있다. Self-attention layer의 모든 key, query, value는 같은 위치에서 온다. 이 경우에서는 같은 위치가 이전 layer의 encoder의 output이다.
- 비슷하게 Decoder에서의 self-attention layer는 decoder에서의 모든 position에 attend할 수 있게 해준다. 그러나, 여기서는 auto-regressive property 즉 이전에 말했던 예측을 하는 것을 피해야하기 때문에 softmax함수의 input의 모든 value들을 masking 해서 scaled dot-product를 수행한다.
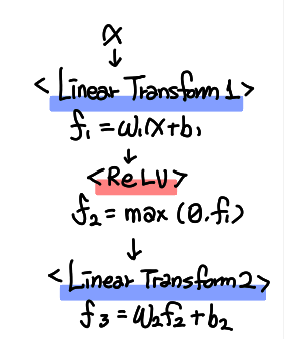
3. Position-Wise Feed-Forward Networks
Attention sub-layer들에 더하여 encoder와 decoder의 각각의 layer들은 fully-connected feed-forward network를 갖고 있다. 이 함수는 두 개의 선형 변환과 하나의 activation 함수 ReLU 함수를 포함하고 있고 식으로 나타내면 다음과 같다.
4. Embeddings and Softmax
다른 Sequence model처럼 input과 output token을 vector로 바꾸기 위해 학습된 embedding들을 사용하는데, 이 모델에서는 선형변환과 함께 softmax를 사용하여 decoder output이 다음 token의 확률을 예측한다. 두 개의 embedding layer에 같은 가중치 행렬과 pre-softmax 선형변환을 적용한다.
5. Positional Encoding
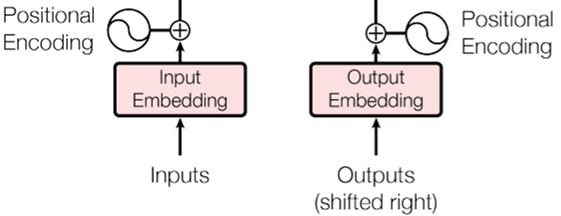
Transformer의 경우 recurrence와 convolution이 없기 때문에 sequence의 순서를 모델이 사용하도록 하기 위해 sequence에서의 token 간의 관계나 절대적인 위치 등에 대한 정보를 주입해야 한다. 그러기 위해 등장한 것이 positional encoding이다.
positional encoding은 embedding과 같은 차원을 갖기 때문에 연산이 가능하다.
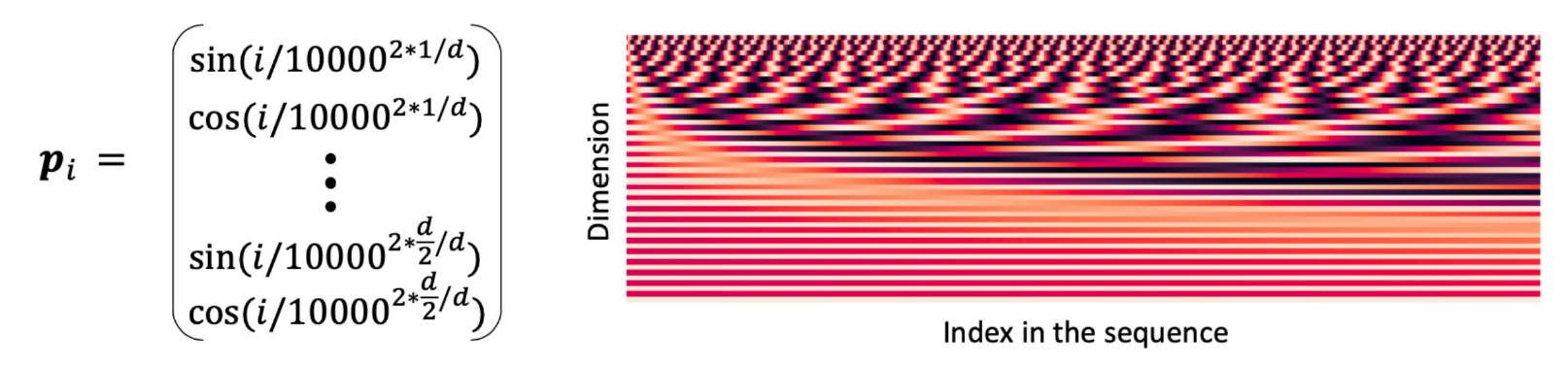
이 둘을 일컬어 Sinusoid (삼각비)라고 하는데 과 함수가 주기성을 갖기 때문에 절대적인 position이 의미가 없게 되고 한 주기가 다시 시작할 때 더 긴 Sequence를 유추할 수 있을 것이다. 하지만, 학습이 안되기 때문에 그러한 유추가 의미가 없을 수도 있다.
Why Self-Attention
같은 길이의 서로 다른 sequence를 mapping하기 위해 다양한 측면의 self-attention을 recurrent와 convolutional-layer과 비교했는데 self-attention의 사용을 정당화?하기 위해 3가지 필요한 점이 있다.
- 각각의 layer 계산 복잡도의 총합
- 최소한의 순차적인 연산으로 측정될 수 있는 병렬 가능한 연산의 총합
- 네트워크에서 긴 범위의 의존성 사이의 path의 길이
단순 번역으로 적긴 했는데 1번을 제외하고는 확 와닿지가 않는 느낌이다.
이를 조금 해석을 해보면 이 세가지가 Self-attention을 사용해야 하는 이유라고 볼 수 있다.
- layer의 계산복잡도가 감소한다.
- Recurrence가 없기 때문에 더 많은 양을 병렬처리할 수 있다.
- Long-term dependency에 대해 효율적인 처리를 할 수 있다.

그 뒷부분에는 3번에 대한 설명이 거의 대부분이다. 왜냐하면 많은 sequence transduction task에서 long-range dependency를 학습하는 것이 가장 중요한 challenge이기 때문이다.
(뒤의 내용은 생략하겠다)
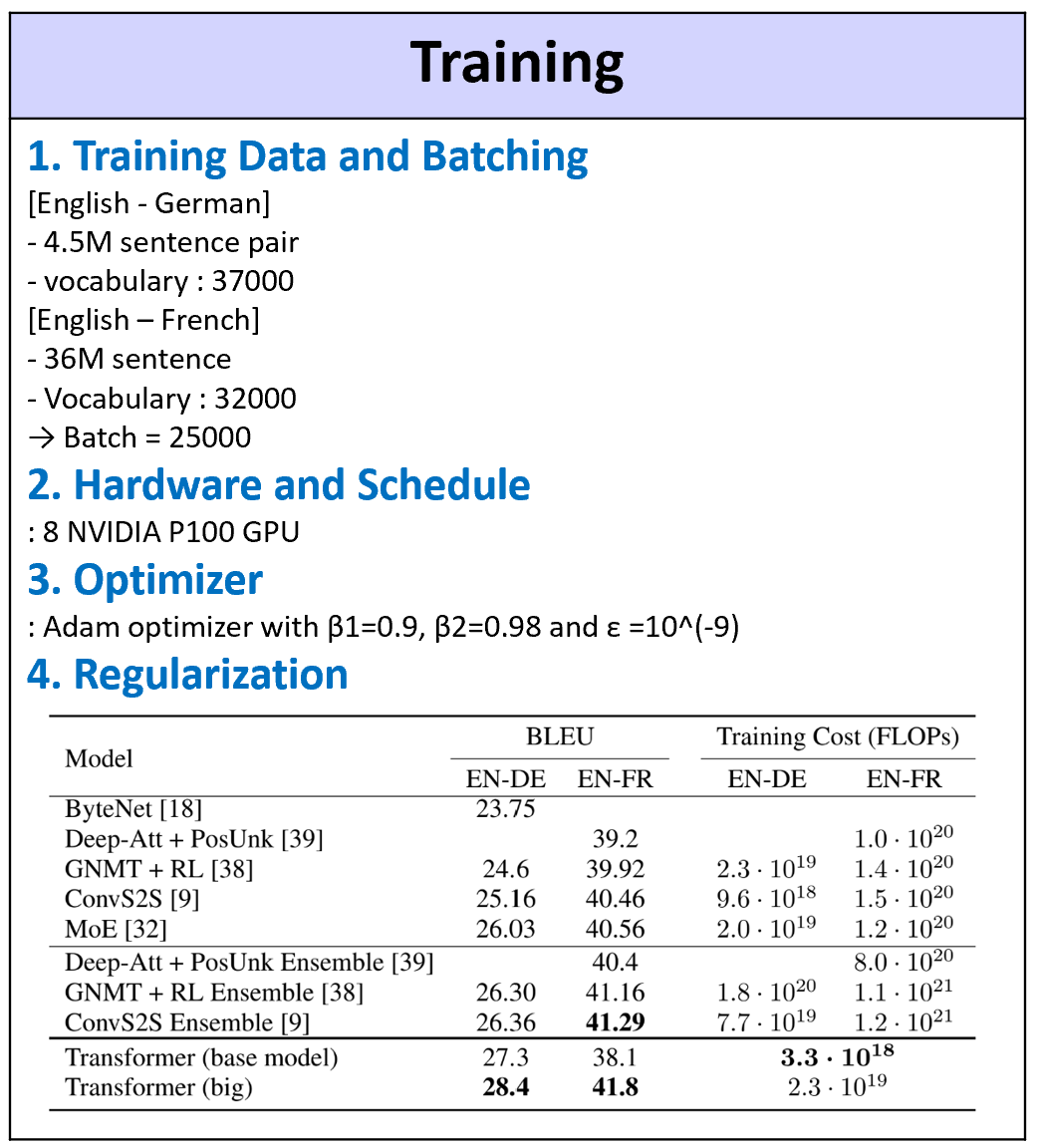
Training
Result
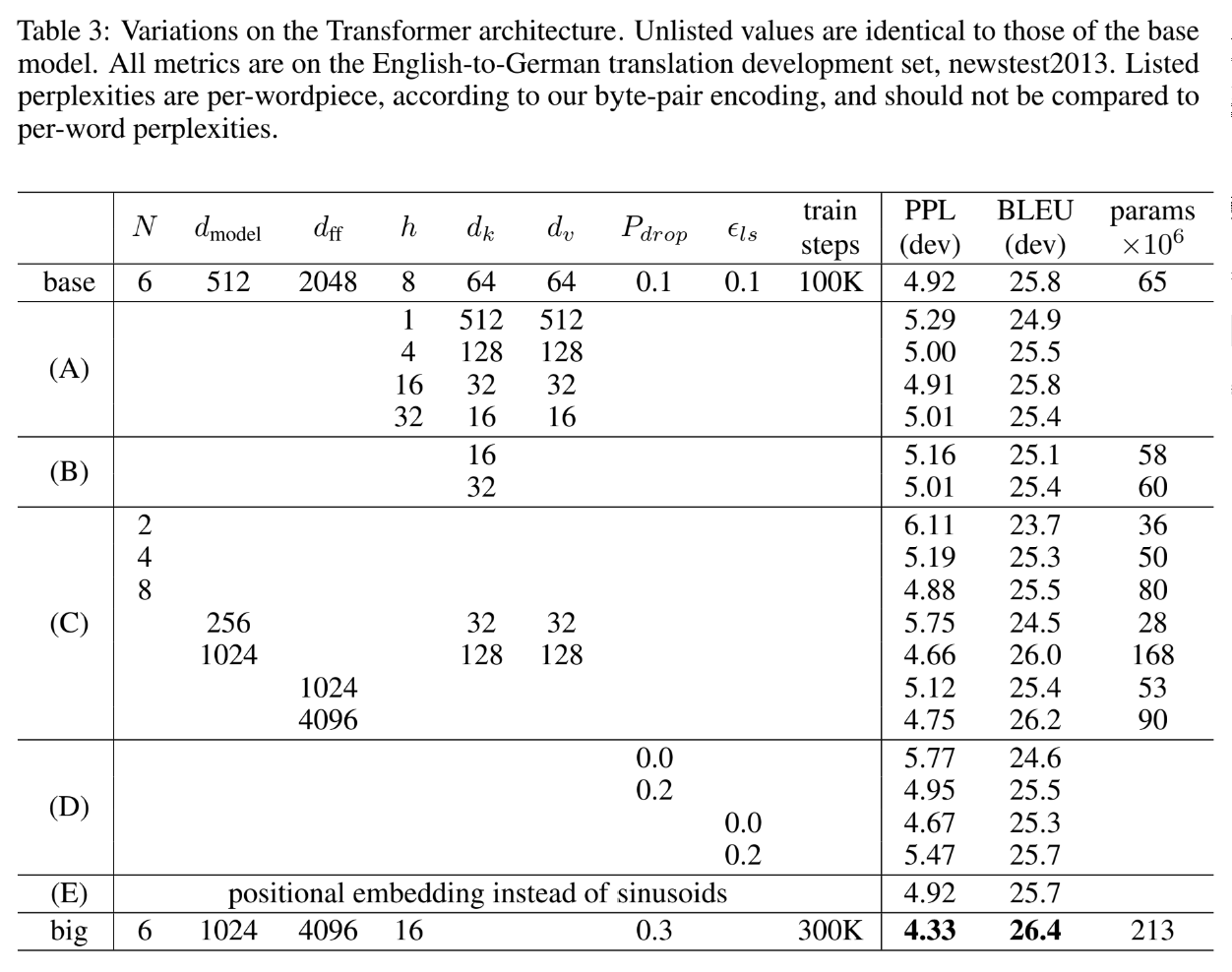
위에서 제안한 Transformer의 구조에서 몇 가지 요소들을 변경한 후 English-German translation task에 적용한 실험 결과
(A) : head의 개수, dk,dv 값 변경한 경우 : head가 너무 많으면 오히려 성능이 떨어진다.
(B) : dk 만 변경
(C) : 모델의 크기를 키운 경우 : 모델이 커지면 성능이 더 좋아진다.
(D) : dropout 의 영향 : dropout도 성능에 영향을 미친다.
(E) : positional embedding의 중요성 : learned positional embedding을 사용해도 성능에 큰 변화는 없다.
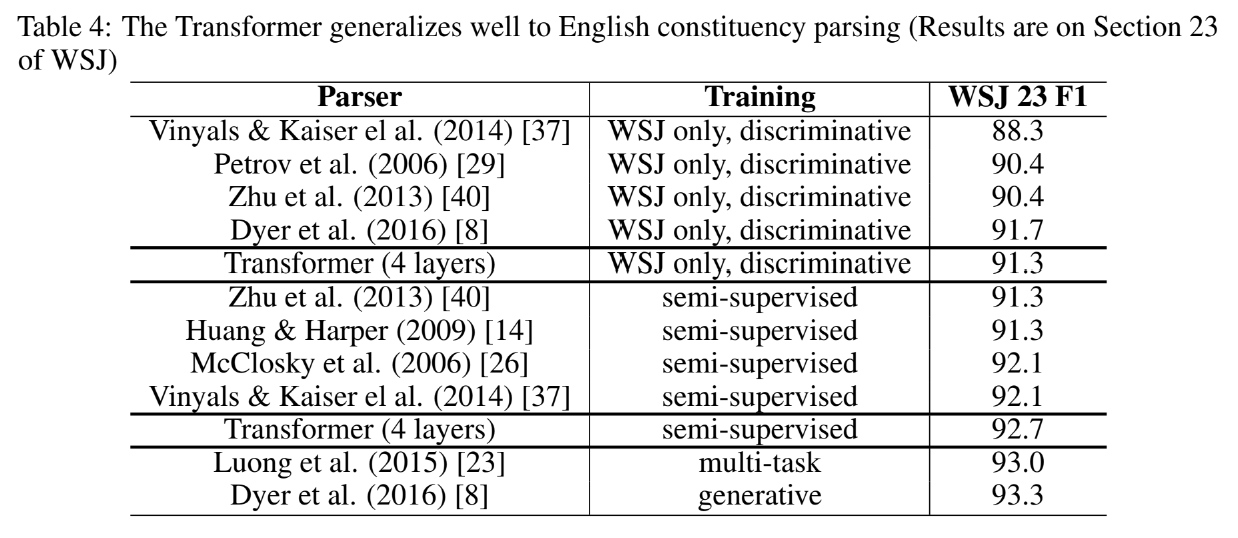
뭐 어느 논문이나 그렇듯 Attention을 적용했더니 성능이 좋아졌다 라는 것을 기록으로 증명하는 것이다.
Conclusion
이 논문을 통해 attention을 사용한 최초의 모델 Transformer를 소개했는데, 이 모델을 통해 recurrent나 convolutional layer들 보다 훨씬 빠르게 학습시킬 수 있다.
